前言
现在稍微具有一定规模的涉及到大数据存储的公司,或多或少都会使用到HDFS作为其数据的存储系统。在不同的公司企业内,不同的应用需求对应会构建出不同级别规模的集群,小则几十台,大则成千上万个节点。当然很多时候,我们的集群规模一般不是一蹴而就就达到一个相当大的规模,在前期的时候往往都是由小集群开始的。随后,再不断不断地进行扩容,扩张。随着集群规模的扩展,运维人员会碰到各种针对那时规模的各种问题(可能需要参数调整等等类似这种)。其实这个时候,我们自然会想到是否我们会有一个性能测试工具来测试扩展好的集群性能呢,以此帮助我们在真正实施集群规模扩展时发现这类的隐蔽问题。本文笔者来阐述Linkedin目前开源的一个HDFS性能扩展测试工具:Dynamometer.。它旨在以最小的硬件资源来模拟真实的集群效果,以此做相应的性能测试。
HDFS扩展性测试的适用场景
看到这里,可能有些人会有疑问了,我在测试集群搭上一个小集群来模拟测试效果,不也是一样的吗,为什么要完全模拟生产集群的效果呢?
其实小规模环境往往只能验证出功能测试效果,而对于潜在的performance的测试往往是不够的,所以我们着重想要模拟出尽可能模拟真实的测试效果。接近真实的测试环境至少能够帮助我们在以下几种情境下模拟出效果:
- 压力测试下的集群性能情况
- 对代码逻辑变更后的回归性能测试
- 系统版本升级后的性能测试
- 参数配置优化后的性能测试对比
以上四类测试场景将会是十分适用于我们的模拟测试场景的。
Dynamometer:以最少的硬件资源模拟最逼真的HDFS集群效果
下面我们来正式切入开始今天的内容。因为今天的测试工具主要是针对HDFS的,所以我们先来简单了解HDFS集群的处理流程。
在HDFS中,我们说集群的性能好坏大部分情况指的是其中心节点NN的性能清况,而这个NN则会有来自于多方面的处理压力,主要包含以下3块:
- DN的管理(块上报等等)
- 客户端请求操作
- 文件元数据的管理
以上所有的操作都会涉及到NN的交互,如下图所示:
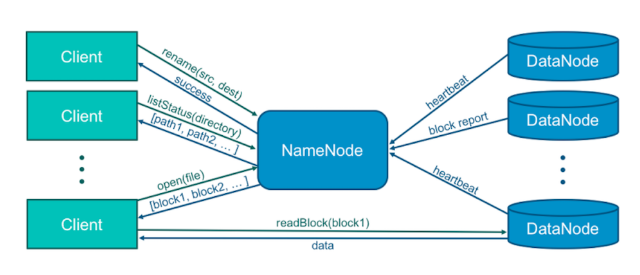
因此如果说我们想模拟出最真实的workload,可以从这3方面逐一进行:
第一点,模拟足够多的DN。
第二点,模拟出足够多的客户端request。
第三点,在NN中造成足够多的元数据,但是这些元数据对应的实际物理数据我们并不需要保存在DN内。
Dynamometer的内部实现细节
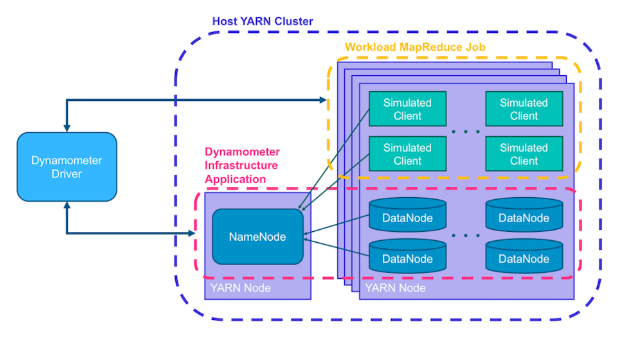
了解完Dynamometer的整体概况后,我们再看细看里面的具体实现思路。如上文前面提到的,完全用物理硬件资源来模拟真实生产环境是需要昂贵的成本代价的,而Dynamometer在这里其实是把这个集群做成了一个YARN Application,然后在Container里面分别启动NN和DN。因为YARN Application的使用资源可以根据实际需要动态进行调整,所以扩展性比较灵活。
为了模拟最真实的效果,Dynamometer拷贝实际的fsimage文件在Container中来启动NN,对于多DN的模拟,Dynamometer允许在一个节点上开启多个DN进程,从YARN Application层面理解,就是在节点上启动多个Container,然后每个Container里面启动的是DN。这些DN向NN Container进行汇报。注意,这里的DN使用的是SimulatedFSDataset,并不保存实际物理数据。
对于实际的请求,Dynamometer也设计了额外的应用来模拟workload。这种应用的原理是解析输入的audit log文件,然后创建客户端进行对应的请求发送。鉴于有些解析后的请求需要有顺序的要求(比如create dir after list),这里会对audit记录按照IP地址进行partition的区分。这里模拟workload的应用也是一个YARN Application。
下面是其内部的细节图:
鉴于Dynamometer有很好的测试使用场景,目前社区也有在把这个工具合入hadoop tools的计划,相关JIRA::HDFS-12345:Scale testing HDFS NameNode with real metadata and workloads (Dynamometer)