文章目录
前言
熟悉了解并使用过Hadoop HDFS作为中心数据存储的同学,一定在过去或多或少地遇到过HDFS的扩展性问题,准确来说应该是HDFS NN的扩展性问题。尽管说HDFS在后面引入了诸如HDFS federation之类的方案,但这只是指标不治本。在上层进行了横向扩展。于是乎,后来Hadoop社区设计实现了Ozone系统,从根本上解决HDFS的扩展性问题,官方宣称是可支持数十亿级别的元数据的存储。Ozone目前正在快速的开发迭代过程中,很多功能也在逐渐完善。本文要讨论的一个中的关键话题:假设Ozone发布了一个相对稳定的版本,我们如何将数据从HDFS模式upgrade到Ozone里呢?今天笔者结合社区对此的方案设计,来做个简单的阐述。同时也让大家从另外的层面了解了解HDFS,Ozone这两套存储系统在一些细小方面的异同。
HDFS Upgrade到Ozone的目标
我们首先要明确一个大的目标,因为后面具体谈论的Upgrade的细节都是为达成此目标服务的。
第一点,我们要知道这是2套设计完全不同的存储系统。Ozone作为后开发设计出的系统,在设计之初是为了定位并解决HDFS暴露出的扩展性问题。但是鉴于二者系统元数据结果的不同,在升级过程中会存在元数据mapping的过程。因为我们只需要做上层元数据mapping的改造,实质上我们无需进行实际的数据拷贝工作。所以这里其实是一种被称为In-Place的原地升级的操作。
因此我们暂且列出一下几点要求:
- Upgrade过程中尽可能最小化HDFS downtime时间,使得HDFS依然能够对外提供服务。
- 能够支持局部HDFS path的Upgrade操作,因为可能我们只会Upgrade那些元数据特别多(比如小文件特别多)的目录.
- 支持HDFS path到Ozone path的映射规则,因为Ozone采用的是/Volume/Bucket/Key的key,名称形式,所以这里其实会有多种映射规则。比如粗粒度的一点会是一个HDFS root目录映射到一个Ozone的大bucket下。
- Upgrade过程对于用户应该是无感知的。
当然我们说上面的目标并不都是必须要达成,比如要想真正做到对用户任务运行无感知,还是有很多工作需要去做的。
Upgrade难点:HDFS到Ozone的元数据的映射
因为两大系统间的Upgrade是无需有实际数据的迁移,我们只是在metadata层进行元数据的mapping转换。转换完毕,并重启Ozone服务,即意味着Upgrade过程的完成。
要说到元数据的mapping计划,这里就不得不提及到二者元数据的组织关系了。
HDFS和Ozone的元数据构造
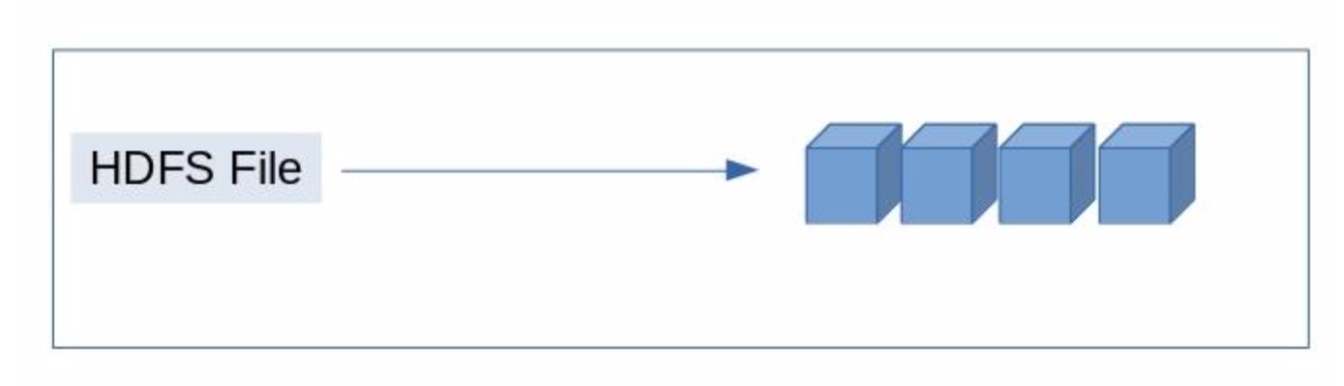
HDFS内部的元数据构成情况,相信大家都已是耳熟能详的了,简单来说是一个文件块会映射到多个block块组成,如下图所示。
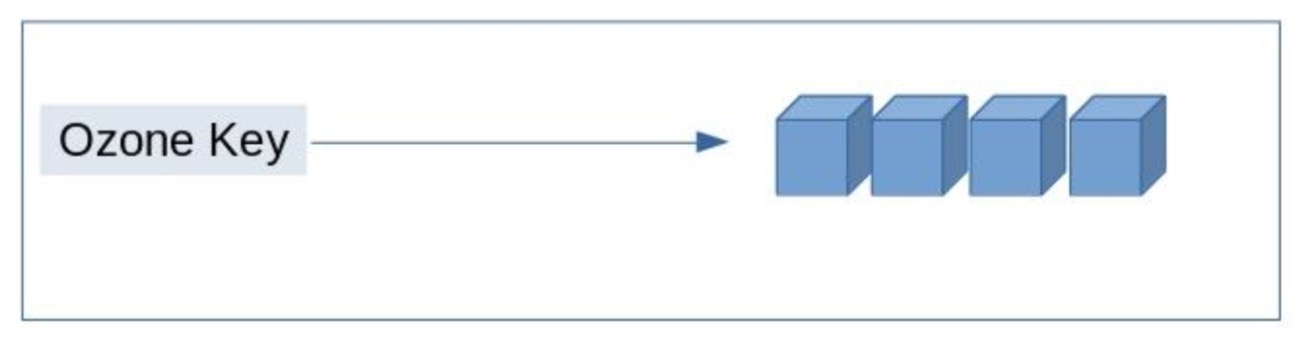
在Ozone中,同样存在block的概念,不过这里所谓的file在Ozone中称为一个Key,所以存储的形式在Ozone中变成了,1个Key对于于多个block,如下图。
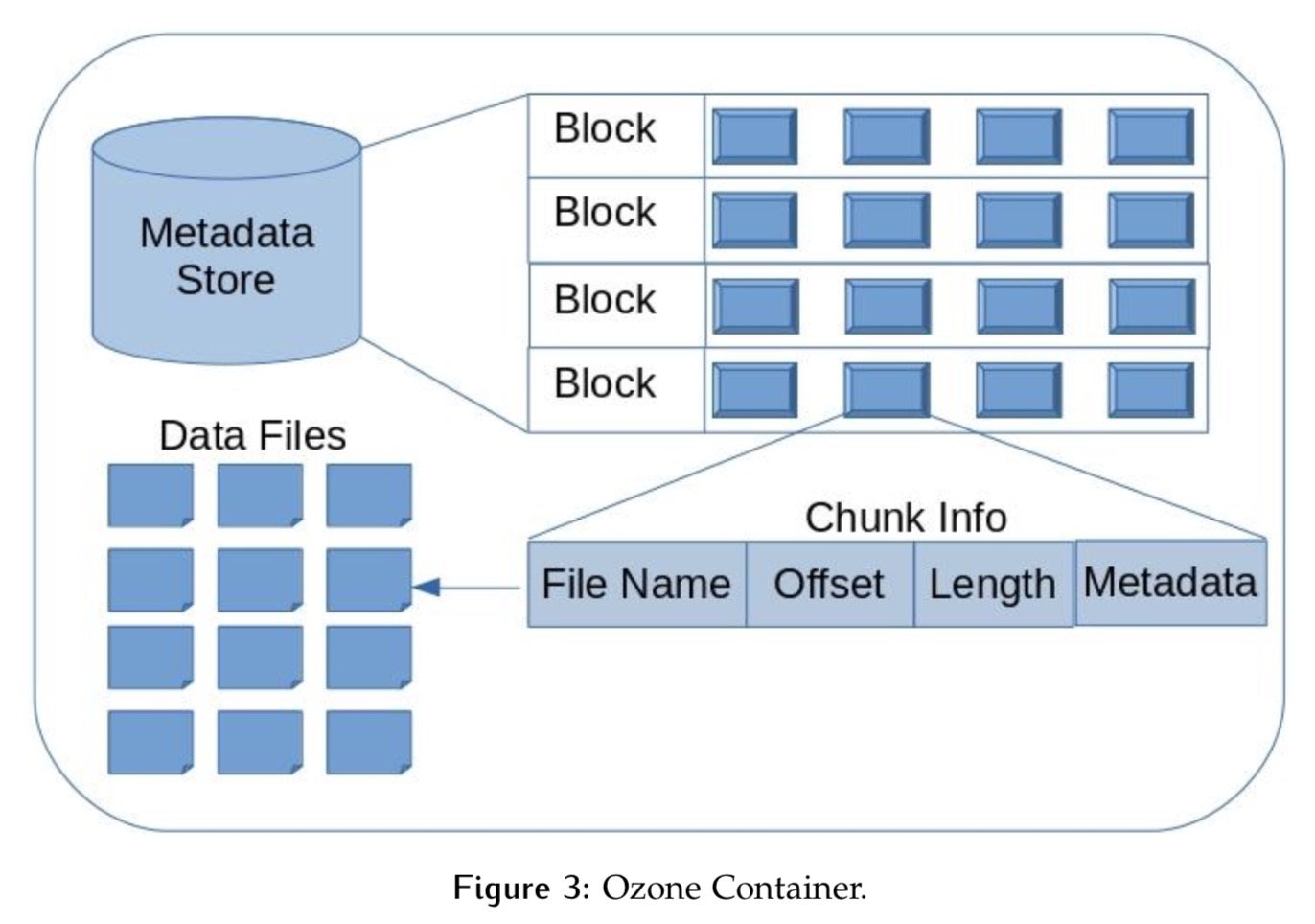
不过Ozone为了避免管理block所带来的类似HDFS的扩展性问题,在block之上建立了HDDS层,即Container层。所有的block是从这个Container中分出去的,Container的结构定义如下:
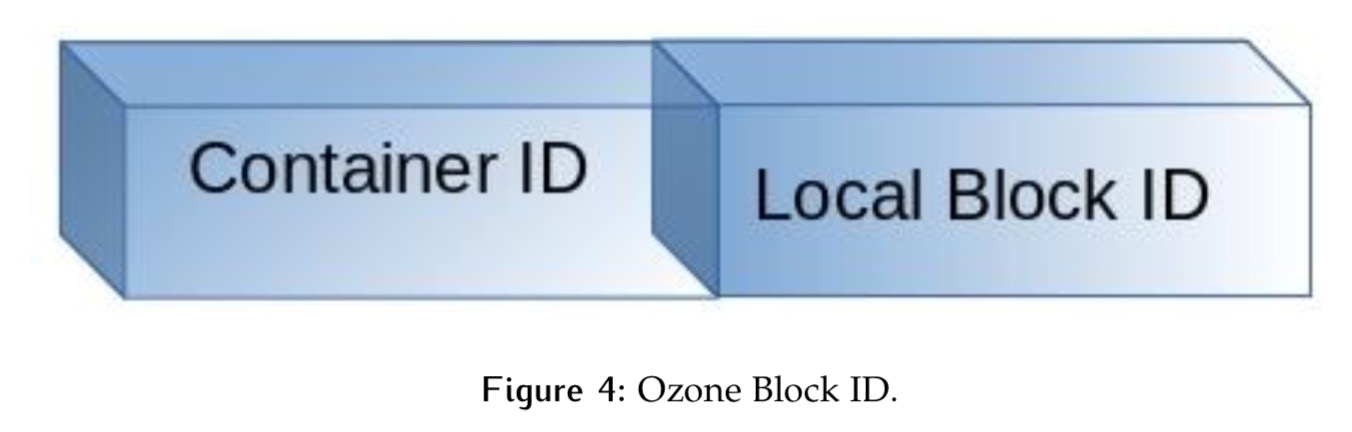
于是在Ozone中,新的blockId将变为ContainerID+localId的如下形式,前者确定block节点位置,后者在Container容器中unique存在。
所以说,这里要做的主要映射工作在于说是把HDFS的block数据一一对应到Ozone的block数据,这里面包括有:
- HDFS block数据的文件名对应到Ozone的哪个key名称
- HDFS block的对应到Ozone的哪个Container下以及此Container下的新blockId是怎样的
HDFS block到Ozone block的映射
OK,此处笔者来详细聊聊这里的映射方案。
因为整个Upgrade过程是无实际数据拷贝的,也就是说一种绝对理想情况是:HDFS的block自动创建一个只隶属于其自身的Container。因为Ozone中是以Container为单位进行replication的,则恰好在block所在的节点上创建此Container的replica。
上述映射规则虽然简单,但并未达到实际Ozone期望的效果。绝对完美情况下,一个Container大小5GB,按照标准128MB一个快的存储,它能容纳40个block块。而现在是1:1的比例,Container元数据依然过多。
所以在这里我们提出的一个原则是:尽肯能复用那些共享存储节点的block数据,然后把它们分入一个Container之内。
举个简单的例子,假设有以下3个block块,共3x3=9个副本块
block1分布在DN1,DN2
| blockid | 存储节点 |
|---|---|
| block1 | {DN1, DN2, DN3} |
| block2 | {DN1, DN2, DN4} |
| block3 | {DN1, DN2, DN3} |
在这里我们其实其实就只要创建2个Container就足够了,因为blcok1和block3是完全共享存储节点的。用比较学术的名词来称呼副本块所处的节点列表为Replica Set。但同时我们注意到,block2页只有一个replica的位置和block1不同,如果我们能将block2在DN4上的副本搬运到DN3上,那不就可以完全共享1个Container了。
因此在这里,我们可以通过一种重分布block数据的方式进一步提高单位Container的block密度值,以此缩小Upgrade后元数据的量级,HDFS Balancer工具会是一个不错的选择工具。
经过上述映射过后,我们会得到一组映射表,如下所示:
| HDFS Block ID | ReplicaSetID | Ozone/HDDS block ID |
|---|---|---|
| Block200 | RID : DN1, DN2, DN3 | CID:blockID (CID:1, LID:1) |
| … | … | … |
然后我们将这组mapping数据保存到db表里之后,后面就是关键的Ozone服务的启动过程了。
Ozone的数据重构建
基于映射mapping表,Ozone的相关服务启动后读取映射数据并在对应DN上创建出对应Container以及block信息,这里block的数据文件无需进行物理拷贝,系统只需进行hard link的方式创建即可。
以上即是HDFS数据In-Place Upgrade到Ozone的方案原型设计,由于篇幅有限,省略了其中许多的细节部分,感兴趣的同学可阅读原JIRA下的文档。
引用
[1].https://issues.apache.org/jira/browse/HDDS-1266. [Ozone upgrade] Support Upgrading HDFS clusters to use Ozone