前言
在YARN调度的早期实现中,调度的方式是基于NM节点的心跳来的。简单来说,就是每当一次节点的心跳来的时候,YARN scheduler会进行一次container分配尝试,然后将最适合分配的应用container分配在此节点上。这种一个节点一次的调度方式在决策选择上确实比较高效,但在某些场景上并不显得最优,比如带有约束条件的container调度来说。本文笔者来聊聊YARN后期实现的全局调度的设计理念以及它和原有方式的不同点。
带有约束限制的调度
在原先一个节点一次调度选择的策略下,假设当某应用只要求跑在一个拥有1千机器的1个节点上,那么Scheduler在为此应用分配container时,就需要进行一个一个节点多次的尝试,直到找到那个匹配的节点。
而在全局调度模式中,scheduler根据应用的要求,可以从更多的节点中去做节点地选择。这一点是和原有方式大大不同的。
全局调度的要求
全局调度需要有以下主要的要求,以此保证其实用性:
支持快速决策的响应。在大型分布式计算集群内,每分钟每分秒内会有大量的task运行开始结束,因此需要调度器能够快速地进行资源地重分配。但是全局调度因为面向更多的节点做分配选择,相比较原有方式,在时间选择开销上必然要大一些,因此这里我们需要全局调度同样能做到快速的决策选择。 倘若在一次节点选择中没有及时返回节点,那scheduler也应能及时返回timeout,结束本次的选择。
全局调度的流程
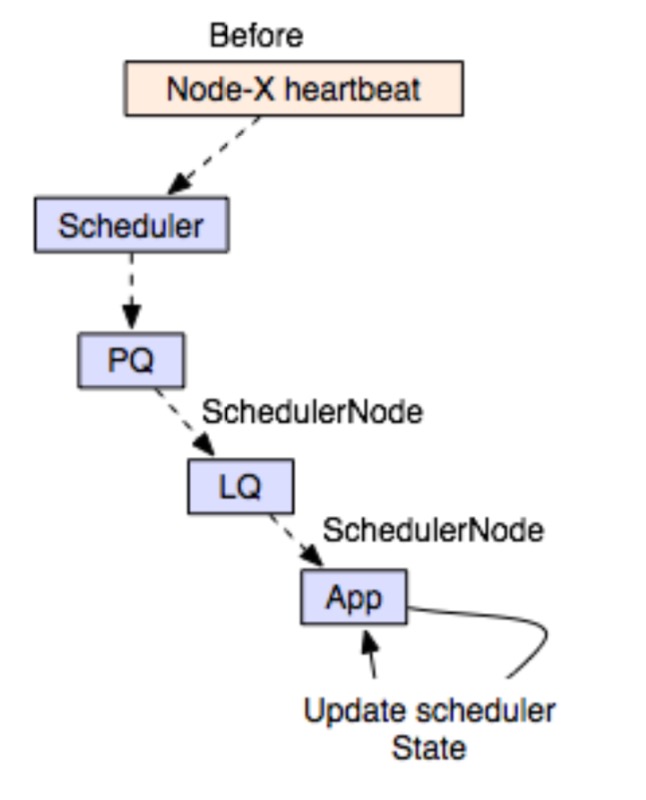
以下是YARN原先的调度流程图,scheduler触发的条件从node的heartbeat触发开始,然后进行后续的节点选择调度,
YARN全局调度模式下,它的调度过程主要有以下的变化:
- 支持多Container分配线程并行执行
- 面向更多节点做资源的请求分配
- 新增Resource Committer服务来为资源分配的proposal进行再次判断
因为资源情况瞬息变化,当container proposal产生时,还需要在最终分配时进行再一次确认。此过程逻辑如下,
/*
* Scheduler will implement the interface
*/
class Scheduler implements ResourceAllocationCommitter {
// 获取Container allocation的proposal
ResourceAllocationCommitRequest getAllocationProposal(PlacementSet clusterPlacementS
readLock {
// Following operations are in read-lock
return rootQueue.getAllocationProposal(clusterPlacementSet);
}
}
void tryCommit(ResourceAllocationCommitRequest proposal) { writeLock {
// Following operations are in write-lock // Get application for a given proposal
SchedulerApplicationAttempt app = get_application(proposal); // Check if the proposal will be accepted or not:
// 检查Container的申请的proposal能否被接受
boolean accepted = app.accept(proposal);
// 如果proposal能够被接受,则采纳proposal的建议
if (accepted) {
// If proposal is accepted, apply the proposal (update states)
// The reason why we need two separate accept / apply method is: // We need first check if proposal can be accepted before update // internal data. Otherwise we need revert changes if proposal is rejected by upper level.
app.apply(proposal);
} else {
// Otherwise, discard the proposal
}
}
}
然后在allocation的thead中会调用上述scheduler的逻辑,
// We can have multiple such thread running at the same time
Thread allocationThread = new Thread() {
void run() {
while (true) {
ResourceAllocationCommitRequest proposal =
// Pass down cluster-placement-set, which is essentially a set of all the available nodes in the cluster
scheduler.getAllocationProposal(get_available_placement_set());
scheduler.tryCommit(proposal);
}
}
}
全局调度图示如下:
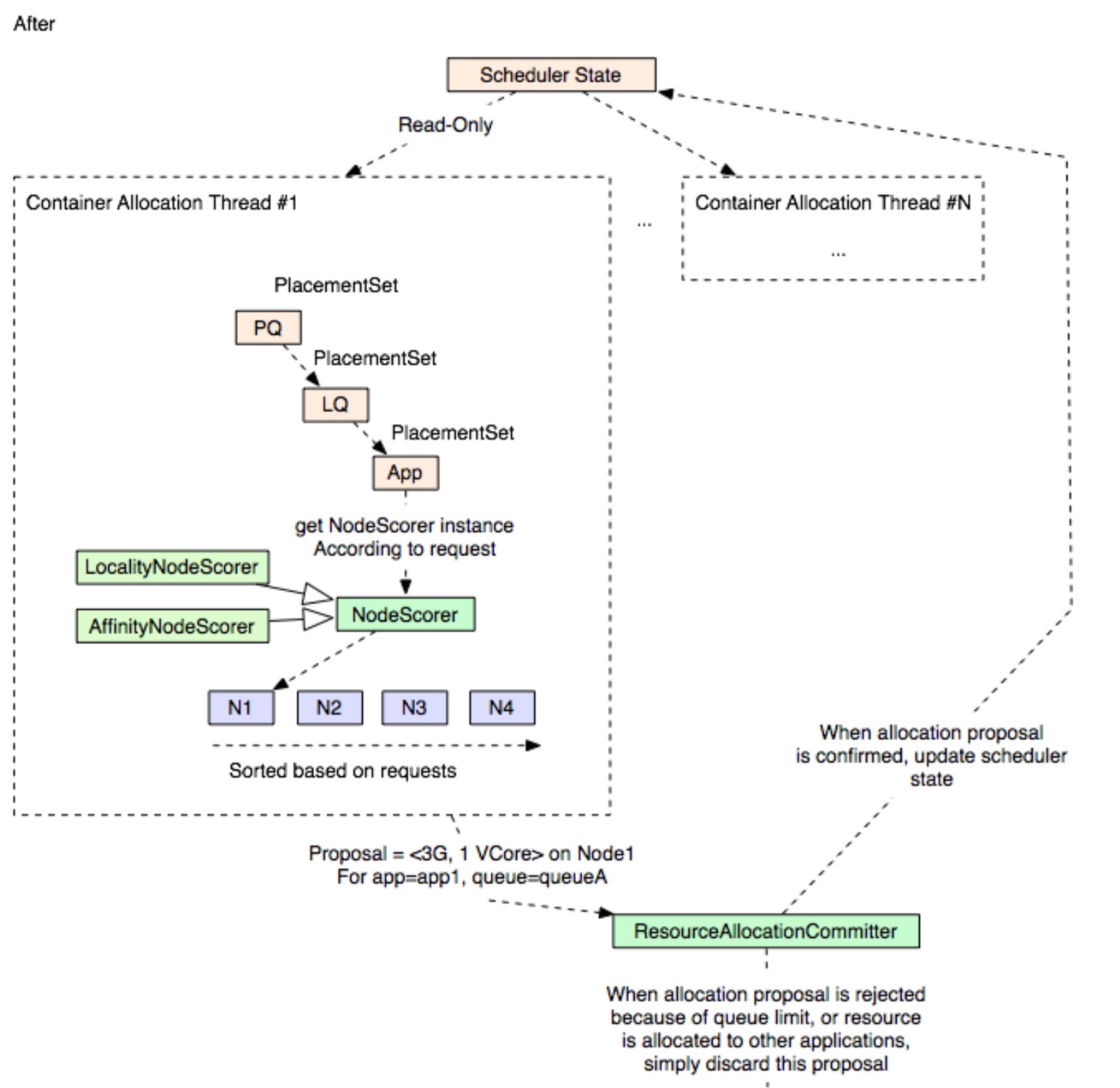
上述多线程同时并发处理Container的分配是其中一项对于全局调度模式快速响应的优化方式。在全局调度模式下,我们面向的可供选择的节点变多了。对于此方面,还有另外几项可以加速全局调度选择的措施:
- 对于没有特殊节点偏向要求的应用,我们可以快速分配随机的节点进行资源的分配。
- Cache节点排序列表,对于一部分资源请求来说,这些资源请求所优先选择的节点要求在短时间内是不变的,我们可以保存一定时间这样的结果。
附:关于约束标签下的Max-Min Fairness方法
Max-Min Fairness方法在资源调度选择中应用得十分广泛了,不过这里笔者想 额外谈谈关于标签约束下的Max-Min Fairness方法。标签约束的另外一层意思实际指的是用户/应用的节点要求选择。下面我们来通过一个简单的例子来了解下这个方法,此方法来源于一篇讲述 Choosy(一个在线的基于约束标签的最大最小公平调度器)的paper。
假设目前有2个用户{u1,u2},5台机器{m1, m2, m3, m4, m5},约束标签如下,
c1={m1, m2}: u1用户只能使用在m1和m2机器下的资源
c2={m2, m3, m4, m5}: u2用户只能使用m2, 3, 4, 5下的机器资源
在以上2者标签约束下,我们如何做到最大最小公平分配呢?
按照公平算法来,首先是第一轮,我们保证每个用户能分到等量的资源并且满足它们的约束标签,结果如下
u1: {m1, m2}
u2: {m3, m4}
因为u2用户不能用u2机器,否则u1所能使用到的最大资源数就少了。
然后第二轮,我们看在约束标签条件下,在不减少其它用户资源使用量的情况下,哪些用户还能增大其资源使用量,于是我们可以看到u2的资源使用量可以继续加大,
u1: {m1, m2}
u2: {m3, m4, m5}
所以以上就是最终的分配结果。
另外,关于YARN全局调度的更细节内容可参阅文末尾参考链接处。
引用
[1].https://issues.apache.org/jira/browse/YARN-5139 . [Umbrella] Move YARN scheduler towards global scheduler