前言
在存储系统写数据的过程中,出于性能上的考虑,新写的数据并不是每次都flush到目标存储中的,而是先放入到一个buffer空间里,等到buffer空间满了,再做一次flush出去的动作。这种情况和人们等车的例子极为类似,一辆车等人都上满了再开,才能保证更高的效率。但是这种缓冲设计模式还是存有一个主要弊端的,当缓冲数据满后将会阻塞住后面的数据操作直到缓冲数据完全flush出去。更简单的来说,这里会有个throughput的问题。那么有什么改进办法呢,答案是利用另外一个缓冲构成双缓冲模式。本文笔者来聊聊双缓冲的模式设计。
单缓冲模式
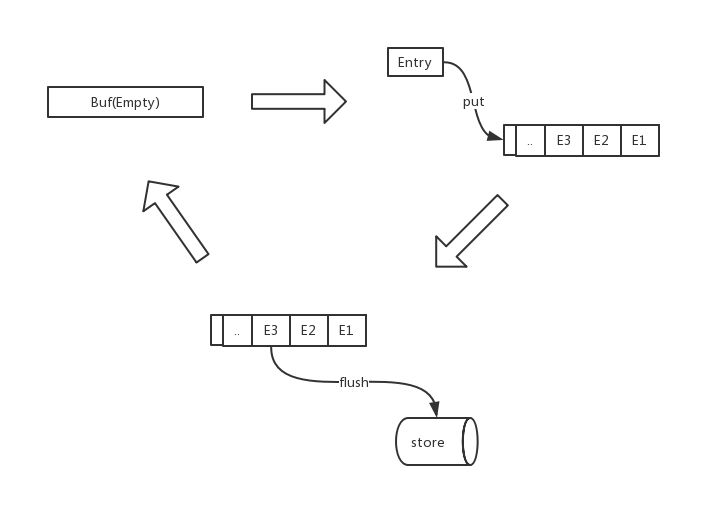
我们先来回顾下单缓冲的工作模式,工作原理上面已经提到过了,如下图所示。
单缓冲模式改进: 双缓冲模式
双缓冲比较学术的称谓叫做DoubleBuffer。这个有个大家可能理解的误区:双缓冲就是单缓冲在size空间上的的double。如果是这这种模式,throughput问题依然存在。
如果说增大缓冲区长度属于纵向扩展的话,那么这里所说的双缓冲则是横向上的扩展。
它的运作原理如下:
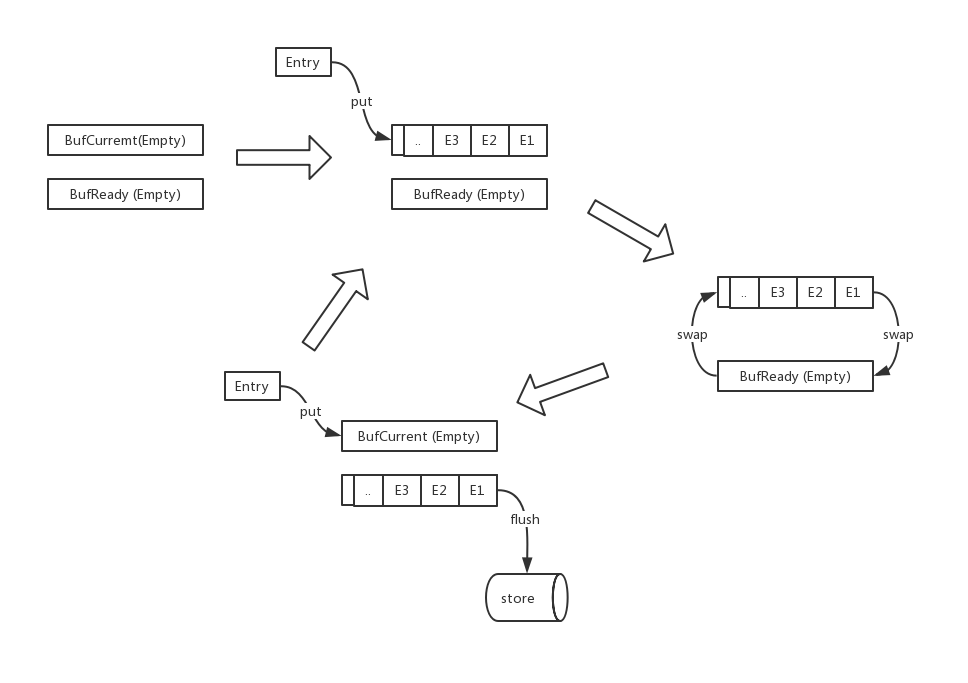
将缓冲区分为2份,1份为当前缓冲区buf current,另外1份为预写入分区buf ready,两个缓冲区空间大小一致。current区负责当前的写操作存放,当我们达到缓冲处罚条件时,执行一次双缓冲的调换操作。然后由另外的程序执行ready区的flush操作。被交换变为空缓冲区的current区重新用于这的数据写入。
以上的执行模式有以下2大优势:
1)程序无需反复进行创建新缓冲的操作
2)程序的写请求不会被阻塞住,除非current缓冲区已经满了同时ready缓冲区数据还没有全部flush出去
在使用双缓冲区模式时,因为缓冲区是可能存在concurrent使用的情况,所以这里需要有thread safe的处理,以此保证每个操作是原子的更新。比如双缓冲在swap的时候就不应该发生add缓冲的动作,再比如还应该有一个线程可先性的变量来告诉程序,ready缓冲区是否已完全flush出去。
同样地,笔者简单构建了双缓冲区的流程图,如下所示:
双缓冲设计在一些存储系统中有所应用,大家可以阅读相关系统代码进行细节上的阅读,比如HDFS里的EditsDoubleBuffer类。