前言
众所周知在HDFS中,DataNode会进行定期的全量块汇报操作到NameNode中,来向NameNode表明其上所存储的所有块数据。这个动作在HDFS中称之为Full Block Report,简称FBR。FBR其实是一个十分expensive的操作,尤其当DataNode存储有大量block块的时候。又因为HDFS FSN全局单一锁的设计,当NameNode同时需要处理来自其下多个DataNode的FBR的时候,就可能陷入overload的情况。进而表现在用户应用层面,就是用户请求响应延时等等。本文笔者来聊聊HDFS的全量块汇报问题,以及目前社区对此的优化方案。
HDFS全量块汇报(FBR)的性能问题
如上文所提到的,由于HDFS内部的全局单一锁的设计,当NameNode对系统元数据做修改操作时,其它所有别的操作都将被block住。因此假设每个DN的FBR都包含有大量块信息的时候,NameNode将会花费很大的开销来处理这些汇报的块。
Hadoop社区在很早的时候就发现了这个问题,它提出的一个改进思路是:既然一整个大的FBR行为会造成很大的性能问题,那么我们是否可以将它拆分成多个小部分的块,并且分多次RPC进行发送呢?基于这个思路,社区在HDFS-5153: Datanode should send block reports for each storage in a separate message.实现了基于每个Storage的块汇报实现。在此优化下,当DataNode发现自身全量块汇报的总数大于阈值块汇报数(默认为100w)时,会将块按照每个Storage存储目录进行汇报,这样一个大的FBR RPC就变为了多次小的RPC行为。这样的话,远端NameNode处理DataNode的FBR压力会小许多。,相关逻辑代码如下:
// 当全量块汇报数小于阈值块时,进行一次性汇报行为
if (totalBlockCount < dnConf.blockReportSplitThreshold) {
// Below split threshold, send all reports in a single message.
DatanodeCommand cmd = bpNamenode.blockReport(
bpRegistration, bpos.getBlockPoolId(), reports,
new BlockReportContext(1, 0, reportId, fullBrLeaseId, true));
blockReportSizes.add(
calculateBlockReportPBSize(useBlocksBuffer, reports));
numRPCs = 1;
numReportsSent = reports.length;
if (cmd != null) {
cmds.add(cmd);
}
} else {
// 否则按照Storage,进行多次RPC汇报
// Send one block report per message.
for (int r = 0; r < reports.length; r++) {
StorageBlockReport singleReport[] = { reports[r] };
DatanodeCommand cmd = bpNamenode.blockReport(
bpRegistration, bpos.getBlockPoolId(), singleReport,
new BlockReportContext(reports.length, r, reportId,
fullBrLeaseId, true));
NameNode的FBR限流机制
上面提到的HDFS-5153改进虽然在一定程度上的确是优化了HDFS的FBR处理,但是随着当今存储技术的进步,单块磁盘能够存储的数据量也在不断提升。进一步地来说,DataNode将FBR拆分出的小的Storage Report也可能存在包含有大量块信息的情况。面对Storage存储密度不断上升的情况,HDFS-5153并没有解决掉本质问题。
那么这里我们有什么别的优化方向呢?我们是否能在NameNode端做特殊处理,能够使得它避免长时间忙碌于FBR的处理之中呢?为此,社区在block report中引入了租约的概念来控制DataNode的全量块汇报行为,简称BR Lease。在BR Lease机制下,只有那些获得了NameNode所授予的BR Lease的DataNode节点,才能进行FBR行为。有了这层控制,NameNode就能够减缓底层大量DataNode所带来的FBR操作压力了。
用一个轻松、简单的对话来模拟BR Lease下的FBR行为:
DN: Hi NN,我现在能进行全量块汇报行为吗?
NN:我现在太忙了,不能让你汇报。
过了一会儿,DN又来问了:
DN: Hi NN,我现在可以进行全量块汇报行为吗?
NN:现在不忙了,可以汇报了,我来分配给你一个租约。
DN拿到了NN所授予的租约,NN验证了DN租约的有效性后,然后进行了FBR处理。
其实从中我们可以看到,BR Lease在这里变相起到了Rate Limit的作用,至于这个Rate到底控制在什么值,可以根据具体场景进行具体设置。
BR Lease的管理控制
社区在HDFS-7923: The DataNodes should rate-limit their full block reports by asking the NN on heartbeat messages中实现了基于BR Lease的FBR的限流控制。在此实现内,新增了一个专门管理BR Lease的管理类BlockReportLeaseManager。BlockReportLeaseManager负责有以下2类功能:
- 分配DataNode租约Id
- 处理块汇报前验证DataNode提供的租约Id是否有效
BlockReportLeaseManager对DataNode的BR Lease做了额外两项的限制:
- 当前最多允许的Lease分配数,进而限制DataNode的FBR上报数,DataNode只有拿到Lease Id才能进行下一步的FBR。
- 每个Lease有其过期时间,过期时间设置是为了限制Lease的有效使用时间范围,借此避免DataNode长时间占用Lease。
基于BR Lease的FBR限流逻辑
下面我们通过具体代码来展示基于BR Lease的FBR限流逻辑。
首先是DataNode端,相关操作方法BPServiceActor#offerServic
// 1. 判断是否需要发送请求BR Lease
boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&
scheduler.isBlockReportDue(startTime);
if (!dn.areHeartbeatsDisabledForTests()) {
// 2. 发送心跳给NN,获取BR Lease信息
resp = sendHeartBeat(requestBlockReportLease);
assert resp != null;
if (resp.getFullBlockReportLeaseId() != 0) {
if (fullBlockReportLeaseId != 0) {
...
fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();
}
..
// 3. 如果获取到的Lease Id不为0,则进行FBR操作(顺带带上LeaseId)
if ((fullBlockReportLeaseId != 0) || forceFullBr) {
cmds = blockReport(fullBlockReportLeaseId);
// 重置FBR的Lease Id, 为了让DN下次重新申请Lease Id
fullBlockReportLeaseId = 0;
}
然后我们紧接着来看服务端的逻辑方法,首先是FSNamesystem.handleHeartbeat对于request FBR Lease的处理,相关方法FSNamesystemhandleHeartbeat
HeartbeatResponse handleHeartbeat(DatanodeRegistration nodeReg,
StorageReport[] reports, long cacheCapacity, long cacheUsed,
int xceiverCount, int xmitsInProgress, int failedVolumes,
VolumeFailureSummary volumeFailureSummary,
boolean requestFullBlockReportLease,
@Nonnull SlowPeerReports slowPeers,
@Nonnull SlowDiskReports slowDisks)
throws IOException {
readLock();
try {
//get datanode commands
...
long blockReportLeaseId = 0;
// 从BlockManage中获取租约
if (requestFullBlockReportLease) {
blockReportLeaseId = blockManager.requestBlockReportLeaseId(nodeReg);
}
//...
return new HeartbeatResponse(cmds, haState, rollingUpgradeInfo,
blockReportLeaseId);
} finally {
readUnlock("handleHeartbeat");
}
}
我们进入BlockManager的requestBlockReportLeaseId方法,在里面分配BR LeaseId时就有着限流逻辑,通过当前可允许分配的最大Lease数来做,相关方法BlockReportLeaseManager#requestLease
public synchronized long requestLease(DatanodeDescriptor dn) {
NodeData node = nodes.get(dn.getDatanodeUuid());
...
// 1. 在分配新的Lease之前先移除过期的Lease
pruneExpiredPending(monotonicNowMs);
// 2. 如果当前的有效Lease超过最大可允许值,返回0代表请求Lease Id失败
if (numPending >= maxPending) {
if (LOG.isDebugEnabled()) {
StringBuilder allLeases = new StringBuilder();
String prefix = "";
for (NodeData cur = pendingHead.next; cur != pendingHead;
cur = cur.next) {
allLeases.append(prefix).append(cur.datanodeUuid);
prefix = ", ";
}
LOG.debug("Can't create a new BR lease for DN {}, because " +
"numPending equals maxPending at {}. Current leases: {}",
dn.getDatanodeUuid(), numPending, allLeases.toString());
}
return 0;
}
...
}
接着是BlockManager对于DataNode上报的FBR的处理,相关方法NameNodeRpcServer#blockReport
public DatanodeCommand blockReport(final DatanodeRegistration nodeReg,
String poolId, final StorageBlockReport[] reports,
final BlockReportContext context) throws IOException {
checkNNStartup();
...
try {
// 1. 检查FBR租约的有效性,主要包含两方面的检查
// 1)租约Id是否为当前已分配给此DN的Lease Id值
// 2)租约Id是否已过期
if (bm.checkBlockReportLease(context, nodeReg)) {
for (int r = 0; r < reports.length; r++) {
final BlockListAsLongs blocks = reports[r].getBlocks();
...
final int index = r;
// FBR租约验证通过,BlockManager进行FBR的处理
noStaleStorages = bm.runBlockOp(() ->
bm.processReport(nodeReg, reports[index].getStorage(),
blocks, context));
}
...
附上上述逻辑的流程图:
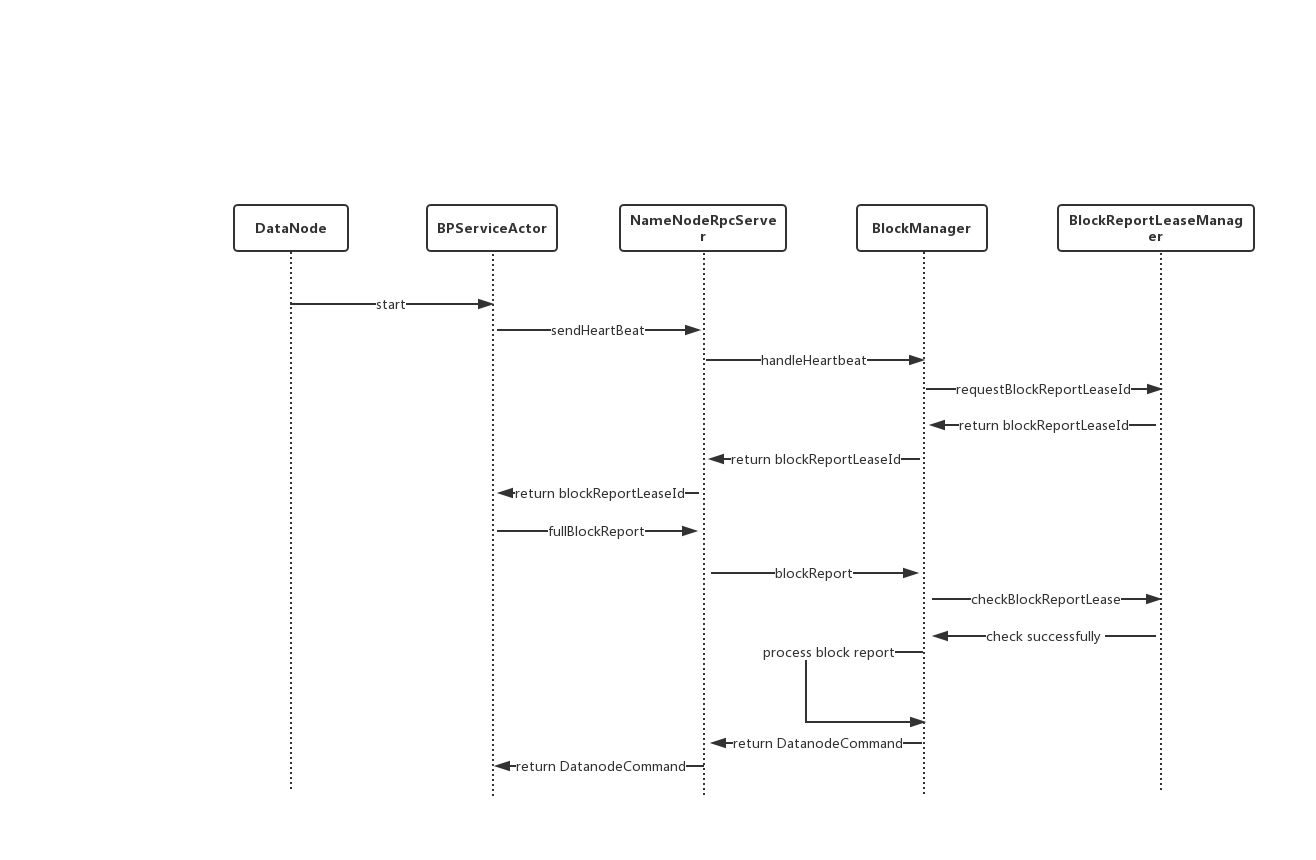
以上就是基于Lease的FBR限流控制原理,但是回过头来再细看这个方案,它依然还不是最完美的。因为DataNode的FBR在本质上依然没有被彻底改造,可能在未来更好的做法将FBR行为进行分段拆分,然后NN再要求DN汇报这些分段的block report,然后进行处理。这里笔者想表达一个核心point是FBR的行为应该由NN这边来控制,它来要求DN怎么去发,而不是目前单方面的由DN一股脑地将自身的全量块汇报给NN。
引用
[1]. https://issues.apache.org/jira/browse/HDFS-5153
[2]. https://issues.apache.org/jira/browse/HDFS-7923