继前段时间分析Redis源码一段时间之后,我即将开始接下来的一段技术学习的征程,研究的技术就是当前非常火热的Hadoop,但是一个Hadoop生态圈是非常庞大的,所以首先我的打算是挑选其中的一部分模块,去学习,研究,我就选中了MapReduce。MapReduce最早是由Google公司在04年发布的论文中提出的一种思想,后来被人实现出来,才有了后面的Hadoop的诞生。学习MapReduce的打算一定不会如Redis源码学习一样,我只会挑出其中一些用的比较多的过程分析,希望能理解的更深吧。跟上次一样,学习一门技术,首先要了解整体,所以我对Hadoop的MapReduce也做了结构分类。首先是一个图形化的标示形式,用关系类图做出的一张图:
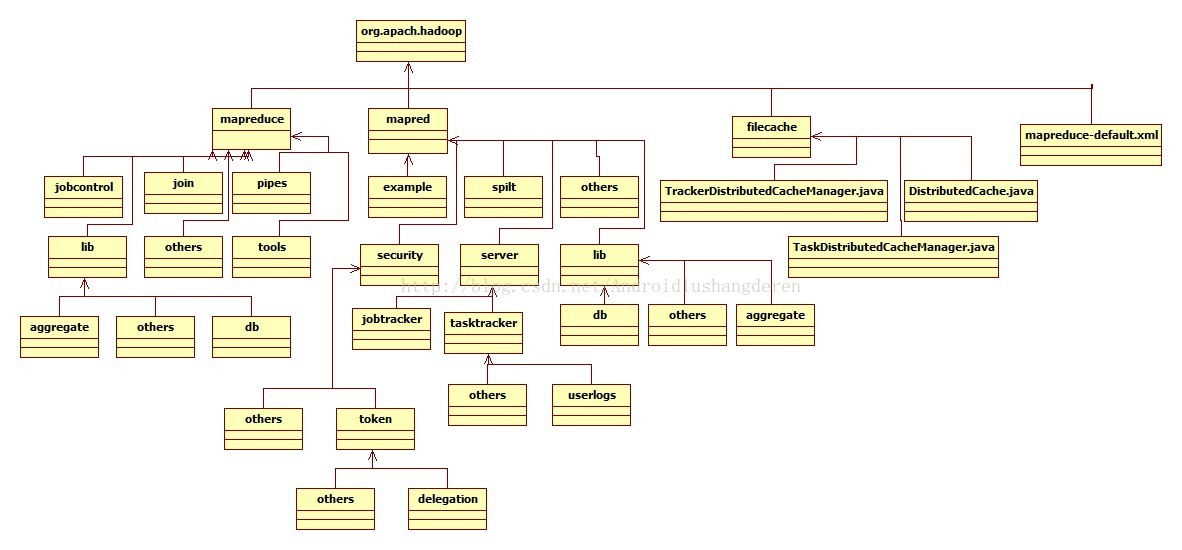
内容会比较多,下面给出我花了个把小时整理出的文字功能描述分类,结合图片和文字,理解效果会更好:
MapReduce源码分析(主要四大模块,others表示父目录下的.java文件的总称):
1.org.apache.hadoop.mapred(旧版MapReduceAPI):
(1).jobcontrol(job作业直接控制类)
(2).join:(job作业中用于模仿数据连接处理操作工具)
(3).lib(MapReduce所依赖的工具方法)
|----(1).aggregate(用于数据聚合处理的文件)
|----(2).db(数据库操作相关文件)
|----(3).others
(4).pipes(Hadoop MapReduce的C++接口代称)
(5).tools(就包含了一个MRAdmin文件,用于连接connect操作,新版本中已无此文件)
(6).others
2.org.apache.hadoop.mapreduce(新版MapReduceAPI):
(1).example(存放运行Hadoop作业的例子)
(2).lib(新版MapReduce所依赖的工具方法):
|----(1).aggregate(用于数据聚合处理的文件)
|----(2).db(数据库操作相关文件)
|----(3).others
(3).security(Hadoop1.0版本中新添加的关于安全方面的代码)
|----(1).token(用于安全检测的token验证)
| |----(1).delegation(token目录下的代理,委派token)
| |----(2).others
|----(2).others
(4).server(Hadoop服务端的功能,主要包括jobTracker,taskTracker)
|----(1).jobtracker(任务调度Tracker)
|----(2).tasktracker(任务执行Tracker)
|----(1).userlogs(任务执行的用户日志记录模块)
|----(2).others
(5).split(用于作业job的分割处理类)
(6).others
3.org.apache.hadoop.filecache(文件缓存,用于文件分发):
(1).DistributedCache.java(将job指定的文件,在job执行前,先行分发到task执行的机器上)
(2).TaskDistributedCacheManager.java(即Job ID、Job Conf即配置参数、Job配置文件路径、该Job包含的任务集合(当前TaskTracker内的)以及一些用户权限等信息)
(3).TrackerDistributedCacheManager.java(,用来管理该机器上所有task的cache文件)
4.org.apache.hadoop---mapreduce-default.xml:
主目录下的MapReduce的默认文件,包括地址端口号等的配置。
上述的所有内容都是我经过总结所得,难免会有所错误,希望大家能从整体上首先掌握MapReduce的架构体系,好逐一击破,有问题可以直接评论指出,后续我分析过的代码会定时同步到我的github上,地址: https://github.com/linyiqun