随着业务的不断增加,我们的单台服务器承受不住需求,那么我们就需要对此进行伸缩,有两种维度,一种是纵向的也就是增大该台服务器的硬件,再者就是加新服务器与之前的机器组成集群对外提供服务,我们都知道前者是有瓶颈的,so,集群技术是对web架构极其重要的!
集群的定义,我萌百度下就可以了:集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器
集群的作用:提高可用性和可缩放性
集群的种类:高可用、负载均衡、高性能
可缩放性我们很容易理解,高可用性其实也不难,因为我提供同一服务的机器多了,那么其中一台机器挂了其他机器撑住就可以了。由此可以看出,作为集群的机器的可用性不需要十分的高(是服务器都会有保证的,不会自己没事就坏),所以我们在硬件采购时就可以节约一些成本,比如购买单电源的插头,网卡也不需要太多,双网卡就好等等,能节约成本老板一定会很开心的~
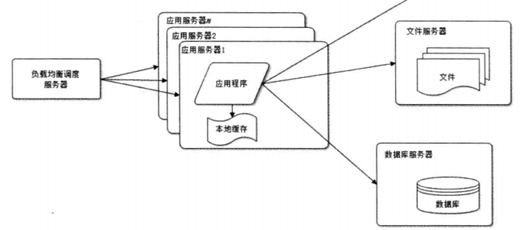
PS技术不好,23333333。我们可以看出应用服务器变多了,前面还加了一个负载均衡调度器,只画了一个,其实这是存在单点故障的,它的高可用性也是必需的!so,我们从它入手,常用的高可用集群软件有heartbeat、keepalived、rhcs,最简单常用大家都喜欢的是keepalived,它的安装非常简单,直接yum就可以,如果对版本有需求用编译也还是那三步,这个不介绍了,我们来看配置文件,默认是在/etc/keepalived/keepalived.conf,编译的自然就在你设置的目录下了,如果你想看参数的意义,请搜索keepalived权威指南,这书很短,10分钟就够了,但是是绝对权威的~
1 主机: 2 ! Configuration File for keepalived 3 global_defs { 4 notification_email { 5 bfmq@example.com 6 } 7 notification_email_from keepalived@example.com 8 smtp_server 127.0.0.1 9 smtp_connect_timeout 30 10 router_id haproxy_ha 11 } 12 13 vrrp_instance haproxy_ha { 14 state MASTER 15 interface eth0 16 virtual_router_id 36 17 priority 150 18 advert_int 1 19 authentication { 20 auth_type PASS 21 auth_pass 1111 22 } 23 virtual_ipaddress { 24 192.168.56.21 25 } 26 }
1 备机: 2 ! Configuration File for keepalived 3 global_defs { 4 notification_email { 5 bfmq@example.com 6 } 7 notification_email_from keepalived@example.com 8 smtp_server 127.0.0.1 9 smtp_connect_timeout 30 10 router_id haproxy_ha 11 } 12 13 vrrp_instance haproxy_ha { 14 state BACKUP 15 interface eth0 16 virtual_router_id 36 17 priority 100 18 advert_int 1 19 authentication { 20 auth_type PASS 21 auth_pass 1111 22 } 23 virtual_ipaddress { 24 192.168.56.21 25 } 26 }
我们启动后会发现主机成功备机失败,wtf,这是什么情况?那是因为我们需要更改一个内核保护参数,/proc/sys/net/ipv4/ip_nonlocal_bind,顾名思义,是否需要绑定非本地ip,因为我们的虚拟ip不是本地ip嘛,默认是0我们改成1,就可以了,此时主备机之间就建立了不可描述的关系~~~,停掉主机,备机会即可接管虚拟ip,速度极快我们根本感觉不到,如果你一直ping虚拟ip的话你可能会看到会顿上很小的毫秒数,我们的负载均衡器实现了高可用,这个虚拟ip是干嘛的?其实这个虚拟ip有两个作用,为负载均衡集群准备,再者它就是你的整个对外的ip了,也就是用户只需要访问此ip就可以了,后面的他不需要知道
再说负载均衡集群,注意是集群,实现负载均衡的方式有很多,网卡,dns,链路算,但是我们这里讨论服务器集群,组建服务器集群有软硬件两种方式,硬件使用F5跟Array,然而都不便宜,尤其是F5,价格真是顶小北方几年工资了,so,我们还是整软件吧~软件也分为两种
四层负载:转发,维护一条tcp连接
七层负载:代理,维护两条独立的tcp连接
四层负载的lvs是很有名气的,它有四种模式,十多种算法,几乎支持任何场景,我们列举四种模式需要注意的点就好了
1 NAT:他的瓶颈在于后端主机的路由必须为调度器,这样才能保证回包时再通回调度器,因此进出都需要调度器来进行转发,网卡流量扛不住。它比dr慢,但是这并不是致命缺点,其实这个所谓的“慢”几乎可以忽略不计的 2 TUN:几乎没人用了,还得打专线... 3 DR:后端服务器都要绑定VIP并拒收VIP的访问包,需要调度器与真机在一个vlan段内 4 FULL-NAT:你需要会跟ospf结合,并且编译阿里的内核
我所知道的10种算法
1.轮叫调度(Round Robin)(简称rr) 调度器通过“轮叫”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。 2.加权轮叫(Weighted Round Robin)(简称wrr) 调度器通过“加权轮叫”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器能处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。 3.最少链接(Least Connections)(LC) 调度器通过“最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用“最小连接”调度算法可以较好地均衡负载。 4.加权最少链接(Weighted Least Connections)(WLC) 在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。 5.基于局部性的最少链接(Locality-Based Least Connections)(LBLC) “基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近 使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。 6.带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)(LBLCR) “带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个 目标 IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器 组,按“最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台 服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程 度。 7.目标地址散列(Destination Hashing)(DH) “目标地址散列”调度算法根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。 8.源地址散列(Source Hashing)(SH) “源地址散列”调度算法根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。 9.最短的期望的延迟(Shortest Expected Delay Scheduling SED)(SED) 基于wlc算法。这个必须举例来说了 ABC三台机器分别权重123 ,连接数也分别是123。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用sed算法后会进行这样一个运算 A(1+1)/1 B(1+2)/2 C(1+3)/3 根据运算结果,把连接交给C 10.最少队列调度(Never Queue Scheduling NQ)(NQ) 无需队列。如果有台 realserver的连接数=0就直接分配过去,不需要在进行sed运算
再来七层负载haproxy,它的配置文件在/etc/haproxy/haproxy.cfg
1 主机备机 2 global 3 maxconn 100000 4 chroot /var/lib/haproxy 5 user haproxy 6 group haproxy 7 daemon 8 nbproc 1 9 pidfile /var/run/haproxy.pid 10 stats socket /var/lib/haproxy.sock mode 600 level admin 11 log 127.0.0.1 local3 info 12 13 defaults 14 option http-keep-alive 15 maxconn 100000 16 mode http 17 timeout connect 5000ms 18 timeout client 50000ms 19 timeout server 50000ms 20 21 listen stats 22 mode http 23 bind 0.0.0.0:8888 24 stats enable 25 stats uri /haproxy-status 26 stats auth haproxy:bfmq 27 28 frontend frontend_www_example_com 29 bind 192.168.56.21:80 30 mode http 31 option httplog 32 log global 33 default_backend backend_www_example_com 34 35 backend backend_www_example_com 36 option forwardfor header X-REAL-IP 37 option httpchk HEAD / HTTP/1.0 38 balance roundrobin 39 server web-node1 192.168.56.11:8080 check inter 2000 rise 30 fall 15 40 server web-node2 192.168.56.12:8080 check inter 2000 rise 30 fall 15
很明显我们监听的就是刚才虚拟ip192.168.56.21并将关于它80端口的访问转发到了两台web机器上,这两台机器的ip是真实存在的,并且也是提供了相应的端口服务
haproxy的算法(百度的~):
① roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的; ② static-rr,表示根据权重,建议关注; ③ leastconn,表示最少连接者先处理,建议关注; ④ source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注; ⑤ ri,表示根据请求的URI; ⑥ rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name; ⑦ hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求; ⑧ rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
关于haproxy如何动态的启用禁用配置那就需要我们配置的/var/lib/haproxy.sock了,我们直接对sock进行通信需要用到socat这个包
1 echo "disable server backend_www_example_com / web-node1" | socat /usr/local/haproxy/haproxy.sock stdio 2 echo "enable server backend_www_example_com / web-node1" | socat /usr/local/haproxy/haproxy.sock stdio
当然他还有其它的功能echo "help"| socat stdio /usr/local/haproxy/haproxy.sock可以自行查看,十分实用!
好了,haproxy的基本安装就这样,我们该对他进行优化了,在此之前我们还是要先把单机上本身该做的事情都做了哦,这样其实就已经优化的不错了。但是我们记得不论如何优化端口范围是死的。
But,haproxy是专业的反向代理负载均衡调度器,它可以扩展多个IP以充分利用以扩大我们的端口范围
1 server web-node1 192.168.56.11:8080 check source 192.168.56.100:10000-65000 2 server web-node2 192.168.56.11:8080 check source 192.168.56.101:10000-65000
这样我们就的端口范围就直接扩展了一倍,当然,我们可以继续添加ip扩展