论文地址:https://arxiv.org/abs/1907.05190?context=stat.ML
已有研究工作:
在主动强化学习框架中,已经解决了将查询成本纳入强化学习的问题。对于主动强化学习,它的核心问题是量化reward信息的长期价值,但通常假定每一轮的每个动作的cost都是固定的;当前考虑了cost需要变化的工作,没有考虑到多种的feedback形式的cost应当是不同的。
本文的创新点:
本文关注的是端到端学习中不同类型的反馈对于学习成本(cost)和影响(effect)的问题,提出了一种使用自我管理(self-regulated)的机器学习算法。
研究方法:
那么首先,什么是自我管理的学习方法。它的任务是在人工监督(human effort)和输出质量(output quality)中寻找最优的平衡点,选择最优的feedback的自动学习机制。也就是将自我管理的学习方法建模为带动态代价的主动强化学习问题。对于接受的一个输入,regulator选择一种feedback,这种feedback是有代价的,learner从人类获得feedback后来提升自己的生成质量,通过对于regulator的惩罚或者强化,regulator可以加强对于后来输入所需的feedback种类的选择能力。
关于feedback:
这里的feedback包括以下几类:
Corrections: 人类提供完整的修改后的reference。
Error marking: 对于输出的正确与否的标记,将正确的标记为1,将错误的标记为0。
Self-supervision: 从自己的输出中学习,也就是从自我监督中学习。最简单的方法是直接把输出当做是正确的,这样会导致模型退化。本文用的方法是Clark提出的一种跨视角训练方法,将学习者的原理预测用作与原始模型共享参数的较弱模型的目标,在弱化模型下最小化原目标的最大似然。
Combination: 这个选项的意思是忽略当前输入。
各种情况下的梯度计算如下图所示。

下面这张图表示了整体的流程。
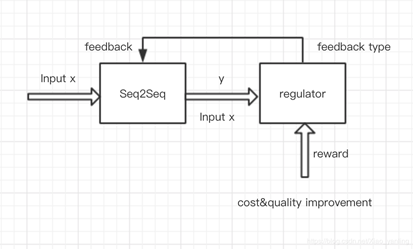
以及其算法过程描述:

实验部分:
实验部分主要讨论了三个问题,在翻译任务上测试表现:
- Regulator制定了哪些策略?
- 一个训练好的regulator迁移到其他领域的结果如何?
- 这些策略相比于单一反馈类型的学习相比,结果如何?
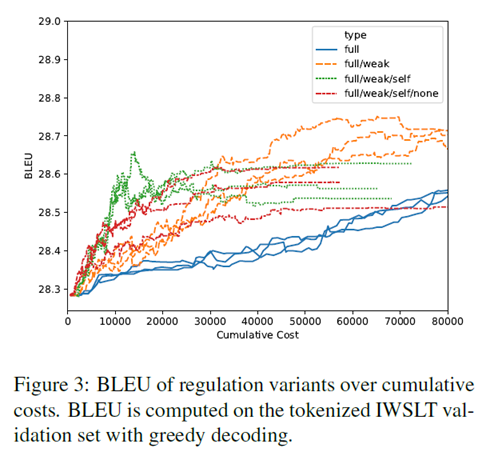
这里的baseline,也就是蓝线,表示只有correction的模型,可以看到的是黄色的取得了最高的bleu分数,绿色的最快地取得了较好的分数,因为它提供了一个额外的、更便宜的反馈选项。而红色的可以看出,跳过的这个选项不会带来任何的收益。
评价:
在本文中也提到了,该方法其实是贪心策略的一种应用,在端到端模型中,在成本和质量之间取得trade-off,也就是让模型学会何时获得何种feedback。实验部分比较充分,关于提出的三个问题设计实验。另外从实验结果上看,它在领域迁移上的表现也很好。该模型可以拓展加入更多的feedback方式从而得到更加广泛的结论。本文的端到端模型使用LSTM实现,如果使用多种实现方式会让实验更有说服力。