论文地址:https://www.aclweb.org/anthology/Q19-1011/
已有研究工作:
之前的研究工作没有将文本分割和文档分类在整个文档级别上联合进行过;在数据集方面,缺少主题漂移情况的数据。
本文的工作和创新点:
1、提出了一个端到端的模型SECTOR,它可以将文档分割为连贯的部分,从句子级别上预测而局部主题,给每个部分分配主题标签。
2、制作了WikiSectioin,一个公开的数据集,包括242k个有标记的英文和德文文章,主题包括疾病和城市。
任务的示意图如下:
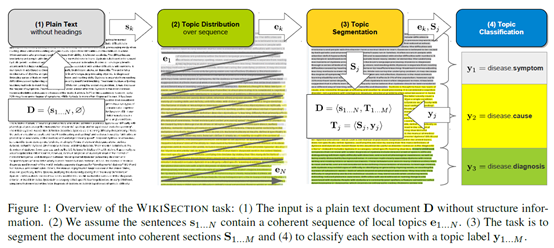
研究方法:
数据集的创建方面:
WikiSection,包含38k个英语、德语维基百科全文文档,原数据通过查询过滤得到关于疾病和城市的文章,包括了文章摘要、正文的纯文本、维基百科编辑给出的所有章节的位置和原始标题和一个规范化的主题标签,训练集、验证集、测试集的划分比例为7:1:2。
在预处理阶段,去除了除换行符和列表以外的其他符号。下表是疾病相关文档的统计。
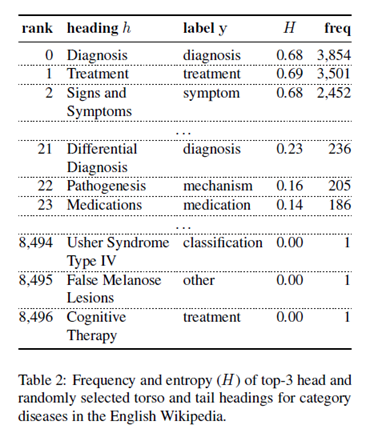
观察发现,有88%的标题只出现了1到两次,因此通过聚类的方法将标题聚类为少数的、有代表性的标签。
模型部分:
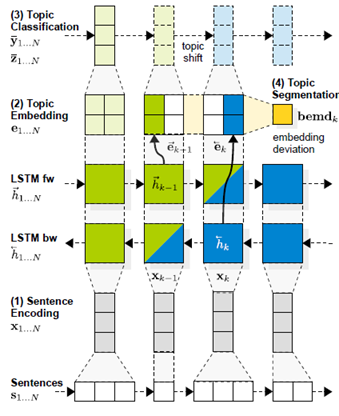
模型主要包括四个部分:句子编码、主题嵌入、主题分类、主题分割。示意图如下:
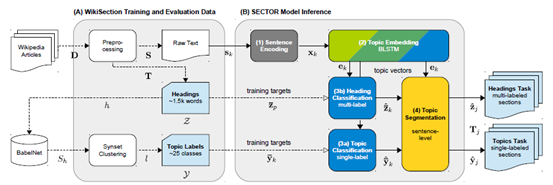
句子编码:目标是将每个句子从文本表示转为一个固定大小的句子向量作为输入。方法有以下三种:
1、bag-of-words编码。作为baseline,也就是用一个加权的bag-of-words组成句子向量。公式如下:
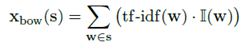
2、布隆过滤器。如果词汇表过大或文档过长,第一种方法就不适合了。因此使用了稀疏句子向量压缩的布隆过滤器方法,将其映射到位数组上。公式如下:
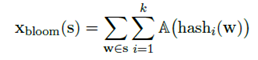
3、句子向量。使用word2vec的句子表示。
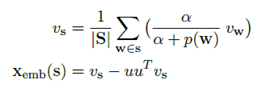
主题嵌入:目标是为文档的每个句子生成一个潜在的主题分布向量,具体方法是使用一个两层的LSTM网络。
主题分类:在之前得到的句子向量的基础上,使用softmax分类。
主题分割:完成对文档的分段和每个部分的分类。
Baseline方法:合并相邻的、主题相同的句子,直到整个文档完成分段。
改进方法:由于文档中每个句子分类所需的全部信息都包含在主题嵌入矩阵中,问题就转化为这个嵌入矩阵在句子序列上的向量空间运动。因此,应用Laplacian-of-Gaussian边缘检测来获得每个句子向量的偏差大小。具体就是,首先通过PCA降维,再用高斯平滑来获得平滑矩阵,再利用余弦距离逐步计算差分值,找到运动最快的点作为分割点。
再次改进:LSTM的前向层和后向层的编码存在差异,分别考虑前向层和后向层的差分值,取其几何平均值。
整体的流程如下图所示:
评价:
文章的模型SECTOR,主要特点是一个端到端的模型,将文本分割和文本分类两个任务结合在了一起。优点在于实验比较充分,在句子编码上就尝试了三种不同的方法,缺点在于模型本身的实现方面的创新性较少,。另外本文构造了一个可以用于主题分类的英文和德语的数据集。