HTTP整体概念介绍
- HTTP全名为
超文本传输协议,是在互联网上进行通信时使用的一种通信协议。 - HTTP属于
应用层协议,底层是靠TCP进行可靠地信息传输。 - 它最著名的应用是用在
浏览器的服务器间的通信。

HTTP在传输一段报文时,会以 流的形式将报文数据的内容通过 一条打开的TCP连接按序传输。TCP接到上层应用交给它的数据流之后,会按序将数据流打散成一个个的分段。再交到IP层,通过网络进行传输。另一端的接收方则相反,它们将接收到的分段按序组装好,交给上层HTTP协议进行处理。
HTTP请求过程
-
客户端连接到Web服务器:浏览器与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。 -
发送HTTP请求:通过TCP套接字,客户端向Web服务器发送一个文本的请求报文。一个请求由请求行、请求头部、空行和请求数据4部分组成。 -
服务器接受请求并返回HTTP响应:Web服务器解析请求,定位请求资源,服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。 -
释放连接TCP连接:Web服务器主动关闭TCP套接字,释放TCP连接;客户端被动关闭TCP套接字,释放TCP连接。 -
客户端浏览器解析HTML内容:客户端浏览器先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
URL
- URL描述的资源是能通过其他各种协议传送的。
- URL是可读的,所以不可打印的字符就不能在URL中使用,比如空格。
- URL是完整的,它需要支持所有语言的字符。
URI/URL/URN
URI(Uniform Resource Identifier, 统一资源标识符)表示服务器资源,URL(Uniform Resource Locator, 统一资源定位符)和URN(Uniform Resource Name, 统一资源名)是URI的具体实现。URI是一个通用的概念,由两个主要的子集URL和URN构成,URL通过位置、URN通过名字来标识资源。
URL定义了资源的位置,表示资源的实际地址,在使用URL的过程中,如果URL背后的资源发生了位置移动,访问者就找不到它了。这个时候就要用到URN了,它给定资源一个名字,无论它移动到哪里,都可以通过这个名字来访问到它。
URL通常的格式是:协议方案+服务器地址+具体的资源路径
协议方案(scheme),如http, ftp,告知web客户端怎样访问资源);服务器地址,如 www.oreilly.com; 具体的资源路径,如 index.html.

HTTP方法
HTTP支持几种不同的请求方法,每种方法对服务器要求的动作不同,如下图是几种常见的方法:

HEAD方法只获取头部,不获取数据部分。通过头部可以获取比如资源的类型(Content-Type)、资源的长度(Content-Length)这些信息。这样,客户端可以获取即将请求资源的一些情况,可以做到心中有数。
POST方法用于向服务器发送数据,常见的是提交表单;PUT用于向服务器上的资源存储数据。
HTTP状态码
每条HTTP的响应报文都会带上一个三位数字的状态码和一条解释性的“原因短语”,通知客户端本次请求的状态,帮助客户端快速理解事务处理结果。
我们平时使用浏览器的时候,很多的错误码其实是由浏览器处理的,我们感知不到。客户端可以据此状态码,决定下一步的行动(如重定向等)。
三位数字的第一位表示分类:

HTTP报文格式
HTTP报文实际上是由一行行的字符串组成的,每行字符串的末尾用
分隔,人类可以很方便的阅读。
举个简单的请求报文和响应报文的格式的例子:

实际上,请求报文也是可以有body(主体)部分的。请求报文是由 请求行(request line)、请求头部(header)、空行、请求数据四个部分组成。唯一要注意的一点就是,请求报文即使body部分是空的,请求头部后的 回车换行符也是必须要有的。
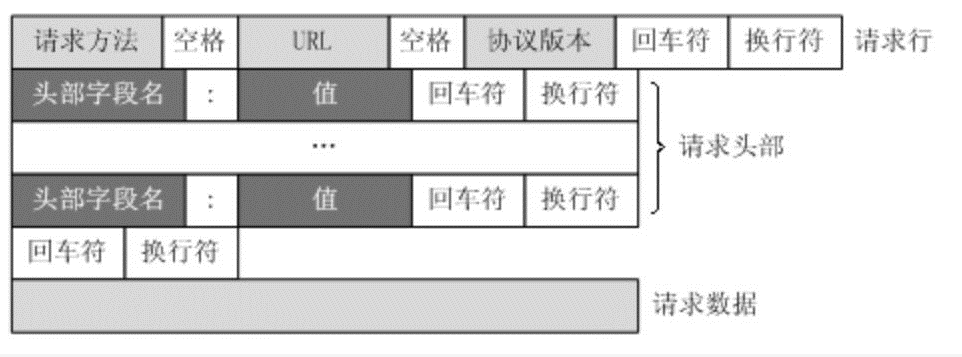
响应报文的格式和请求报文的格式类似:

请求报文、响应报文的起始行和响应头部里的字段都是文本化、结构化的。而请求body却可以包含任意二进制数据(如图片、视频、软件等),当然也可以包含文本。
有些首部是通用的,有些则是请求或者响应报文才会有的。
