论文地址 :https://www.aclweb.org/anthology/P19-1481/
作者 :Vishwajeet Kumar, Nitish Joshi, Arijit Mukherjee, Ganesh Ramakrishnan, Preethi Jyothi
机构 : IITB-Monash Research Academy
研究的问题:
关注的是跨语言的自动问题生成。利用数据丰富的语言来帮助数据缺少的语言完成问题生成任务。方法是使用降噪自编码器(DAE)和反向翻译(back translation)完成模型的预训练,之后进行监督学习,使用各自数据进行训练,模型在编码器部分和解码器部分会共享部分参数。同时作者构建了一个新的印度语的问题生成数据集HiQuAD。
研究方法:
如前所述,模型的训练分为无监督的预训练和有监督的训练,整体的框架如下。
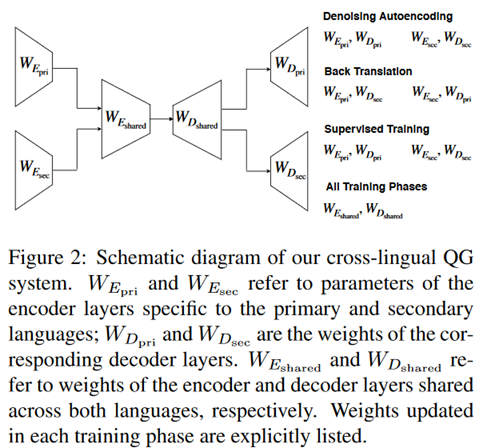
模型包括两个特定于某种语言的编码器和两个解码器,使用Transformer实现,每个编码器和解码器都有四层,两层独立训练,两层以共享的方式训练。
无监督的预训练:
使用第一语言(印度语或中文)和第二语言(英语)作为数据,使用降噪自编码器(DAE)和反向翻译(back translation)进行预训练。
DAE:把句子中的单词顺序打乱作为输入,目的是防止模型简单地复制每个单词。训练目标就是重排句子。
反向翻译:给定一个句子x,生成它的一个翻译x‘,然后使用x‘去生成原始的x。
有监督的训练过程:
首先定义问题为一个端到端的生成任务,具体就是给定一个输入句子,输出是一个语法正确、语义一致的相关的问题,使用的是与输入相同的语言。
所以这里就是分别使用在第一语言的数据上训练第一语言的编码器解码器,在第二语言的数据上训练第二语言的编码器解码器。
一些细节:
(1)位置掩码:类似于transformer模型,使用三角函数表示位置信息。不过这里定义了一个前向和后向的mask,为了表示时间顺序信息。
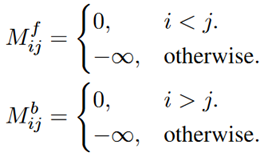
(2)权重共享:也就是如前所述的,每个编码器和解码器都有四层,两层独立训练,两层以共享的方式训练。
(3)BPE:并不是使用字级别的embedding,而是用的BPE(字节对编码)。
实验部分:
先介绍一下他们构建的这个印度语数据集,包括1334段话6566个问答对。
对于前边提到的这个训练过程的,它是需要4个数据集的。两个单语语料库,用于两种语言的无监督的预训练。然后两个问答数据集,分别用于两种语言的有监督的预训练。这里作者分别在以印度语和中文为第一语言,以英语为第二语言展开实验。
评估指标包括BLEU1-4、METEOR、ROUGE-L
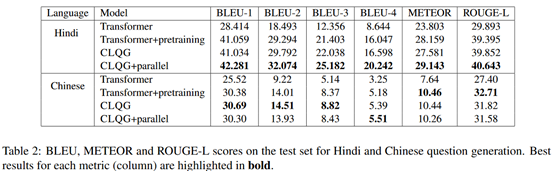
这里的CLQG就是作者的模型,CLOG+parallel是作者在预训练之后,再使用一个翻译任务(如中文到英语)进一步对网络fine-tune,相当于多了一个阶段。可以看到多了这个阶段在印度语上提升比较明显,但是在中文上并没有提升。作者认为他们找的这个中文的翻译语料库数据量太少,而且只是新闻领域的数据,所以影响了效果。
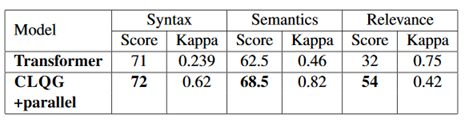
作者还做了人工评估,找了三个人来标,结果如下。
作者还讨论了预训练和辅助语言的设置对实验的提升效果。

可以看到,预训练所带来的提升非常明显,再增加的翻译任务对于结果略有提升,不过第二语言的设置对结果提升较小。
评价:
在问题生成这个任务上引入第二语言来辅助训练。模型本身创新较少,使用的BPE、位置掩码、权重共享都是比较经典方法。但实际上,从表5来看,这个第二语言所带来的提升非常的有限。并且从表2中看到,模型相比于基础的、预训练后的Transformer的结果几乎没有提升。在权重共享的训练中,编码器和解码器各自有两层独立训练,两层以共享的方式训练,作者认为保留单独的层来学习语言自身的信息是很重要的,但这里一半的参数不参与共享训练是否会影响效果的提升?而且可以看到,作者在实验部分增加的一个额外的翻译任务,在印度语上提升较小,在中文上性能反而下降,不知道这部分数据如果直接用于原来的预训练过程,效果是否同样会有这样的提升?