前言
Hadoop社区在HDFS-1623(High Availability Framework for HDFS NN)以及相关JIRA中对NameNode增加了高可用性的支持。但是它的实现需要依赖管理员手动切换NameNode,以此来触发NameNode的切换。这种操作方式有时会带来一些问题,比如说一个NameNode因为非主观原因导致异常,挂了,这个时候怎么办,这个时候我们可能更需要自动切换的一套机制来解决这个问题。毕竟集群管理员不会随时随地地监控着集群。基于这个应用场景,社区在HDFS-3042(Automatic failover support for NN HA)对现有HA的功能增加自动切换的支持。因为HDFS-3042是一个父JIRA,本文我们将主要关注其最后的核心子JIRA,HDFS-2185(HA: HDFS portion of ZK-based FailoverController),也就是基于ZK的自动切换原理实现,对应呈现的形式就是我们平常看到的ZKFC进程。
基于ZK的HA切换原理
在讲解ZKFC进程的组成部分之前,我们需要了解HDFS如何依赖ZK实现切换操作的。首先我们需要了解一下什么是ZK以及ZK有什么作用,然后我们才能理解HDFS为什么要利用ZK来实现自动切换的机制。
ZK全称是Zookeeper,ZK的一个很大的特点是它可以保持高度的一致性,而且它本身可以支持HA,在ZK集群最后,只要保证半数以上节点存活,ZK集群就还能对外提供服务。
那么HDFS的Active、Standby节点与ZK有什么关联呢?
当一个NameNode被成功切换为Active状态时,它会在ZK内部创建一个临时的znode,在znode中将会保留当前Active NameNode的一些信息,比如主机名等等。当Active NameNode出现失败或连接超时的情况下,监控程序会将ZK上对应的临时znode进行删除,znode的删除事件会主动触发到下一次的Active NamNode的选择。
因为ZK是具有高度一致性的,它能保证当前最多只能有一个节点能够成功创建znode,成为当前的Active Name。这也就是为什么社区会利用ZK来做HDFS HA的自动切换的原因。
HDFS HA自动切换机制的核心:ZKFC
正如本节小标图所显示的,HDFS HA自动切换机制的核心对象是ZKFC ,也就是我们平常在NameNode节点上会启动的ZKFC进程。
在ZKFC的进程内部,运行着3个对象服务:
- HealthMonitor:监控NameNode是否不可用或是进入了一个不健康的状态。
- ActiveStandbyElector:控制和监控ZK上的节点的状态。
- ZKFailoverController:协调HealMonitor和ActiveStandbyElector对象,处理它们发来的event变化事件,完成自动切换的过程。
以上3者的运行结果图如图1-1所示。
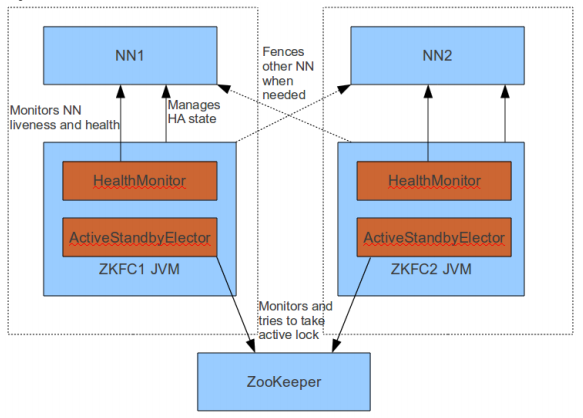
图 1-1 ZKFC组成以及运行图
接下来我们来简单介绍这3个对象服务。
HealthMonitor
首先是HealthMonitor监控服务,通过它的名称我们就能够看出它是一个监控服务。在此对象内部,定义了5种服务状态,如下代码所示:
public enum State {
// 1.The health monitor is still starting up.
INITIALIZING,
// 2.The service is not responding to health check RPCs.
SERVICE_NOT_RESPONDING,
// 3.The service is connected and healthy.
SERVICE_HEALTHY,
// 4.The service is running but unhealthy.
SERVICE_UNHEALTHY,
// 5.The health monitor itself failed unrecoverably and can
// no longer provide accurate information.
HEALTH_MONITOR_FAILED;
}翻译过来就是下面5种状态:
- 1.HealMonitor初始化启动状态。
- 2.健康检查无响应状态。
- 3.服务检测健康状态。
- 4.服务检查不健康状态。
- 5.监控服务本身失败不可用状态。
上述状态最后除去1和5的特殊情况,2、3和4的情况是HealMonitor服务队NameNode的正常检测状况。HealMonitor对象检测NameNode的健康状况的逻辑其实非常简单:发送一个RPC请求,查看是否有响应。相关代码如下:
private class MonitorDaemon extends Daemon {
private MonitorDaemon() {
super();
...
}
@Override
public void run() {
// 循环监控操作
while (shouldRun) {
try {
// 尝试连接,直到连接上为止
loopUntilConnected();
// 做一次监控检测的动作
doHealthChecks();
} catch (InterruptedException ie) {
Preconditions.checkState(!shouldRun,
"Interrupted but still supposed to run");
}
}
}
}这里继续进入doHealthChecks方法,
private void doHealthChecks() throws InterruptedException {
while (shouldRun) {
HAServiceStatus status = null;
boolean healthy = false;
try {
status = proxy.getServiceStatus();
// 调用一次监控对象的RPC方法
proxy.monitorHealth();
healthy = true;
} catch (Throwable t) {
// 如果出现异常情况
if (isHealthCheckFailedException(t)) {
...
// 进入服务不健康状态
enterState(State.SERVICE_UNHEALTHY);
} else {
...
// 进入服务无响应状态
enterState(State.SERVICE_NOT_RESPONDING);
Thread.sleep(sleepAfterDisconnectMillis);
return;
}
}
...
// 如果都正常,则是服务健康状态
if (healthy) {
enterState(State.SERVICE_HEALTHY);
}
// 进行检测间隔时间的睡眠
Thread.sleep(checkIntervalMillis);
}
}在这里我们检测出不同状态之后,会调用enterState方法,在这个方法内部会触发相应状态的回调事件。这些事件会在ZKFailoverController类中被处理。
ActiveStandbyElector
接下来是ActiveStandbyElector对象,ActiveStandbyElector对象主要负责的是与Zookeeper之间的交互操作。比如一个节点成功被切换为Active Name,ActiveStandbyElector对象会在ZK上创建一个节点。在这个类最后,有2个涉及到Active Name选举的关键方法:joinElection()和quitElection()方法。
joinElection方法被调用表明本地的NameNode准备参与Active NameNode的选举,为一个备选节点。quitElection方法被调用表示的是本地节点退出本次的选举。
这2个方法会在HDFS HA自动切换最后被调用。显然quitElection方法会在原Active NameNode所在节点中被调用。
在joinElection参加选举的方法中,会执行在ZK上创建临时znode的方法,代码如下:
private void joinElectionInternal() {
...
createRetryCount = 0;
wantToBeInElection = true;
createLockNodeAsync();
}creareLockNodeAsync方法如下:
private void createLockNodeAsync() {
// 调用zk客户端方法创建临时znode
zkClient.create(zkLockFilePath, appData, zkAcl, CreateMode.EPHEMERAL,
this, zkClient);
}在quitElection退出选举之后,这个临时节点会被删除,相关代码如下:
public synchronized void quitElection(boolean needFence) {
LOG.info("Yielding from election");
if (!needFence && state == State.ACTIVE) {
// 如果当前NameNode从Active状态变为Standby状态,则删除临时znode
tryDeleteOwnBreadCrumbNode();
}
reset();
wantToBeInElection = false;
}当然,在ActiveStandbyElector类中还有其它涉及ZK操作的方法,大家可以自行阅读此对象进行更加深入地学习。
ZKFailoverController
最后是ZKFailoverController控制器类,这个对象类包含并协调以上2个对象类的操作。首先来看此对象类的定义,代码如下:
public abstract class ZKFailoverController {
...
// 服务目标对象
protected final HAServiceTarget localTarget;
// NameNode健康监控服务
private HealthMonitor healthMonitor;
// ZK交互协调器
private ActiveStandbyElector elector;
protected ZKFCRpcServer rpcServer;
...然后我们再来看HealthMonitor 、ActiveStandbyElector 的初始化。
首先是HealthMonitor 对象,
private void initHM() {
// HealthMonitor对象的初始化
healthMonitor = new HealthMonitor(conf, localTarget);
// 加入回调操作对象,以此不同的状态变化可以触发这些回调的执行
healthMonitor.addCallback(new HealthCallbacks());
healthMonitor.addServiceStateCallback(new ServiceStateCallBacks());
healthMonitor.start();
}在之前分析的HealthMonitor类中的enterState方法中会触发这些回调的执行,我们以ServiceStateCallBacks回调为例,来看看里面具体会执行哪些操作。
class ServiceStateCallBacks implements HealthMonitor.ServiceStateCallback {
@Override
public void reportServiceStatus(HAServiceStatus status) {
// 传入当前检测出的健康状态进行检查
verifyChangedServiceState(status.getState());
}
}继续进入此方法,
void verifyChangedServiceState(HAServiceState changedState) {
synchronized (elector) {
synchronized (this) {
// 如果服务状态为初始化状态
if (serviceState == HAServiceState.INITIALIZING) {
if (quitElectionOnBadState) {
LOG.debug("rechecking for electability from bad state");
recheckElectability();
}
// 重新检测方法完毕并返回
return;
}
...
// 因为当前报告的状态与期望状态不匹配,退出选举
LOG.error("Local service " + localTarget
+ " has changed the serviceState to " + changedState
+ ". Expected was " + serviceState
+ ". Quitting election marking fencing necessary.");
delayJoiningUntilNanotime = System.nanoTime()
+ TimeUnit.MILLISECONDS.toNanos(1000);
elector.quitElection(true);
quitElectionOnBadState = true;
...
}
}
}在recheckElectability方法中,会根据最近一次检测出的健康状态,做对应的处理动作,代码如下:
private void recheckElectability() {
// Maintain lock ordering of elector -> ZKFC
synchronized (elector) {
synchronized (this) {
boolean healthy = lastHealthState == State.SERVICE_HEALTHY;
...
// 根据最近一次的健康状态,调用ActiveStandbyElector的相关方法
switch (lastHealthState) {
case SERVICE_HEALTHY:
// 如果当前状态为健康,则加入此轮选举
elector.joinElection(targetToData(localTarget));
if (quitElectionOnBadState) {
quitElectionOnBadState = false;
}
break;
case INITIALIZING:
LOG.info("Ensuring that " + localTarget + " does not " +
"participate in active master election");
// 如果当前处于初始化状态,则暂时不加入选举
elector.quitElection(false);
serviceState = HAServiceState.INITIALIZING;
break;
case SERVICE_UNHEALTHY:
case SERVICE_NOT_RESPONDING:
// 如果当前状态为不健康或无响应状态,则退出选择
LOG.info("Quitting master election for " + localTarget +
" and marking that fencing is necessary");
elector.quitElection(true);
serviceState = HAServiceState.INITIALIZING;
break;
case HEALTH_MONITOR_FAILED:
fatalError("Health monitor failed!");
break;
default:
throw new IllegalArgumentException("Unhandled state:"
+ lastHealthState);
}
}
}
}在上面的操作中,就调用到了ActiveStandbyElector的内部方法。在这里我们可以看到,当当前NameNode的健康检测状态为SERVICE_UNHEALTHY和SERVICE_NOT_RESPONDING时,会触发到quitElection方法,从而使自身暂时退出Active状态。
说了这么多关于ZKFailoverController的内容,可能有人会感觉奇怪,我们启动的ZKFC进程好像并不叫这个名称啊?没错,在NameNode,我们实际启动的是它的一个继承子类:DFSZKFailoverController。此类的绝大多数方法走的还是其父类的方法。
综上所述,ZKFC类对象内部的结构关系图如图1-2所示。
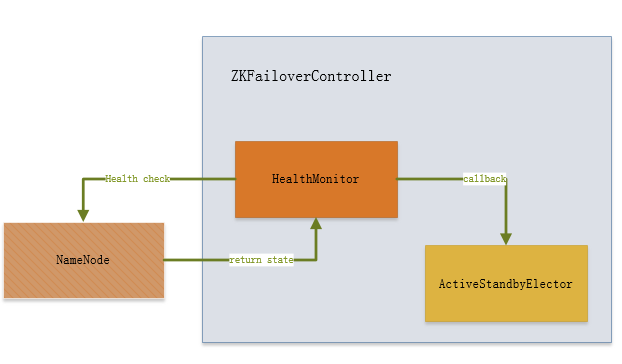
图 1-2 ZKFC内部结构图
OK,本文所要阐述的内容就是如此,更多关于HDFS ZKFC自动切换原理的细节内容可以点击文章末尾的链接进行学习。
参考资料
[1].High Availability Framework for HDFS NN
[2].Automatic failover support for NN HA
[3].HA: HDFS portion of ZK-based FailoverController
[4].zkfc-design