一、图像识别与定位
0.Classification:C个类别
Input:Image
Output:类别标签
Evaluation metric:准确率
1.Localization:
Input:Image
Output:物体边界框(xy,w,h)
Evaluation mertric:交并准则
3.Classification+Localization:识别主题+定位
4.ImageNet:实际上有 识别+定位 2个任务
5.思路1:视作回归问题
(1)先解决简单问题,搭建一个识别图像的神经网络
(2)在AlexNet VGG GoogleLenet ResNet上fine-tun一下

(3)步骤2:在上述神经网络的尾部展开,称为classification+regresssion模式

(4)步骤3:回归部分(Regression)用欧氏距离损失;使用SGD(随机梯度下降)训练
(5)Regression(回归)的模块部分加在什么位置
最后的卷积层后;全连接层后
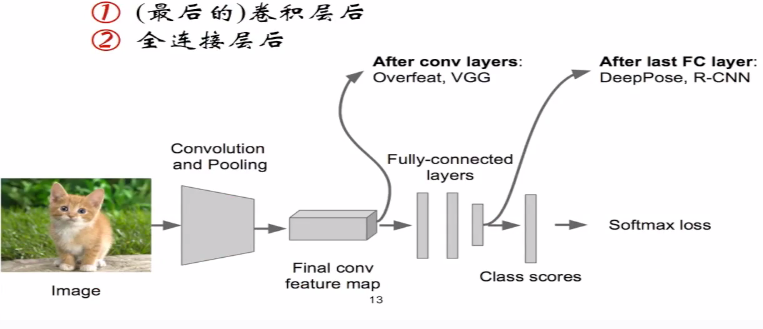
(6)能否对主体有更细致的识别呢?
提前规定好友K个组成部分;做成K个部分的回归
(7)应用:如何识别人的姿势?
每个人的组成部分是固定的;对K个组成部分(关节)做回归预测=》收尾相连的线段
(8)实际应用时
尝试各种窗口的大小;甚至会在窗口上再做一些“回归”的事情
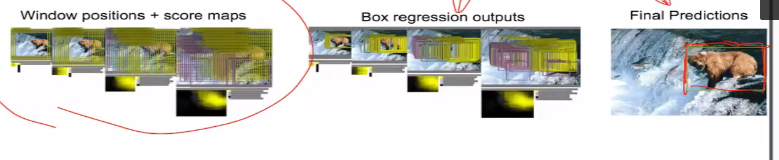


2.思路2:图窗+识别与整合
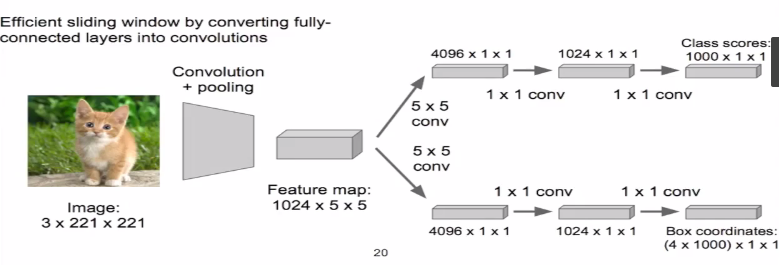
(0)想办法克服一下过程中的“参数多”与“计算慢”
测试/识别阶段的计算是可以复用的(小卷积)
加速计算
用多卷积核的卷积层替换全连接层
降低参数量
(1)类似刚才的classification+regression
(2)咱们取不同大小的“框”
(3)让框出现在不同的位置
(4)判定得分
(5)按照得分高低对结果框做抽取和合并
3.图像相关任务:
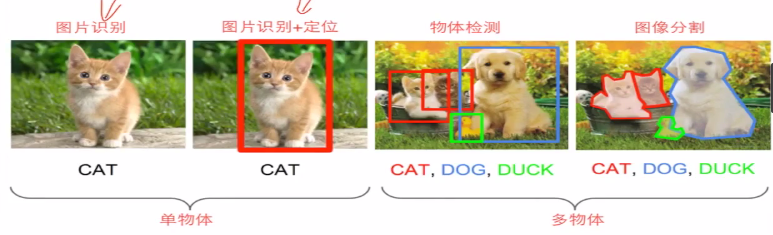
二、物体识别
1.边缘策略/选择性搜索=>R-CNN
2.R-CNN=>Fast R-CNN
3.Fast R-CNN=>Faster R-CNN
4.YOLO/SSD
三、图像分割
1.语义分割
2.反卷积