算法概述
- 优点:计算复杂度不高,榆出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据范围: 数值型 和 标称型 。
算法流程
- 数据
- 样本数据(多维多行数据 + 标签)
- 预测数据(多维一行数据)
- 构建决策树
- 遍历数据集每一个 feature ,计算信息熵的增益
- 选择信息增益最大的 feature 作为树的节点
- 数据集按照 feature 值进行分组,对于每一个分组再次进行 1.2.3.递归计算
- 递归出口
- 只剩下一个 feature 无法再分
- labels 都一样,无论 feature 什么样都不影响 labels 了
- 递归出口
-
决策树预测
- 按照决策树结构进行预测数据的判断直到叶子结点
-
熵的计算公式
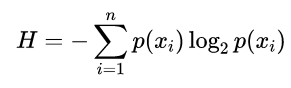
代码示例
import collections
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
def calcShannonEnt(dataCol):
"""
信息熵
H = -pi * log2( pi )
pi 为第 i 个值在所有值中出现的概率
:param dataSet:
:return:
"""
labelNum = dataCol.shape[0]
labelCounts = {}
for label in dataCol:
if label not in labelCounts.keys():
labelCounts[label] = 0
labelCounts[label] += 1
entroy = 0.0
for label, count in labelCounts.items():
# 标签值在所有值中的概率
prob = count / labelNum
entroy -= prob * math.log(prob,2)
return entroy
class DecisionTree:
def __init__(self, dataSet, labels):
self.tree = self.createTree(dataSet, labels)
self.numLeafs = self.getNumLeafs(self.tree)
self.deapth = self.getTreeDepth(self.tree)
def splitDataSet(self, dataSet, axis, value):
"""
划分决策树,抽取符合条件的数据
:param dataSet:
:param axis:
:param value:
:return:
"""
reDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reDataSet.append(np.hstack((featVec[:axis],featVec[axis+1:])).tolist())
return np.array(reDataSet)
def chooseBestFeatureToSplit(self, dataSet):
"""
选取最优数据集划分方式构建决策树
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet[:,-1])
bestInfoGain, bestFeature = 0.0, -1
for i in range(numFeatures):
featList = dataSet[:,i]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = self.splitDataSet(dataSet, i, value)
prob = len(subDataSet) / len(dataSet)
# 熵 = 选择的决策占比概率 *
newEntropy += prob * calcShannonEnt(subDataSet[:,-1])
infoGain = baseEntropy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(self,classList):
"""
找到出现次数最多的 class
:param classList:
:return:
"""
return collections.Counter(classList).most_common(1)[0][0]
# classCount = {}
# for vote in classList:
# if vote not in classCount.keys():
# classCount[vote] = 0
# classCount[vote] += 1
# sortedClassCount = sorted(classCount.items(), key=lambda x: x[1], reverse=True)
# return sortedClassCount[0][0]
def createTree(self, dataSet, labels):
"""
构建决策树
:param dataSet:
:param labels:
:return:
"""
classList = dataSet[:,-1]
# 如果所有数据的 feature 都一样,返回 feature
if np.unique(classList).size == 1:
return classList[0]
# 如果只有一个 feature ,返回出现最多的 class
if len(dataSet[0]) == 1:
return self.majorityCnt(classList)
# 选择一个 feature,使得信息增益最大
bestFeat = self.chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 取出这个 feature 下的所有 class 作为分类标准
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
# 递归创建决策树
myTree[bestFeatLabel][value] = self.createTree(
self.splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def getNumLeafs(self, myTree):
numLeafs = 0 #初始化叶子
# firstStr = list(myTree.keys())[0]
firstStr = next(iter(myTree))
secondDict = myTree[firstStr] #获取下一组字典
for key in secondDict.keys():
if isinstance(secondDict[key], dict):
numLeafs += self.getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(self, myTree):
maxDepth = 0 #初始化决策树深度
firstStr = next(iter(myTree))
secondDict = myTree[firstStr] #获取下一个字典
for key in secondDict.keys():
if isinstance(secondDict[key], dict): #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
thisDepth = 1 + self.getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth #更新层数
return maxDepth
def classify(self, inputTree, labels, testVec):
"""
分类预测
:param inputTree: 决策树
:param labels: 数据标签
:param testVec: 测试数据
:return:
"""
firstStr = next(iter(inputTree)) #获取决策树结点
secondDict = inputTree[firstStr] #下一个字典
featIndex = labels.index(firstStr)
for key in secondDict.keys():
if str(testVec[featIndex]) == key:
if isinstance(secondDict[key],dict):
classLabel = self.classify(secondDict[key], labels, testVec)
else: classLabel = secondDict[key]
return classLabel
if __name__ == "__main__":
dataSet = [[0, 0, 0, 0, 'no'], # 数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] # 特征标签
DTree = DecisionTree(np.array(dataSet), labels[:])
print("tree: ",DTree.tree)
print("leaf nums: ",DTree.numLeafs)
print("deapth: ",DTree.deapth)
print("classify: ", DTree.classify(DTree.tree, labels, [3,1,0,"yes"]))