KNN思想
- 如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个级别,则该样本也属于这个级别
- 少数服从多数的原则

实现KNN算法方式
- 计算要预测的样本与空间中所有样本的距离
- 取出与当前样本距离最近的K个样本
- 统计这个K个样本中,大部分属于哪一个类别
- 大部分属于哪一个类别, 那么这个就可以预测出属于这个类别
距离测度公式
- 欧式距离,两点之间的直线距离

- 平方欧式距离
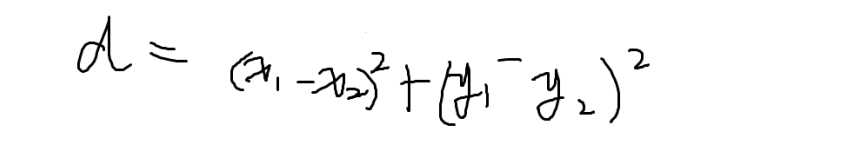
- 曼哈顿距离 没有斜路
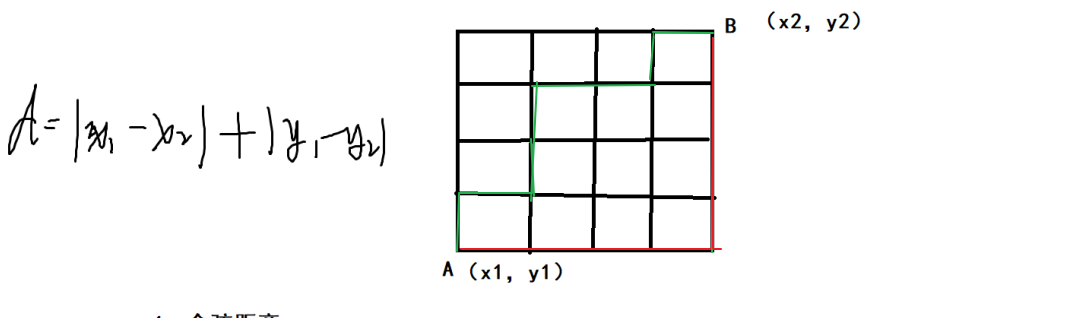
绿色和红色距离一样
- 余弦距离
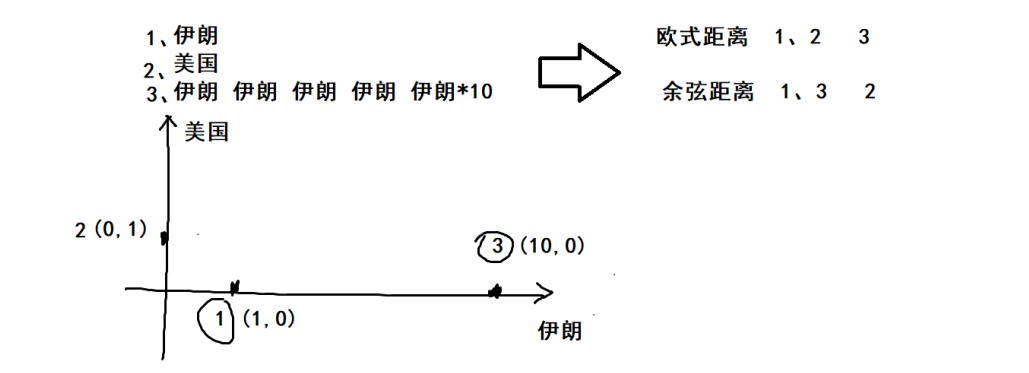
伊朗10次和1次的余弦角是0,所以一类
- 闵可夫斯基距离,对几组距离的定义
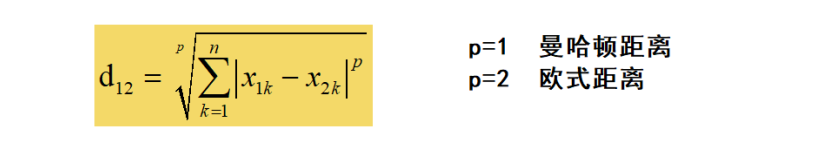

代码
import numpy as np import operator import matplotlib.pyplot as plt from array import array from matplotlib.font_manager import FontProperties def file2matrix(filePath): fr = open(filePath) # readlines:是一次性将这个文本的内容全部加载到内存中(列表) arrayOflines = fr.readlines() numOflines = len(arrayOflines) returnMat = np.zeros((numOflines, 3)) classLabelVector = [] index = 0 for line in arrayOflines: line = line.strip() print(line.split(' ')) listFromline = list(map(float, line.split(' '))) returnMat[index, :] = listFromline[0:3] classLabelVector.append(int(listFromline[-1])) index += 1 return returnMat, classLabelVector ''' 将训练集中的数据进行归一化 归一化的目的: 训练集中飞行公里数这一维度中的值是非常大,那么这个纬度值对于最终的计算结果(两点的距离)影响是非常大, 远远超过其他的两个维度对于最终结果的影响 实际约会姑娘认为这三个特征是同等重要的 下面使用最大最小值归一化的方式将训练集中的数据进行归一化 ''' def autoNorm(dataSet): # dataSet.min(0) 代表的是统计这个矩阵中每一列的最小值 返回值是一个矩阵1*3矩阵 minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals m = dataSet.shape[0] # normDataSet存储归一化后的数据 # normDataSet = np.zeros(np.shape(dataSet)) # 把最小值minVals复制m份,每份复制一次 info = np.tile(minVals, (m, 1)) normDataSet = dataSet - info # (每个值 - 最小值)矩阵 / (最大值 - 最小值)矩阵 normDataSet = normDataSet / np.tile(ranges, (m, 1)) return normDataSet, ranges, minVals # normMat第几行 i *3 # normMat_1000 所有的评级标准 # datingLables_1000 所有的好感度 def classify(normMat_i, normMat_1000, datingLables_1000, key): dataSetSize = normMat_1000.shape[0] # 求两点间的距离 diffMat = np.tile(normMat_i, (dataSetSize, 1)) - normMat_1000 sqDiffMat = diffMat ** 2 # 矩阵横着加 sqDistances = sqDiffMat.sum(axis=1) distance = sqDistances ** 0.5 sortedDistIndicies = distance.argsort() # classCount保存的K是魅力类型 V:在K个近邻中某一个类型的次数 classCount = {} for i in range(key): voteLabel = datingLables_1000[sortedDistIndicies[i]] classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] def datingClassTest(): hoRatio = 0.1 datingDataMat, datingLables = file2matrix('D:/code/python/test2/data/data_datingTestSet2.txt') # 归一化, normMat最大值减去最小值概率矩阵1000*3、ranges最大值减去最小值、minVals 最小值 normMat, ranges, minVals = autoNorm(datingDataMat) # m = 1000 numTestVecs=100 m = normMat.shape[0] numTestVecs = int(m * hoRatio) errorCount = 0.0 for i in range(numTestVecs): # normMat = 概率 = (每个值 - 最小值)矩阵 / (最大值 - 最小值)矩阵 m行 classifierResult = classify(normMat[i, :], normMat[numTestVecs:m], datingLables[numTestVecs:m], 4) print('模型预测值: %d ,真实值 : %d' % (classifierResult, datingLables[i])) if (classifierResult != datingLables[i]): errorCount += 1.0 errorRate = errorCount / float(numTestVecs) print('正确率 : %f' % (1 - errorRate)) return 1 - errorRate def classifyperson(): resultList = ['没感觉', '看起来还行', '极具魅力'] input_man = [50000, 8, 9.5] datingDataMat, datingLabels = file2matrix('D:/code/python/test2/data/data_datingTestSet2.txt') normMat, ranges, minVals = autoNorm(datingDataMat) result = classify((input_man - minVals) / ranges, normMat, datingLabels, 10) print('你即将约会的人是:', resultList[result - 1]) if __name__ == '__main__': acc = datingClassTest() if(acc > 0.9): classifyperson()