论文地址 :https://arxiv.org/abs/1905.06401v1
作者 :Grzegorz Chrupała, Afra Alishahi
机构:Tilburg University
已有研究工作:
在神经网络的分析中,最常用的方法是诊断模型(diagnostic models)。具体是使用针对特定任务训练的神经网络的中间层作为另一个模型的输入,如果另一个模型在这个任务上表现很好,就说明原模型对于信息做了很好的编码。
本文的工作和创新点:
提出了两种对于语言模型的分析方法,分别是RSA(Representational Sililarity Analysis)和TK(Tree Kernels),允许我们量化在神经网络模型中编码的信息与符号结构(如语法树)表示的信息的一致性。
研究方法:
RSA:用来衡量两个不同的分布空间的联系。具体地,提取出相似性矩阵,作二阶分析,提取出它们的上三角矩阵并计算相关系数。
本文中将RSA用来寻找语言中字符串的神经网络表示和这些字符串的结构化符号表示的关系的问题中,这里需要引入TK来捕获结构属性。TK的定义如下:给定一个函数K,它计算树t1和t2之间共同树段的原始数量,公式如下:
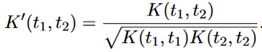
RSA_regress:RSA是度量两种不同的表示的全局相似性,相比之下诊断模型回答了一个更具体的问题,从给定的表示中可以多大程度地提取特定类型的信息。RSA_regress是结合了诊断模型特点的RSA方法。在得到了两个分布的相似度矩阵后,使用一个多变量线性回归模型来拟合它们。具体地说,对于一个使用L2正则化的模型,在预测和真实数据之间使用交叉验证的方法得到Pearson’s correlation。
实验一:使用人工语言
目前对于神经网络分析方法的评估还是一个开放性的问题,以往多使用一些定性的方法。本文定义了一种简单的算术表达式语言来对模型评估。
首先介绍语言,是一个由加减法构成的模10的表达式组成的。比如对于((6+2)-(3+7)),求它的值包括两个子表达式,左边的结果是8,右边的结果是0,整个表达式的值是8.下表给出了这项语言的上下文无关语法和语义评估规则。

下图是这种语言的语法树。

使用三个RNN模型来处理算术表达式,它们的encoder是公用的,是一个可训练的输入符号的查找表的和一个单层LSTM。最后一个的RNN cell的隐藏层的状态作为整个输入的表达。
1、语义评估。从编码器中获得表示的输入,预测表达式的值,损失函数是均方误差。
2、树深度。类似于语义评估模型,它预测的是语法树的深度。
3、中缀到前缀。生成表达式的前缀形式,损失函数是交叉熵损失函数。
之后使用RSA将这三个模型关联起来,使用余弦函数作为度量标准。具体如下:
1、语义值。作为语义评估模型的目标,使用0-9这样的绝对差来衡量。
2、深度。同样使用绝对差作为差异度量,最小为0,没有上限。
3、TK。两颗语法树之间相似度的估计,度量值在0-1之间。
实验结果:

可以看到RSA方法起到了与诊断模型相同的作用。
实验二:使用自然语言
使用RSA来比较自然语言句子的树状表示和sentence embedding得到的神经表示。这里的encoder使用了词袋模型、infersent和BERT三种。实验结果如下:
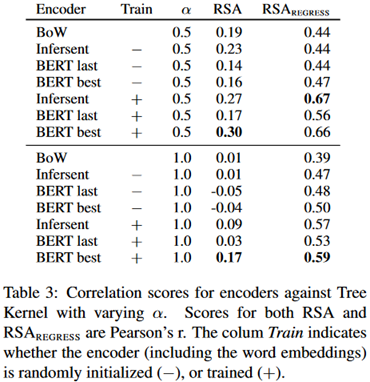
可以看到BERT的结果是最好的,这也和我们的常识相吻合。
评价:
关注的是语言模型的评价方法的问题,提出两种方法来关联语言的神经表征和句法表征,使用tree kernel来衡量句法树之间的相似性。从实验结果来看,确实起到了与人工方法类似的作用。