一.用户行为数据简介
1.用户行为在个性化推荐系统中分为两种:
(1)显式反馈行为:包括用户明确表示对物品喜好的行为。
(2)隐式反馈行为:不能明确反应用户喜好的行为。
(3)显式反馈行为和隐式反馈行为数据比较 
(4)反馈方向:
正反馈:用户喜欢该物品;负反馈:用户不喜欢该物品
(5)用户数据分为显性反馈和隐形反馈
(6)用户行为的统一表示 
(7)比较有代表性的数据集有以下的几个:
无上下文信息的隐性反馈数据集:每一条行为记录仅仅包含用户的ID和物品ID
无上下文信息的显性反馈数据集:每一条记录包含用户ID、物品ID以及用户对物品的评分
有上下文信息的隐性反馈数据集:包含用户ID、物品ID以及用户对物品产生行为时的时间戳
有上下文信息的显性反馈数据集,每一条记录包含用户ID,物品ID,用户对物品的评分和评分行为发生的时间戳。
二、用户行为分析:
1.用户活跃度和物品流行度分布。
(1)长尾分布: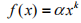
、 (2)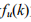 :对k个物品产生过行为的用户数;
:对k个物品产生过行为的用户数;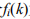 :被k个物品产生过行为的物品数,这里两个值都满足长尾分布:
:被k个物品产生过行为的物品数,这里两个值都满足长尾分布:

(3)下图展示了物品流行度分布曲线,横坐标是是物品的流行度K,纵坐标是流行度为K的物品总数。物品流行度是指对物品产生过行为的用户总数。
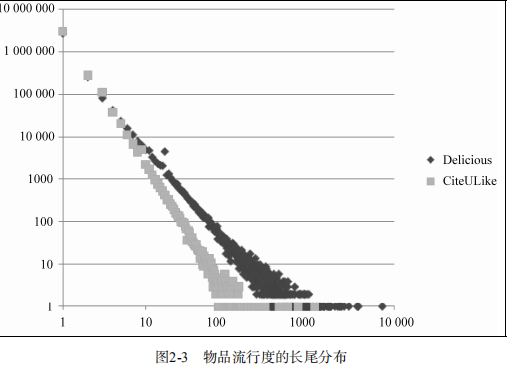
不管是物品流行度还是用户的活跃度,都近似于长尾分布
2.用户活跃度和物品流行度的关系
(1)协同过滤算法:仅仅基于用户行为数据设计的推荐算法称为协同过滤算法。
(2)基于领域的方法包含两种算法:基于用户的协同过滤算法;基于物品的协同过滤算法
(3)实验设计和算法测评
三、实验设计和算法评测:
1.评测推荐系统的方法:(1)离线实验、用户调查、在线实验
2.本节介绍离线实验评测提到的算法。
3.数据集:
(1)本节研究隐反馈数据集中的TopN推荐问题,因此忽略数据集中的评分记录,topN的任务时预测用户会不会对某部电影评分,而不是预测用户在准备对某部电影平的前提下会给电影评价多少分
4.实验设计:
(1)将用户行为数据集按照均匀分布随机分成m份(本章M=8),挑选一份为测试集,剩下的m-1份作为训练集
(2)在训练集上建立用户兴趣模型,在测试集上对用户行为进行测试,统计出相应的评测指标,为了保证评测指标并不是过拟合的结果,需要进行m次试验,并且每次将数据随机分成不同的测试集。将m次试验测出的评测指标的平均值作为最终的评测指标。
(3)每次试验选择不同的k和相同的随机数种子,进行M此试验就可以得到M个不同的测试集和训练集,然后分别进行试验
(4)用M此试验的平均值得到最后的测评指标是为了防止某次试验的结果是过拟合的结果,但是如果数据集足够大,模型足够简单,为了快速通过离线实验初步的选择算法,只能进行一次试验。
(5)对用户u推荐N个物品(Ru),令用户u在测试集上喜欢的物品集合为T(u),然后通过准确率/召回率评测推荐算法的精度:
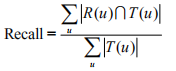 (召回率:描述有多少比例的用户-物品评分记录包含在最终的推荐列表中)
(召回率:描述有多少比例的用户-物品评分记录包含在最终的推荐列表中)
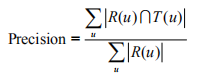 (精确率:描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录)
(精确率:描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录)
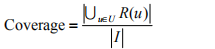 (覆盖度:最终推荐列表中包含多大比例的物品,反应了推荐算法挖掘长尾的能力,覆盖率越高,说明推荐算法越能将长尾中的物品推荐给用户)
(覆盖度:最终推荐列表中包含多大比例的物品,反应了推荐算法挖掘长尾的能力,覆盖率越高,说明推荐算法越能将长尾中的物品推荐给用户)
推荐的新颖度:推荐列表中的物品的平均流行度度量推荐结果的新颖度。如果推荐出的物品都很人们,说明推荐的新颖度很低,否则说明推荐度很新颖
四、基于邻域的算法
1.基于邻域的算法可以分为两个大类:(1)基于用户的协同过滤算法;(2)基于物品的协同过滤算法。
2.基于用户的协同过滤算法:
(1)基于用户的协同过滤算法:在一个在线推荐系统中,当一个用户A需要个性化推荐的时候,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有说过的物品推荐给A
(2)基于用户的协同过滤算法主要包括两个步骤:
(a)找到和目标用户相似兴趣的用户集合。
(b)找到这个集合中用户喜欢的,而且目标用户没听说过的物品推荐给目标用户。
(3)上述(a)中,关键是要计算两个用户的兴趣相似度,系统过滤算法主要通过行为的相似度计算兴趣的相似度:
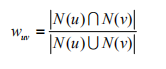
或者通过余弦相似度来进行计算:
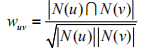
利用余弦相似度公式进行计算用户A和用户B的兴趣相似度:
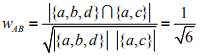
同时可以计算出用户A和用户C、D的相似度
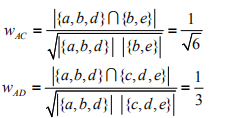
(4)在得到用户之间的兴趣相似度之后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下公式度量了UserCF算法中用户u对物品i的感兴趣程度:

其中S(u,K)包含了和用户u兴趣最为接近的K个用户,N(i)是对物品i有过行为的用户的集合,Wuv是用户u对用户v的兴趣相似度,rvi代表了用户v对物品i的兴趣,因为使用了单一行为的隐反馈数据,所以rvi=1

3.用户相似度的改进。
(1)根据用户行为计算相似度:
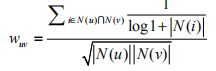
上式中,通过: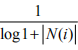 惩罚了用户u和用户v的共同兴趣列表中人们物品对他们相似度的影响。UserCF-IIF算法在各项性能上都略优于UserCF。这说明在计算用户兴趣相似度的时候,物品流行程度对提升推荐结果的质量确实有帮助。
惩罚了用户u和用户v的共同兴趣列表中人们物品对他们相似度的影响。UserCF-IIF算法在各项性能上都略优于UserCF。这说明在计算用户兴趣相似度的时候,物品流行程度对提升推荐结果的质量确实有帮助。
4.基于物品的协同过滤算法
(1)UserCF(基于用户的协同过滤算法)缺点:
随着网站用户数量增大,计算用户兴趣相似度矩阵越来越困难,运算的时间复杂度和空间复杂度的增长和用户数目的增长近似于平方关系;其次基于用户的协同过滤算法很难对推荐结果做出解释。
(2)ItemCF(基于物品的协同过滤算法):给用户推荐那些和他们之前喜欢的物品的相似物品。主要通过分析用户的行为记录来计算物品之间的相似度。
(3)算法认为:物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都喜欢物品B。基基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供解释
(4)基于物品的协同过滤算法主要分为两步:
计算物品之间的相似度
根据物品的相似度和用户的历史行为给用户推荐生成推荐列表
(5)物品相似度计算公式:分母|N(i)|是喜欢物品i的用户数,而分子|N(i)n N(j)|是同时喜欢物品i和物品j的用户数,因此下面公式可以理解为喜欢物品i的用户有多少比例的用户也喜欢物品j,Customers Who Bought This Item Also Bought,从这句话就可以定义相似度:
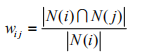
为了避免推荐出热门的商品,可以用下面的公式进行计算:
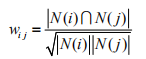
这个公式惩罚了物品j的权重,因此减轻了热门物品和许多物品相似的可能性。从定义中看出,在协同过滤中两个物品产生相似度是因为他们被很多用户所喜欢,也就是说每个用户通过他们的历史兴趣列表给物品贡献相似度。
在得到物品之间的相似度后,ItemCF通过下面公式计算用户u对一个物品j的兴趣:
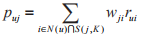
这里N(u)是用户喜欢的物品的集合, 是和物品j最相似的K个物品的集合,wji是物品j和物品i的相似度,rw是用户u对物品i的兴趣。和用户历史上感兴趣的物品越相似的物品,越有可能在用户推荐的列表中获得较高的排名。
是和物品j最相似的K个物品的集合,wji是物品j和物品i的相似度,rw是用户u对物品i的兴趣。和用户历史上感兴趣的物品越相似的物品,越有可能在用户推荐的列表中获得较高的排名。
(6)精度(准确率和召回率):可以看到ItemCF推荐结果精度也是不和K成正相关或者负相关的,因此选择合适的K对获得高精度非常重要
(7)流行度。和UserCF不同,参数K对ItemCF推荐结果流行度的影响也不是完全正相关的。随着K的增加,结果流行度会逐渐提高,但当K增加到一定程度,流行度就不会再有明显变化
(8)覆盖度:K增加会降低系统覆盖率
(9)用户活跃度对物品相似度影响
在协同过滤中,两个物品产生相似度是因为他们共同出现在很多用户的兴趣列表中。换句话数,每个用户的兴趣列表都对物品相似度产生贡献。
(10)物品相似度的归一化
5.物品相似度的归一化
(1)如果将ItemCF的相似度矩阵按照最大值归一化,可以提高推荐的准确率。如果得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w: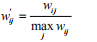
归一化不仅在于增加推荐的准确度,还可以提高推荐的覆盖率和多样性。一般来书,物品总是属于很多不同的类,每一类中物品联系比较紧密。相似度的归一化可以提高推荐的多样性。一般来说,人们类物品相似度一般比较大,如果不进行归一化,就会推荐比较热门类里面的物品,推荐的覆盖度比较低,相反如果进行相似度的归一化,则可以提高推荐系统的覆盖率。
6.UserCF和ItemCF的综合比较
(1)UserCF给用户推荐那些和他们有共同兴趣爱好的用户喜欢的物品;ItemCF给用户推荐那些和他们之前喜欢的物品的类似的物品。UserCF的推荐结果中着重反应和用户兴趣相似的小群体的热点,更加社会化,反应了用户所在的小型群体中物品的热门程度;而ItemCF的推荐结果着重于维护用户的历史兴趣,推荐更加个性化,反应了用户自己的兴趣传承。
(2)在新闻网站中,用户的兴趣不是特别细化,绝大多数用户都喜欢看热门的新闻。即使是个性
化,也是比较粗粒度的,比如有些用户喜欢体育新闻,有些喜欢社会新闻,而特别细粒度的个性
化一般是不存在的。比方说,很少有用户只看某个话题的新闻,主要是因为这个话题不可能保证
每天都有新的消息,而这个用户却是每天都要看新闻的。因此,个性化新闻推荐更加强调抓住
新闻热点,热门程度和时效性是个性化新闻推荐的重点,而个性化相对于这两点略显次要。因
此,UserCF可以给用户推荐和他有相似爱好的一群其他用户今天都在看的新闻,这样在抓住热
点和时效性的同时,保证了一定程度的个性化。这是Digg在新闻推荐中使用UserCF的最重要
原因。
UserCF适合用于新闻推荐的另一个原因是从技术角度考量的。因为作为一种物品,新闻的更
新非常快,每时每刻都有新内容出现,而ItemCF需要维护一张物品相关度的表,如果物品更新很
快,那么这张表也需要很快更新,这在技术上很难实现。绝大多数物品相关度表都只能做到一天
一次更新,这在新闻领域是不可以接受的。而UserCF只需要用户相似性表,虽然UserCF对于新
用户也需要更新相似度表,但在新闻网站中,物品的更新速度远远快于新用户的加入速度,而且
对于新用户,完全可以给他推荐最热门的新闻,因此UserCF显然是利大于弊。
但是,在图书、电子商务和电影网站,比如亚马逊、豆瓣、Netflix中,ItemCF则能极大地发
挥优势。首先,在这些网站中,用户的兴趣是比较固定和持久的。一个技术人员可能都是在购买
技术方面的书,而且他们对书的热门程度并不是那么敏感,事实上越是资深的技术人员,他们看
的书就越可能不热门。此外,这些系统中的用户大都不太需要流行度来辅助他们判断一个物品的
好坏,而是可以通过自己熟悉领域的知识自己判断物品的质量。因此,这些网站中个性化推荐的
任务是帮助用户发现和他研究领域相关的物品。因此,ItemCF算法成为了这些网站的首选算法。
此外,这些网站的物品更新速度不会特别快,一天一次更新物品相似度矩阵对它们来说不会造成
太大的损失,是可以接受的。
同时,从技术上考虑,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品
相似度矩阵。从存储的角度说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间,
同理,如果物品很多,那么维护物品相似度矩阵代价较大。
在早期的研究中,大部分研究人员都是让少量的用户对大量的物品进行评价,然后研究用
户兴趣的模式。那么,对于他们来说,因为用户很少,计算用户兴趣相似度是最快也是最简单
的方法。但在实际的互联网中,用户数目往往非常庞大,而在图书、电子商务网站中,物品的
数目则是比较少的。此外,物品的相似度相对于用户的兴趣一般比较稳定,因此使用ItemCF是
比较好的选择。当然,新闻网站是个例外,在那儿,物品的相似度变化很快,物品数目庞大,
相反用户兴趣则相对固定(都是喜欢看热门的),所以新闻网站的个性化推荐使用UserCF算法的
更多

(3)哈利波特问题。
ItemCF计算物品相似度的经典公式:
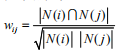
如果j非常的热门,那么上面公式得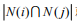 就会越来越接近
就会越来越接近 。尽管上面公式得分母已经考虑了j的流行度,但是在实际应用中,热们的j仍然会获得比较大的相似度。
。尽管上面公式得分母已经考虑了j的流行度,但是在实际应用中,热们的j仍然会获得比较大的相似度。
哈利波特问题有几种解决办法:
第一种是对分母上加大对热门物品的惩罚,比如采用下面的公式:

这里通过提高a就可以提高j
五、隐语义模型
1.基础算法
(1)核心思想:通过隐含特征联系用户兴趣和物品。
(2)隐含语义分析技术采取基于用户行为统计自动聚类。
2.LFM隐含语义分析技术在推荐系统中的应用。
(1)LFM通过如下的公式计算用户u对物品i的兴趣:
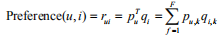
其中 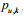 度量了用户u的兴趣和第k个隐类的关系,而
度量了用户u的兴趣和第k个隐类的关系,而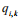
度量了第k个隐类和物品i之间的关系。
(2)负样本采样时应该遵循下面的原则。
对于每个用户,要保证正负样本的平衡(数目相似)
对于每个用户采样负样本时,要选取那些很热门的,但是用户却没有行为的物品。
一般认为