MySQL入门
mysql是目前最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。 国内淘宝网站就使用的是mysql集群
什么是数据库?
在了解关系型数据库之前我们要先了解什么是数据库
数据库简单来说就是一个存放我们的数据的地方,如果大家看电视有留意到一些档案室的话,就会知道档案室里面存放了非常多的数据,数据库的作用就跟档案室和一样的都是存放数据的,只不过我们的数据库它是把数据存放到电脑当中的,他会把所有的记录到数据当中。
总结
数据库就是一个按照数据结构来组织,存储和管理数据的仓库
mysql数据库
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
mysql特点
- mysql有开源版本和收费版本,你使用开源版本是不收费的
- mysql支持大型数据库,可以处理上千万记录的大型数据库
- Mysql使用标准的SQL数据库语言形式
- Mysql在很多系统上面都支持
- Mysql对PHP,PYTHON都有很好的支持当然其他的语言也支持比如JAVA,C
- Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统。
关系型数据库的术语
- 数据库: 数据库是关联表的集合,一个库里面可以有很多表
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
mysql安装
在学习的时候推荐大家用yum安装因为简单
yum -y install mysql mysql-server
-
安装完成后需要初始化数据库:
/etc/init.d/mysqld start
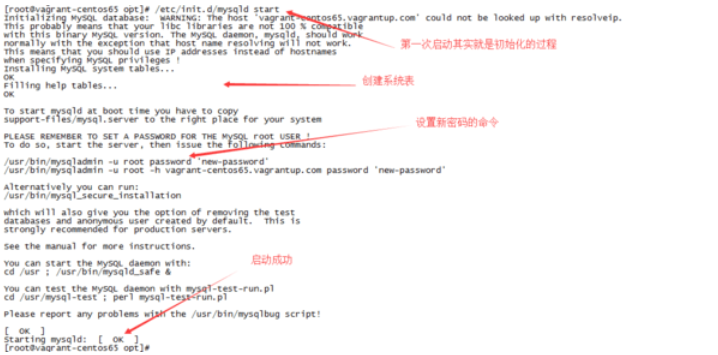
初始化成功按照提示我们开始设置密码
/usr/bin/mysqladmin -u root password 'zhiliaoawen'
- 登录mysql
登录命令:mysql -uroot -p'password'
mysql的开启和关闭
Ubuntu:
开启 service mysql start
状态 service mysql status
关闭 service mysql stop
mysql shell的使用
| 命令 | 作用 |
|---|---|
| h | 查看帮助信息 |
| show processlist; | 查看数据库的连接数 |
| status | 查看数据库的状态 |
| show databases; | 查看所有数据库的列表 |
| use 数据库名 | 进入数据库 |
mysql命令的参数
| 参数 | 含义 |
|---|---|
| -h | 主机名 |
| -u | 用户名 |
| -p | 密码 |
| -P | 端口 |
| -s | 去边框 |
| -S | 执行服务端的socket |
| -e | 在shell中执行mysql的命令 |
| -N | 去标题 |
| -H | 使用html格式导出 |
| -X | 使用XML的格式导出 |
更多选项请使用命令:
mysql --help
mysql配置文件
mysql配置文件有非常多,这边给大家看一些常用的就可以了
centos中文件路径 /etc/my.cnf
Ubuntu中文件路径 /etc/mysql/mysql.conf.d/mysqld.cnf
[client]
port = 3306 #clinet连接mysql默认的端口
socket = /tmp/mysql.sock #socket文件的位置
[mysqld]
port = 3306 #mysql开发的socket端口
socket = /tmp/mysql.sock #指定mysql.sock的文件
skip-external-locking #MySQL选项以避免外部锁定。该选项默认开启
skip-name-resolve #禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求
key_buffer_size = 16M #指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。
max_allowed_packet = 64M #接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。
table_open_cache = 512 # MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上
sort_buffer_size = 512K # MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。 如果不能,可以尝试增加sort_buffer_size变量的大小
net_buffer_length = 64K
read_buffer_size = 256K # MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小
read_rnd_buffer_size = 512K # MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大
myisam_sort_buffer_size = 8M # MyISAM设置恢复表之时使用的缓冲区的尺寸,当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区
log-bin=mysql-bin #开启binlog日志
binlog_format=mixed #开启binlog日志
server-id = 1 #表示是本机的序号为1,一般来讲就是master的意思
innodb_file_per_table=1
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
# 独立表空间优点:
# 1.每个表都有自已独立的表空间。
# 2.每个表的数据和索引都会存在自已的表空间中。
# 3.可以实现单表在不同的数据库中移动。
# 4.空间可以回收(除drop table操作处,表空不能自已回收)
# 缺点:
# 单表增加过大,如超过100G
# 结论:
# 共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整 innodb_open_files
#innodb_open_files = 500
# 限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300
innodb_file_format_check = 1
innodb_file_format=barracuda
innodb_strict_mode=1
innodb_data_home_dir = /data/mysql/data
innodb_data_file_path = ibdata1:10M:autoextend
innodb_log_group_home_dir = /data/mysql/data
innodb_buffer_pool_size = 686M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.
# 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高.
innodb_additional_mem_pool_size = 2M
innodb_log_file_size = 300M
# 此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间
innodb_log_buffer_size = 8M
# 此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间
innodb_flush_log_at_trx_commit = 2
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能
innodb_lock_wait_timeout = 50
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒
default-storage-engine=INNODB #默认存储引擎
basedir=/usr/local/services/mysql #安装路径
datadir=/data/mysql/data #mysql存放数据的目录
character-set-server = utf8 #设置数据的默认字符编码集
wait_timeout=2880000
# 服务器关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,
# 取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。参数默认值:28800秒(8小时)
# MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,
# 应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,
# 最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。
# 在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,
# 可以进行适当的调整小些。要同时设置interactive_timeout和wait_timeout才会生效。
tmp_table_size=320M #临时表空间的大小,适当的增加临时表空间可以提高链接查询速度的效果
max_connections=2048 # MySQL的最大连接数
query_cache_size=128M #MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中
join_buffer_size = 32M # 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享
expire_logs_days=1 #超过1天的binlog删除
tmpdir = /data/mysqltmp
back_log=256 # MySQL能有的连接数量,也就是说当max_connections时候,新来的请求会存在堆栈中,堆栈的数量就是back_log,如果超过back_log将会拒绝请求
thread_cache_size=32
# 这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
# 如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
# 增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)
# 根据物理内存设置规则如下:
# 1G —> 8
# 2G —> 16
# 3G —> 32
# 大于3G —> 64
[mysqldump]
quick
max_allowed_packet = 64M #服务器发送和接受的最大包长度
[mysql]
no-auto-rehash
[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout=2880000