本人主要做一个知识的归类与记录,如是转载类文章,居首都会备注原链接,尊重原创者,谢谢!
此文转载原链接:https://www.cnblogs.com/bianfengjie/p/9224498.html
前言:
对于一名测试人员来说,数据库的使用也是一项很基础的技能要求。因为绝大多数的应用都跟数据紧密相关,比如weixin,QQ,都需要存放大量的数据信息:联系人信息、发送的信息、朋友圈信息等等。这些信息绝大多数是存放在关系型数据库中。
因此,软件测试工程师对数据库的了解,是基本的要求。
一、数据库的本质(Mysql)
数据库的关系型数据库。
所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
1.1 RDBMS即关系数据库管理系统(Relational Database Management System)的特点
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
关于RDBMS的一些术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。(关于索引,面试问的很多)
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
1.2 数据库存储遵循范式
数据库范式(Normal forms):是用于规范关系型数据库设计,以减少谬误发生的一种准则。范式是符合某一种级别的关系模式的集合。关系数据库中的关系必须满足一定的要求,满足不同程度要求的为不同范式。
1、第一范式(1nf)
第一范式是关系型数据库的基础条件。
第一范式可以概括为:
(1)不允许出现重复的行;
(2)没有重复的列;
(3)每列(或者每个属性)都是不可再分的最小数据单元,即符合原子性,而不能是集合,数组,记录等非原子数据项;
举例子:高三(1)班的小红

这是不符合第一范式的,班级可以拆分成两个字段:年级+班级

2、第二范式(2nf)
第二范式就是任意一个字段都只依赖表中的同一个字段 ,即属性完全依赖于主键。 第二范式是指,首先满足第一范式,并且表中非主键列不存在对主键的部分依赖。

表中主键为 (学号,课程),可以看出表示所有非主键列 (成绩,课程学分)都依赖于主键。 但是,表中还存在另外一个依赖:(课程)->(课程学分)。这样非主键列 ‘课程学分‘ 依赖于部分主键列 ’课程‘, 所以上表是不满足第二范式的。
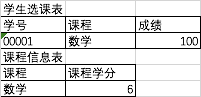
上面2个表,学生选课表主键为(学号,课程),课程信息表主键为(课程),表中所有非主键列都完全依赖主键。不仅符合第二范式,还符合第三范式。

上表中,主键为:学号,所有字段 (姓名,性别,班级,班主任)都依赖与主键,不存在对主键的部分依赖。所以是满足第二范式。
3、第三范式(3nf)
第三范式定义是,满足第二范式,并且表中的列不存在对非主键列的传递依赖,即消除对主键的传递依赖,简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
对于上面的学生信息表,虽然满足第二范式,所有字段都依赖主键(学号),但是,表中存在一个传递依赖,(学号)->(班级)->(班主任)。也就是说,(班主任)这个非主键列依赖与另外一个非主键列 (班级)。所以不符号第三范式。
学生信息表

班级信息表
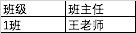
这样,对主键的传递依赖就消失了。上面的2个表都符合第3范式。
1.3 数据库数据类型的存储
1、数据库数据存储本质
数据库数据存储本质是存在磁盘里面的。
数据以磁盘块为单位存储在磁盘上。块分布于一张或多张盘片的同心环形磁道上。磁道可以在盘片的单面或双面上录制。
同一直径的所有磁道的集合称为柱面。
磁盘块的大小在磁盘初始化时可以被设置成扇区大小的倍数。
每一个记录的表面都有一个磁盘头阵列。读写一块时,磁头必须定位在块头位置。
不能并行读写的主要原因是很难保证所有磁头被精确定位在相应的磁道上。
磁盘控制器是磁盘驱动器与计算机的接口。
2、数据存储过程
存储过程可以使得对数据库的管理、以及显示关于数据库及其用户信息的工作容易得多。存储过程是 SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。存储过程存储在数据库内,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其它强大的编程功能。
存储过程可包含程序流、逻辑以及对数据库的查询。它们可以接受参数、输出参数、返回单个或多个结果集以及返回值。
可以出于任何使用 SQL 语句的目的来使用存储过程,它具有以下优点:
(1)可以在单个存储过程中执行一系列 SQL 语句。
(2)可以从自己的存储过程内引用其它存储过程,这可以简化一系列复杂语句。
(3)存储过程在创建时即在服务器上进行编译,所以执行起来比单个 SQL 语句快。
具体参考:https://blog.csdn.net/guxianga/article/details/1795619
3、存储函数
Microsoft SQL Server 2000 允许创建用户定义函数。与任何函数一样,用户定义函数是可返回值的例程。根据所返回值的类型,每个用户定义函数可分成以下三个类别:
(1)返回可更新数据表的函数
如果用户定义函数包含单个 SELECT 语句且该语句可更新,则该函数返回的表格格式结果也可以更新。
(2)返回不可更新数据表的函数
如果用户定义函数包含不止一个 SELECT 语句,或包含一个不可更新的 SELECT 语句,则该函数返回的表格格式结果也不可更新。
(3)返回标量值的函数
用户定义函数可以返回标量值。
存储过程和存储函数的区别:
(1)一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
(2)对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
(3)存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
(4)当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
4、触犯器
触发器是一种特殊类型的存储过程,不由用户直接调用。创建触发器时会对其进行定义,以便在对特定表或列作特定类型的数据修改时执行。
触发器可以查询其他表,而且可以包含复杂的 SQL 语句。 它们主要用于强制服从复杂的业务规则或要求。 例如,您可以根据客户当前的帐户状态,控制是否允许插入新订单。
触发器也可用于强制引用完整性,以便在多个表中添加、更新或删除行时,保留在这些表之间所定义的关系。
SQL Server 包括两种常规类型的触发器:数据操作语言 (DML) 触发器和数据定义语言 (DDL) 触发器。 当INSERT、UPDATE 或 DELETE 语句修改指定表或视图中的数据时,可以使用 DML 触发器。 DDL 触发器激发存储过程以响应各种 DDL 语句,这些语句主要以CREATE、ALTER 和 DROP 开头。 DDL 触发器可用于管理任务,例如审核和控制数据库操作。
通常说的触发器就是DML触发器。
DML 触发器在 INSERT、UPDATE 和 DELETE 语句上操作,并且有助于在表或视图中修改数据时强制业务规则,扩展数据完整性。
参考:https://www.cnblogs.com/yank/p/4193820.html
5、存储引擎
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
Mysql常见四种存储引擎:InnoDB、MyISAM、MEMORY、MERGE
参考:https://blog.csdn.net/qq_27028821/article/details/52267991
二、数据库操作
2.1 数据库和表结构操作
1、创建数据库和表
create database dbname 和 create table tbname
2、对表字段的增删改查
ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
在表中添加列
|
1
|
ALTER TABLE table_name ADD column_name datatype |
删除表中的列
|
1
|
ALTER TABLE table_name DROP COLUMN column_name |
改变表中列的数据类型
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
ALTER TABLE testalter_tbl MODIFY c CHAR(10) #把字段 c 的类型从 CHAR(1) 改为 CHAR(10)
|
1
|
在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。 |
|
1
|
ALTER TABLE testalter_tbl CHANGE j j INT; # 把字段 j 的类型改为int型 |
小结:1、create和drop它既操作数据库也操作表,所有你在操作的时候一定要告诉人家,你到底操作是表还是数据库
2、alter 这个关键字很特别,它在操作字段的时候也需要加table关键字
3、表数据操作
增:MySQL 表中使用 INSERT INTO SQL语句来插入数据。
|
1
2
3
|
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); |
删:可以使用 SQL 的 DELETE FROM 命令来删除 MySQL 数据表中的记录。
|
1
|
DELETE FROM table_name [WHERE Clause] |
改:需要修改或更新 MySQL 中的数据时可以使用UPDATE 命令来操作。
|
1
2
|
UPDATE table_name SET field1=new-value1, field2=new-value2[WHERE Clause] |
查:MySQL 数据库使用SQL SELECT语句来查询数据。
SELECT column_name,column_name FROM table_name [WHERE Clause]
分组:GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组,在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
参考:http://www.runoob.com/sql/sql-having.html
|
1
2
3
4
|
SELECT column_name, aggregate_function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_name; |

执行下面语句:
|
1
2
3
4
5
|
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_logINNER JOIN WebsitesON access_log.site_id=Websites.id)GROUP BY Websites.nameHAVING SUM(access_log.count) > 200; #查找总访问量大于 200 的网站 |
LIKE:SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
|
1
2
3
|
SELECT field1, field2,...fieldNFROM table_nameWHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue' |
- 可以在 WHERE 子句中指定任何条件。
- 可以在 WHERE 子句中使用LIKE子句。
- 可以使用LIKE子句代替等号 =。
- LIKE 通常与 % 一同使用,类似于一个元字符的搜索。
- 可以使用 AND 或者 OR 指定一个或多个条件。
- 可以在 DELETE 或 UPDATE 命令中使用 WHERE...LIKE 子句来指定条件。
小结: 1、表操作语句没有table关键字,因为操作就是表数据,所以不需要table关键字
2、insert into 字面意思是:往表里面插入数据,而不是从表里面获取数据,所以没有from关键字
3、delete from 表示从表中删除 一条或者多条数据,所以在删除的时候 不能加 *
4、update tbname 字面意思: 更新表 --> 不需要from 更新(update) 表(tbname) 里面的字段内容(set feildname='123') 条件在哪里(where id = 1 )
5、select * :*代表字段 从哪张表里面查询出数据 条件在where .....
6、group by 作用:主要跟HAVING联合配合聚合函数使用
4、复杂数据库查询
在数据库的查询(select),遵循的原则:一切皆表!
(1) 嵌套查询
在SQL语言中,一个 SELECT-FROM-WHERE 语句称为一个查询块。将一个查询块嵌套在另一个查询块的 WHERE 子句或 HAVING 短语的条件中的查询称为 嵌套查询。
参考:https://www.cnblogs.com/OctoptusLian/p/8183241.html
|
1
2
3
4
|
SELECT Sname /*外层查询或父查询*/FROM Student WHERE Sno IN (SELECT Sno /*内层查询或子查询*/ FROM SC WHERE Cno='2'); |
注意:
1、子查询的SELECT语句中不能使用 ORDER BY 子句,因为 ORDER BY 子句只能对最终查询结果排序。
2、在嵌套查询中,子查询的结果往往是一个集合,所以谓词 IN 是嵌套查询中最经常使用的谓词。
3、带有比较运算符的子查询是指父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是单个值时,可以用 >、<、=、>=、<=、!=、或<>等比较运算符。
|
1
2
3
4
|
SELECT Sno,CnoFROM SC X WHERE Grade >=(SELECT AVG(Grade) FROM SC y WHERE y.Sno=x.Sno); #找出每个学生超过他自己选修课程平均成绩的课程号 |
(2) 联合查询
参考:http://www.runoob.com/mysql/mysql-join.html
a、内联: 只查询出左右表链接字段相等的数据,以左表(from tbname)为基准,只要左表的数据和右表(join 表明)的数据相匹配,就能查询出来。
|
1
|
select t1.score_id,t2.id from tabname t1 (inner) join tabname2 t2 on t1.score_id = t2.id where t2.id = 10 |
b、左链接: 只查询出以左表为基准,右表不存在值,则显示为null
|
1
|
select t1.score_id,t2.id from tabname t1 left join tabname2 t2 on t1.score_id = t2.id where t2.id = 10 |
c、右链接:只查询出以右表为基准,左表不存在值,则显示为null
|
1
|
select t1.score_id,t2.id from tabname t1 right join tabname2 t2 on t1.score_id = t2.id where t2.id = 10 |
小结:1、复杂sql查询 把一个sql当做临时表的时候,一定要加一个别名
|
1
2
3
4
5
|
select * from( select * from( select t1.score_id,t2.id from tabname t1 right join tabname2 t2 on t1.score_id = t2.id where t2.id = 10 )as s left join .... where ....)as a join .... |
2、看复杂的sql:
a、select 和 from 之间永远是字段
b、from 后面永远是表
c、where 后面永远是条件
d、看懂逻辑:主要找表关系,从from后面下手
总结:
本文注意总结了测试人员需要掌握的数据库知识,其中,存储过程、存储函数、触犯器、存储引擎等了解即可,有兴趣的可深入研究。
面试经常问到的数据库的问题主要有:
1、联合查询,即内链接、左链接、右链接
2、分组:GROUP BY 和HAVING的使用
3、索引
4、常见聚合函数
5、分页sql
|
1
2
3
|
select top 50 * from pagetestwhere id not in (select top 9900 id from pagetest order by id)order by id #每页50条,198*50=9900,取第199页数据。 |
6、视图
视图的优缺点
7、主键和外键的区别