pyexecjs
在开始破解前,需要下载加载js环境的库,这样的第三方库python有许多,笔者用的是execjs可通pip直接下载
pip install pyexecjs
破解加密
爬过煎蛋网的都知道现在的原图链接都是由一串hash通过js之后编译得到的,这个编译函数可以通过查看网页源码得到函数名

接下来可以直接在谷歌开发者工具中的控制台中输入函数名得到js代码,接下来就复制js代码拿下来用就行了
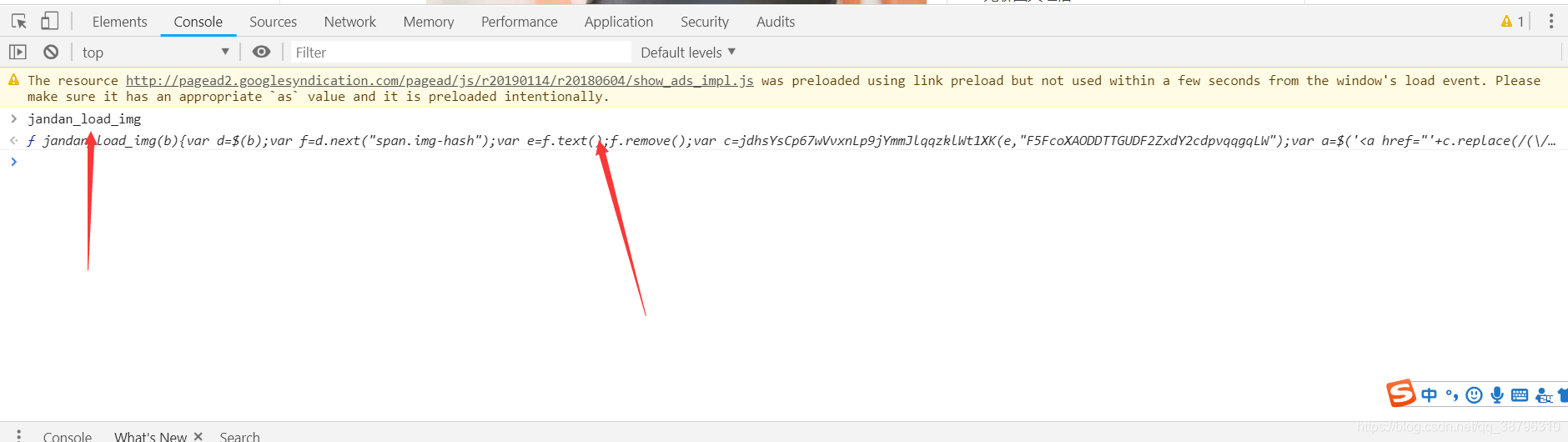
接下来附上源码
import requests
import execjs
from bs4 import BeautifulSoup
class JanDan:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
self.file = open('test.js','r',encoding='utf-8').read()#拿下来的js代码较多这里就不放出来了
self.jd = execjs.compile(self.file)#加载js代码
def get_pic(self,url):
'''下载图片'''
url = url
file_name = './'+url.split('/')[-1]
html = requests.get(url).content
with open(file_name,'wb') as f:
f.write(html)
def main(self):
for i in range(1,44):
url = 'http://jandan.net/ooxx/page-'+str(i)+'#comments'
html = requests.get(url,headers = self.headers)
html = BeautifulSoup(html.text,'lxml')
hash_code = html.find_all('span',attrs={'class':'img-hash'})#获取网页中的图片hash
for i in hash_code:
a = self.jd.call('jandan_load_img',i.text)#放置到js环境中解析
self.get_pic('http:'+a)
if __name__ == '__main__':
jandan = JanDan()
jandan.main()