本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
1.安装MySql
按ctrl+alt+t打开终端窗口,安装mysql需要输入命令:sudo apt-get install mysql-server
输入命令:service mysql start #启动mysql
输入命令:sudo netstat -tap | grep mysql #查看mysql是否启动成功,mysql结点处于LISTEN状态表明启动成功
如下图所示:

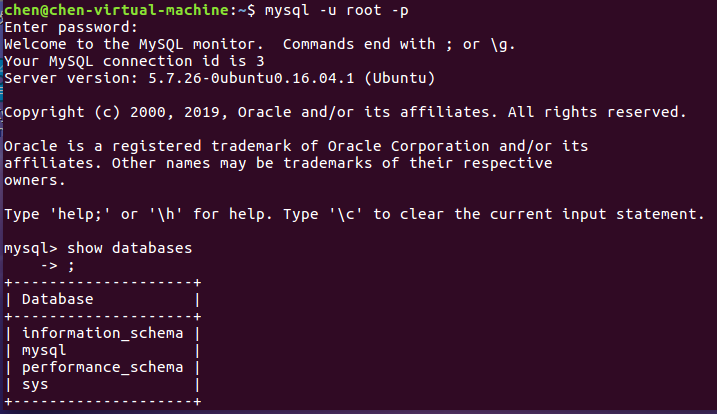
输入命令:mysql -u root -p #进入mysql shell界面
输入命令:show databases; #显示数据库
如下图所示:
2.windows 与 虚拟机互传文件
为了使windows与虚拟机互传文件,所以需要安装vmware tools工具,安装步骤可见后面部分:https://blog.csdn.net/weixin_42305895/article/details/89879220
如图所示,已经成功安装vmware tools工具。
3.安装Hadoop
我已经成功安装了hadoop,伪分布式hadoop的安装教程可见:https://blog.csdn.net/weixin_42305895/article/details/89925119
启动hadoop,如下图所示。
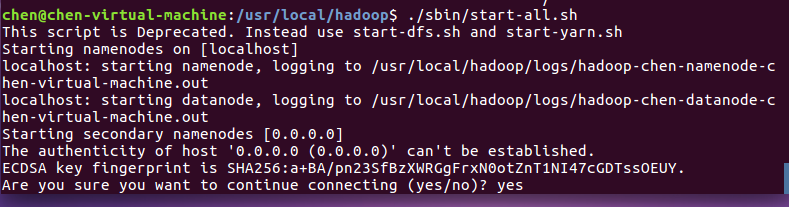
输入jps可查看hadoop是否启动成功,如果启动成功则会出现如下进程:“NameNode”,“DataNode”,“SecondaryNameNode”,如下图所示。

关闭hadoop,如下图所示。

4. 简述Hadoop平台的起源、发展历史与应用现状。
(1)起源
项目起源
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
发展历程
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop
[3] 最初只与网页索引有关,迅速发展成为分析大数据的领先平台。目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估的软件。
名字起源
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
Hadoop的发音是 [hædu:p]。
(2)发展历史
2011年12月27日--1.0.0版本释出。标志着Hadoop已经初具生产规模。
2009年4月-- 赢得每分钟排序,59秒内排序500 GB(在1400个节点上)和173分钟内排序100 TB数据(在3400个节点上)。
2009年3月-- 17个集群总共24 000台机器。
2008年10月-- 研究集群每天装载10 TB的数据。
2008年4月-- 赢得世界最快1 TB数据排序在900个节点上用时209秒。
2007年4月-- 研究集群达到两个1000个节点的集群。
2007年1月-- 研究集群到达900个节点。
2006年12月-- 标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2006年11月-- 研究集群增加到600个节点。
2006年5月-- 标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年5月-- 雅虎建立了一个300个节点的Hadoop研究集群。
2006年4月-- 标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
2006年2月-- 雅虎的网格计算团队采用Hadoop。
2006年2月-- Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年1月-- Doug Cutting加入雅虎。
2005年12月-- Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2004年-- 最初的版本(称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
(3)应用现状
hadoop的应用现状很广泛,这里我就不一一描述了,大家可以去看国外、国内Hadoop的应用现状,描述的比较详细。