前言
在分布式存储系统中,数据往往通过以副本的形式来保持其冗余性。因为存储的集群规模大到一定程度,每天有若干节点挂掉是很常见的现象,单副本数据显然会存在高概率丢数据的情况的。那么这里有一个问题,当存储节点挂掉的时候,系统如何再次让数据保持和原先一样的冗余度呢?本文笔者结合HDFS块副本的情况来聊聊这个话题,这个处理过程在大多存储系统中想必也是通用的。
HDFS块状态类型
在这里先简单说说HDFS中一个block块的状态类型,有以下几种类型:
- InvalidateReplica,无效副本块,一般发生在文件删除操作后。
- PendingReplica,待复制副本块。
- NeedReplica(或被称为UnderReplica),当前需要被重启replicate的副本。
- PostponedReplica,本认为stale的副本块。
以上的划分是一种比较粗粒度的状态划分,还未到细粒度比如是否在under-construction之类的阶段。后续副本块冗余度的重新构建和以上的副本将会密切相关。
HDFS块副本冗余度的重建
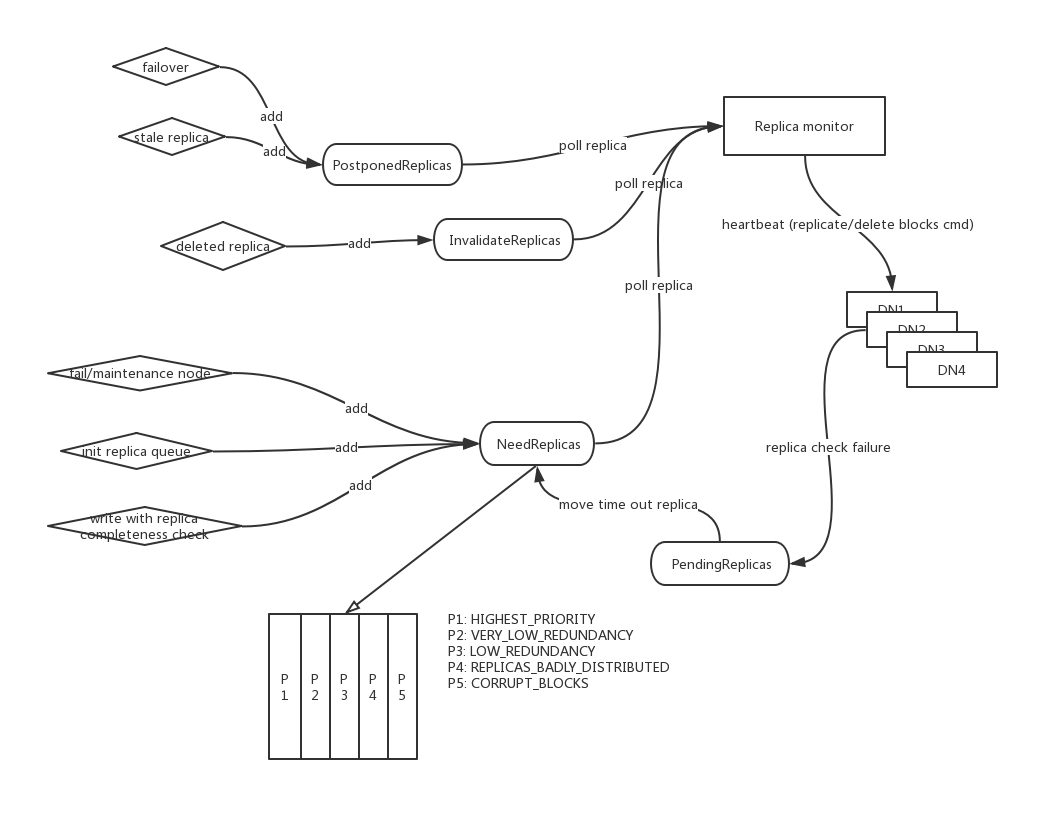
重建围绕的核心:NeedReplica
在HDFS重建副本块的过程里,最与之密切相关的是当前需要被复制的块状态副本,即NeedReplica。
HDFS在各种情况的检查中如果发现某个块的副本没有达到预期情况时,会加入一个块副本记录到NeedReplica对象里,而不是马上开始下发replicate操作命令给下面的DN。
HDFS并不会是时时刻刻都在检查所有块的冗余度情况(那样显然会加重NN的负担),而是在以下的特定场景中检查:
1). 当下线节点,或节点shutdown的情况
2). 当写完一个文件的时候,再重新检查一次该文件块的副本是否达到预期数
3). NN重新启动为Active服务后的初始化过程中,做一次全量块的副本数检查。
上述提到的副本块是否达到预期并不是单纯的指定是当前副本数达到期待副本数量,在一些系统内还会判断副本的placement是否满足预期,比如是否分布在多rack的情况。因为同rack的情况是会存在丢数据的风险的。
这里还有另外2种和NeedReplica相关的副本状态。
- PendingReplica:待加入NeedReplica集合的副本块,比如一些replica在上次replication操作失败后会重新加入pending集合,然后又会被定期挪到NeedReplica里面。
- PostponedReplica:这类Replica被认为是状态延时,落后的,需要等待其上的DN最新一次的块汇报来表明其是live的。对于这类replica,NN也是将其作为临时不可用的副本数据,也是需要replication的。但和NeedReplica不同的是,一旦检测出新的块数据已经报告上来了,这些postponed的replica自然会被挪掉。所以这类replica只是一种“假定missing”的副本。一般发生于服务failover阶段。
待复制副本的优先级划分
当副本数据出现损坏丢失的时候,不是所有的数据损坏的情况是一致的,所以这里我们需要给待复制的副本定个优先级。以此告诉系统哪些副本块是要被优先复制的。一个最简单的例子,3副本里丢了2个副本的数据的优先级是要大于3个副本里只丢了1个副本的那个数据的。
在HDFS里,对带复制做了5个层级的划分:
- P1:最高优先级的,比如说目前只存在单副本的情况了。
- P2:冗余度很低的情况,比如副本中丢失了2/3的情况。
- P3:冗余度较低的情况,比如副本中丢失了1/3的情况。
- P4: 副本数冗余度足够,但是location不对,比如同rack甚至同节点,存在丢数据的风险。
- P5:损坏副本块,此情况为所有副本块都已丢失的情况,理应也复制不了了。
HDFS的延时副本重建过程
HDFS出于性能的考虑,采用了一种延时复制的策略。它开启了一个独立线程周期性的处理这些需要被额外复制的副本块。我们可以简单理解为它是一个副本状态中央处理器,包括对于无效副本块的处理也是它做的。
注意,这个中央副本处理器本身不做实际数据的拷贝删除,而是将对于副本请求命令下发给对应的DN。这些命令在下一次的NN给DN的心跳内会带上这些命令。以上整个流处理图如下:
以上就是本文阐述的关于块副本冗余度处理的相关内容,希望给大家带来收获。