在HOST端我们会分配block的dimension, grid的dimension。但是对应到实际的硬件是如何执行这些硬件的呢?
如下图:

lanuch kernel 执行一个grid。
一个Grid有8个block,可以有两个硬件执行单元,一个执行一个block,需要执行4次,或者像右边有4个执行单元,一共执行两次。这个就很灵活,提供啦程序的扩展性,我们在代码中可以根据具体硬件的约束来设置,提高程序的兼容性和扩展性。
在CUDA中实际执行thread的硬件我们称作Streaming multiprocessor,简称SM。 它非常类似于CPU设计的CPU内核。
Nividia GPU架构图

实际上在 nVidia 的 GPU 里,最基本的处理单元是所谓的 SP(Streaming Processor),而一颗 nVidia 的 GPU 里,会有非常多的 SP 可以同时做计算;而数个 SP 会在附加一些其他单元,一起组成一个 SM(Streaming Multiprocessor)。几个 SM 则会在组成所谓的 TPC(Texture Processing Clusters)。
在 G80/G92 的架构下,总共会有 128 个 SP,以 8 个 SP 为一组,组成 16 个 SM,再以两个 SM 为一个 TPC,共分成 8 个 TPC 来运作。而在新一代的 GT200 里,SP 则是增加到 240 个,还是以 8 个 SP 组成一个 SM,但是改成以 3 个 SM 组成一个 TPC,共 10 组 TPC。
对应到 CUDA
而在 CUDA 中,应该是没有 TPC 的那一层架构,而是只要根据 GPU 的 SM、SP 的数量和资源来调整就可以了。
如果把 CUDA 的 Grid - Block - Thread 架构对应到实际的硬件上的话,会类似对应成 GPU - Streaming Multiprocessor - Streaming Processor;一整个 Grid 会直接丢给 GPU 来执行,而 Block 大致就是对应到 SM,thread 则大致对应到 SP。当然,这个讲法并不是很精确,只是一个简单的比喻而已。
Thread分配以block为最小单位分配给SM。也就是说同一个Block里面的Thread会分配到同一个SM里来执行。 在当前的CUDA定义中,一个SM中最多分配8个blocks。
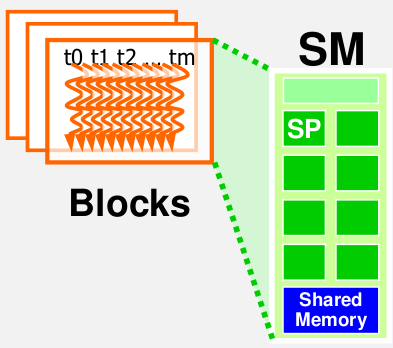
以CUDA Fermi硬件为例:
Fermi中一个SM最多分配1536Threads. 所以有下面几种Threads分配方案:
1. 256[threads] * 6[blocks], OK
2. 512[threads] * 3[blocks], OK
3. 128[threads] * 12[blocks], Bad. 受制于一个SM不能超过8个blocks.
线程调度
冯诺依曼架构是: ALU控制单元根据PC(指令计数)来提取指令,然后指令会加载到IR寄存器(指令寄存器),然后根据具体的指令,硬件会决定处理哪个单元,ALU,寄存器文件等等。然后访问内存,执行I/O操作。
SIMD操作类似与CPU的操作,不同的地方是:SIMD提取一条指令,然后同一时间里面有多个处理单元执行这同一条指令.

CUDA中,SM中具体是如何调度Thread的呢?
每个Block中的程序是以32个Thread为一个Warp为一个基本单位进行调度。每一个Warp作为一个SIMD的基本单元。这32个Threads基于各自不同的数据执行同样的指令。
举例: 假设每个block有256个threads, 每个Warp执行32个threads. 一共有3个Blocks。
256/32 = 8 * 3 = 24 warps。 一共使用啦24个warps.
所以一个SM会调度这24个warps, 但是这24个并不是都是在同一时间执行算术运算或者执行内存访问,实际上只有少数的会在硬件上执行,有很多的warps是在等待执行指令,然后硬件会挑选一部分warps去执行,剩下的warps则等待算术运算单元或者是内存资源,直到这些准备就绪。所以,在任一时间里,硬件去访问就绪warps池(类似与buffer池)。硬件会选择其中的一小部分去使用硬件资源。 在一个时钟周期里面执行一个warp不许要任何开销,然后立刻调度另一个warp,执行指令,在下一个时钟周期执行。所以说warp调度是0开销的。
Thread分配
再次以Fermi GPU 来说明。 每个SM最多分配1536个threads,如何设置block dimension
1: 8*8 : 1block = 8*8 = 64 threads,
1536/64 = 24 blocks,
24/8 =3, SM最多有8个blocks, 8*64 = 512. 所以一个SM执行512个threads
2" 16*16: 1block = 16*16 = 256 threads,
1536/256 = 6 blocks,
SM最多有8个blocks, 6*256 = 1536. 所以一个SM执行1536个threads。 完全利 用到啦SM
3: 32*32: 1block = 32*32 = 1024 threads,
1536/1024 = 1 blocks,
1*1024 = 1024. 所以一个SM执行1024个threads, 只利用到啦2/3的SM。
所以最好的还是16*16,这一种分配策略。
控制发散
在kernel 函数中条件判断是线程索引才存在控制发散问题:
If (threadIdx.x > 2) { } 存在控制发散。
If (blockIdx.x > 2) { } 不存在发散问题。
Divergence 是Warp中的一个概念,在同一个warp中有的线程走这个分支,有的线程走另外一个分支,称之为divergence.
一个Warp中的所有Thread执行同一指令。但是,由于不同Thread的数据不同,如果有基于数据的判断,就可能产生不同的结果。这时,就会产生多路径问题即发散,意味着Thread需要执行不同的指令。SM处理的方式是多次执行,每次沿着一条路径,直到所有路径都执行完毕。所以,控制发散直接关系到程序的性能。
以向量相加为例子, 长度是1000:


__global__ void vecAdd(float *in1, float *in2, float *out, int len) { //@@ Insert code to implement vector addition here int i = blockDim.x * blockIdx.x + threadIdx.x; if(i < len) out[i] = in1[i] + in2[i]; }
算下来,我们有32个warps,只有最后一个warp存在发散的问题。最后一个warp执行Threads[992 ~ 1023], 992~1000是一个分支,剩下线程执行另外一个分支。
练习题
1.处理一个600*800的图片(800是水平方向,600是垂直方向),使用kernel函数PictureKernel().m=600, n=800.
__global__ void PictureKernel(float* d_Pin, float* d_Pout, int n, int m){
int Row = blockIdx.y*blockDim.y + threadIdx.y;
// Calculate the column # of the d_Pin and d_Pout element to process
int Col = blockIdx.x*blockDim.x + threadIdx.x;
// each thread computes one element of d_Pout if in range
if ((Row < m) && (Col < n)) {
d_Pout[Row*n+Col] = 2*d_Pin[Row*n+Col];
}
}
假设grid是16*16 blocks.block是16*16 threads. 问在kernel中有多少个warps会执行.
A) 37*16. B) 38*50. C)38*8*50. D)38*50*2
解答: ceil(800/16.0) = 50, ceil(600/16.0)=38. 每个block是(16*16)/32= 8 warps.所以答案是: 38*8*50
2. 在第一个问题里面,有多少个warps有control divergence?
(A) 37 + 50*8
(B) 38*16
(C) 50
(D) 0
解答: 在一个warp中同时由线程走if和else,称之为warp control divergence.
X方向是800 = 50 * 16, Y方向是600 = 16*37.5.warp=32, 每两行是一个warp.X轴方向没有control divergence. Y方向最后一个block是0.5*16*16 = 128, 128/32= 4, 全部落在if里面.所以结果是0.选D
3.把第一题改成800*600,有多少个warps存在control divergence?
(A) 37+50*8
(B) 38*16
(C) 50*8
(D) 0
解答: x = 600/16=37.5. x方向需要补齐0.5*16=8, y=800/16=50.所以没一行右边都会补齐0.5个block_zize,即8列.所以在两行的最右边是一个block,一个block里面每两行是一个warp,而这个warp就存在一半在if,一半在els,存在control divergence, 既然每两行的最后一个warp存在control divergence,那么一共就是800/2 =400,也可以这么算:因为最右边是一直存在congtol divergence的.y方向是50个block,每个block有8哥warp,50*8 =400, 所以选C
4. 如果把图片改成是799*600(600是x方向,799是y方向),有多少个warps存在control divergence?
(A) 37+50*8
(B) (37+50)*8
(C) 50*8
(D) 0
解答: Y方向补齐1行,X方向补齐结合第三题我们可以算出y方向一共是有50*8,当然有一个重合的情况我们后面在减去.现在看X方向,一共是799行,每2行才能组成一个warp,而且最后补齐的800行处在条件else,799行处在条件if里面,这最后两行的warp是存在control divergence.一共是有608/16=38. X和Y方向重合一个,所以结果是50*8+38-1, 选A
做完这几题,对warp的调用理解更深刻了.
每个Block中的程序是以32个Thread为一个Warp为一个基本单位进行调度.Warp是block里面的概念.