数据准备
数据集地址:http://jse.amstat.org/datasets/normtemp.dat.txt
数据集描述:总共只有三列:体温、性别、心率
数据集详细描述:Journal of Statistics Education, V4N2:Shoemaker
体温数据描述性统计信息
import pandas as pd data_url = 'http://jse.amstat.org/datasets/normtemp.dat.txt' df = pd.read_csv(data_url,sep='s+',header=None,names=['Temperature','Gender','HeartRate']) df['Temperature'].describe() # 生成描述性统计
输出:
count 130.000000 # 数量 mean 98.249231 # 平均值 std 0.733183 # 标准差 min 96.300000 # 最小值 25% 97.800000 # 第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。 50% 98.300000 # 中位数 75% 98.700000 # 第三四分位数Q3 max 100.800000 # 最大值 Name: Temperature, dtype: float64
检验体温数据是否符合正态分布
K-S检验
from scipy import stats u = df['Temperature'].mean() std = df['Temperature'].std() stats.kstest(df['Temperature'], 'norm', (u, std))
输出:
KstestResult(statistic=0.06472685044046644, pvalue=0.6450307317439967) # statistic → D值,pvalue → P值
W检验(shapiro -wilk)
stats.shapiro(df['Temperature'])
输出:
(0.9865769743919373, 0.2331680953502655) # W → 统计数;p-value → p值
以上两种检验都是根据P值是否大于0.05确定是否为正态性,当P>0.05时,可以认为数据是呈正态分布的,小于为非正态性。
数据可视化观察是否符合正态分布
直方图:
df['Temperature'].hist(bins=80,grid=False,figsize=(10,7))
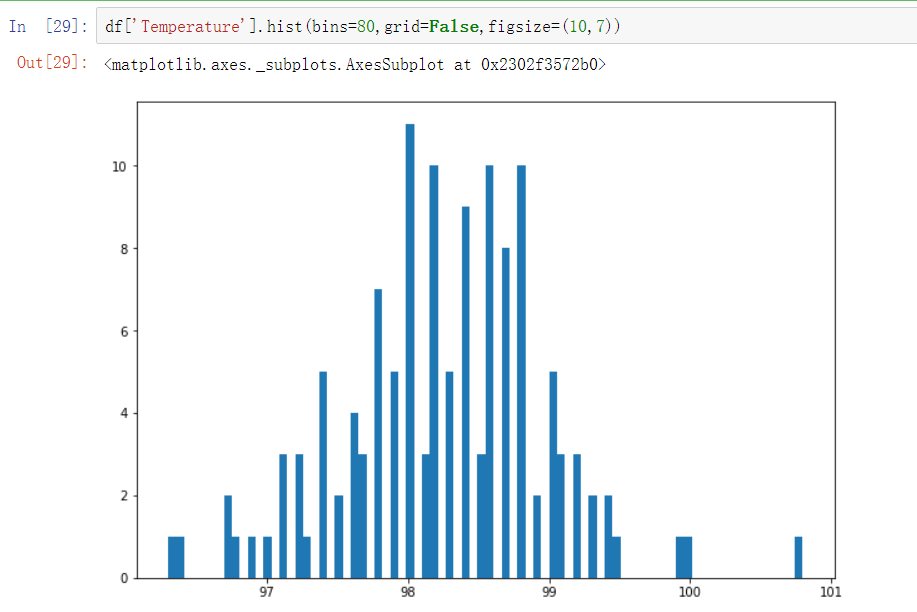
综上,体温数据是满足正态分布的。