文章目录
前言
对于HDFS的扩展性问题来说,很多人或许都了解过HDFS federation的方案,一种通过横向扩展命名空间的做法来延展其扩展性。其实,随着集群规模的扩张,不仅仅存储系统会有性能瓶颈问题,计算系统也会存在这样的问题,比如说YARN的ResourceManager(下面简写为RM)服务。当RM下面管理这上千甚至上万个NodeManager节点时,同样会面临着许多性能问题,大量同时在跑的应用所触发的待处理的event数等等问题。一般这种情况,我们的一个简单直接的方案是再搭建一个新的YARN集群。因为Hadoop中存储和计算是可以分离的,所以独立搭建YARN完全没有任何问题。之后引流一部分在线任务到新的YARN集群即可分担单集群的压力了。但是这套简单直接的方法会造成日后多独立集群管理的不便,而且更为重要的一点是它无法保证资源的更高使用率。本文笔者来聊聊YARN对此更有的解决方案:YARN Federation设计。
YARN Federation缘由
正如前文所阐述的,YARN的Federation的缘由是为了解决RM的扩展性问题的。如果单纯通过搭建新的YARN独立集群的方式,会造成管理的不便,还有一点就是资源无法被充分利用到。我们无法保证每个集群在资源空闲的时候能够及时地安排上任务执行,除非我们有一种全局控制各个RM的调度器。至少在独立集群部署模式下,做到这种智能调控并不容易。而在这点上,YARN Federation已经为我们实现了这点。
下面我们来具体了解YARN Federation的架构设计,通过了解它的架构设计,我们就能更清楚地知道它是如何做全局资源调度的了。
YARN Federation整体架构
YARN Federation功能并没有对原始YARN的核心逻辑做大规模的修改,只是在其上做了额外的处理。这里面涉及的主要有以下两大模块:
- 1.多集群状态信息收集,存储
- 2.客户端请求路由服务实现
YARN Federation设计的一个重要目标是让众多独立小集群变为逻辑意义上的一个超大资源池。对于客户端来说,它直接面对的将不是众多具体的独立小集群。而要做到统一大集群资源,当然我们首先需要知道有哪些集群信息,包括集群id,地址,容量使用等等。而且我们需要将这些信息进行持久化操作,这样可以做到服务间的信息共享。
而另外一个核心模块就是客户端的请求路由模块。在客户端和背后多YARN小集群之间,我们需要有一个Router这样的角色,做智能的请求转发。这个角色有点load balancer的意思,又可以理解为是一个Proxy的role。在这里Router就需要用到之前持久化的多集群信息了。然后我们的路由策略也会根据各个集群的状态信息做目标集群的选择。
了解完YARN Federation的大致原理之后,我们来看YARN Federation的架构设计图:
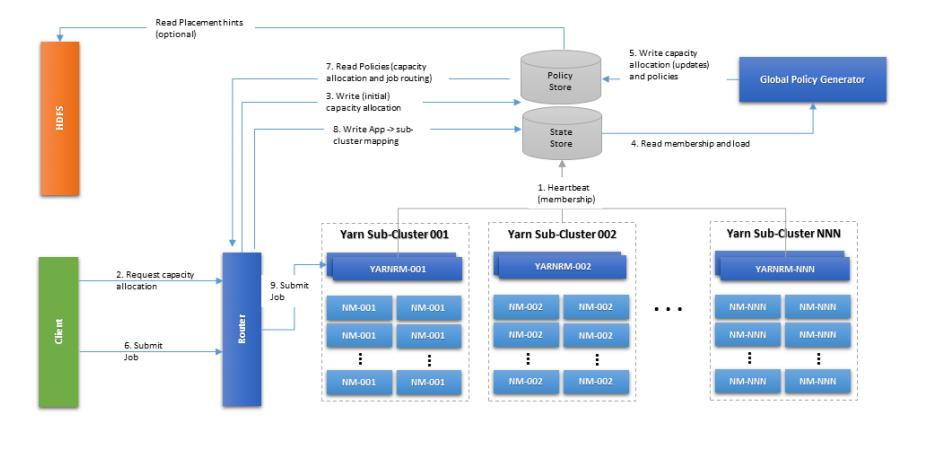
上图中的State Store部分即上面提到的状态持久化模块,不过上面将Policy Store单独拎出来了,策略信息的存储比较特殊。它是由专门的策略生成类进行存放的。简要概括上述步骤:
1.多YARN子集群(主要指RM)通过心跳汇报状态信息,这些信息被持久化到了State Store中去了。这个State Store是可选择的,基于memory或者zk based,或是SQL based的都支持。
2.Global Policy Generator角色根据集群状态信息写入相关Policy调度策略信息。
3.客户端向Router提交应用请求,Router与State Store进行交互,拿到策略信息,然后选择一个目标的Cluster。然后转发请求到目标RM上。同时提交的Application ID和目标集群ID映射信息会被保存入State Store。这是为了后续查询的方便,同样也是为了Router重启时应用状态的恢复。
这里为了性能上的考虑,减少频繁的State Store,Router会对从State Store中查询来的信息做cache处理。
YARN Federation的Policy策略
在YARN Federation策略中,具体还分为两个模块的策略:
第一类,Router路由模块的Policy。负责为应用选择一个主Cluster,也称为home cluster。
第二类, AM Proxy Policy。这个Policy适用于AM如何决定向哪些Cluster申请资源。因为这里会存在跨集群资源申请的情况。
这里我们主要谈论简单一点的Router Policy。在YARN Federation过程中,为了保证能够更高效的调度统一大资源,YARN Federation设计了多种灵活的Router Policy策略。从YARN Federation的初始设计文档中,主要介绍了如下几种:
- 根据优先级级别来,预先分配给每个YARN集群一个优先级,比如1,2,3,优先级顺序1>2>3,只有当优先级高的集群资源不可用时,才调度应用到下一个较低级别的集群上。
- 根据权重比例进行选择,也可以理解为这是一个概率选择策略。每个集群分配不同的比例,比如7:2:1,此比例意为70%可能性任务会提交到第一个级别,20%的可能性会落在第二个集群上,最后10%则是第三个集群。
- 根据集群负载情况进行调度,这里的对“负载”的衡量指标可以是各个RM的剩余memory可用量进行判读。每次调度应用到可使用资源更多的集群内,以此保证整体集群资源的最打使用率。
AM跨集群间的资源调度
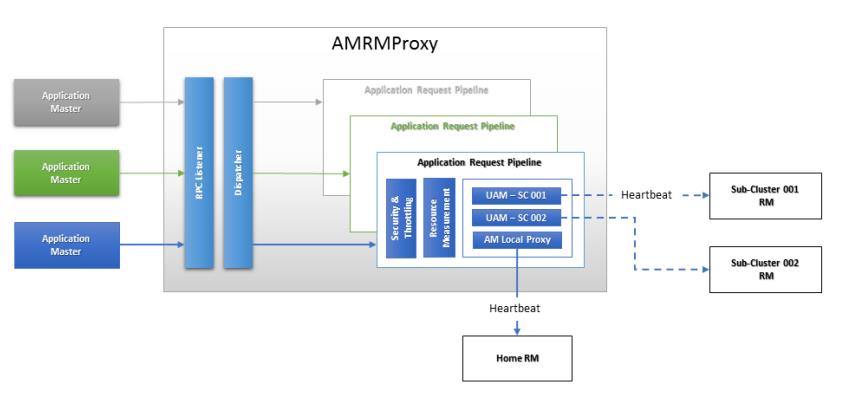
跨集群资源的调度,YARN Federation支持跨集群资源调度的情况。它的原理是在AM和RM之间增添了一个Proxy Service做中间的拦截,此服务叫做AMRMProxy。AM会首先连接AMRMProxy,然后AMRMProxy再负责和各个RM通信。这里就会存在本地的AM向远程RM通信的可能性。当然AMRMProxy的拦截作用,它可以在中间做请求的限流或是Security等额外的管控。
以下是AMRMProxy的内部结构图:
YARN Federation的全局资源调度
在YARN Federation模式下,这里的资源调度是一个全局的模式。全局调度的益处还能解决部分极端情况导致某些子集群完全无法用的情况。AM不仅仅可以与本地的RM申请资源,还能够向其它集群申请资源。这里借助的角色就是上文提到的AMRMProxy服务。AMRMProxy再负责和其他非本地RM进行通信。
那么YARN Federation模式是如何支持跨集群的资源申请的呢?答案是通过Router,Policy Generator和AMRMProxy三者的协调合作来完成了。资源申请的基本原则是基于YARN内部的资源Reservation APIs来做。而对于每个集群具体申请多少量,则根据每个集群的实际状态信息,Policy Generator进行策略写入。这个策略信息里包括了每个集群的资源申请量等等信息。然后AMRMProxy随后读取策略信息,再进行具体的资源预留申请,流程图如下所示。
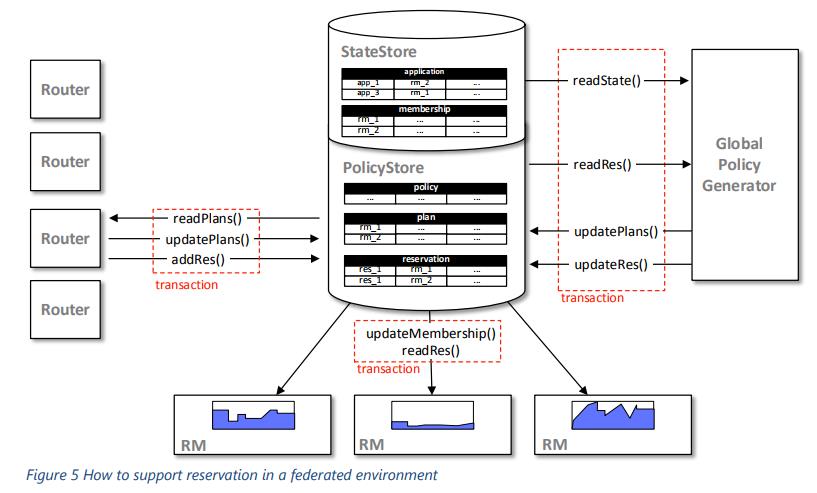
鉴于部分应用可能会存在跨多个集群运行的情况,客户端向Router查询应用状态信息时,需要广播请求到所有的RM,最后再合并查询结果返回给客户端。
以上是原始设计文档的设计思路,不过笔者目前并不确定是否完全照此方案实现,具体实现还得当前代码的实现方案。
YARN Federation的相似设计:HDFS Router-based Federation
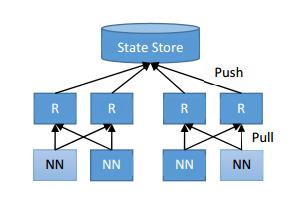
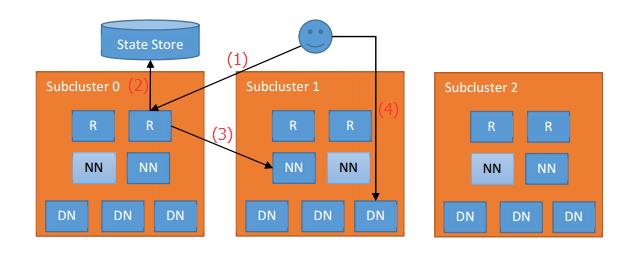
HDFS在后期设计实现的基于路由的Federation方案,与YARN Federation有着高度的相似性,包括里面有完全功能类似定义的State Store,Router的角色定义,不过目标服务由于RM变为了NN。不过笔者对比这2者一些小细节设计上的差异,YARN Federation在调度上会更复杂一些,它不仅仅有Router Policy定向还有一个AMRMProxy的代理角色,而HDFS RBF则只有Router这么一层中转处理。
以下是HDFS RBF的架构设计图(相关文章可阅读HDFS基于路由的Federation方案),大家可以了解对比本文所阐述的YARN Federation的设计。
引用
[1].https://blog.csdn.net/androidlushangderen/article/details/78573732
[2].https://issues.apache.org/jira/browse/YARN-2915 . Enable YARN RM scale out via federation using multiple RM’s