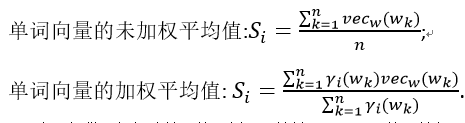摘要
1.作者提出了一种新的简单有效的方法,用于学习词义嵌入word sense embedding
2.传统的两种方法:(1)直接从语料库中学习词义;(2)依赖词汇资源的语义库
研究方法的创新点:通过聚类相关词的自我网络ego-networks,从而在现有的词嵌入中引出语义库。
3.集成的WSD机制允许在学习到的语义向量的上下文中标记单词,从而产生下游应用
4.这种新式方法能够与现有的无监督WSD系统相媲美
介绍
在NLP应用中,密集向量形式的术语表示是非常有用的。首先,它们能计算语义相关的单词;另外,它们可以用来表示其他语言单元,如短语和短文,降低传统向量空间表示的固有稀疏性。
大多数词向量模型都把一个单词的各种含义混合成一个简单的单一向量,这是大多数词向量的一个局限性,也就是稀疏和密集表示的问题。为了解决这个问题,(Huang et al., 2012; Tian et al., 2014; Neelakantan et al., 2014; Nieto Pi ˜na and Johansson, 2015; Bartunov et al., 2016)等人,先后提出了几种用于学习多原型词向量的结构。而已有的迹象显示,多原型词嵌入能够改善文本处理程序的性能,例如词性标注和语义关系识别。
注:大多数词嵌入方法都是假定用每个词能够用单个向量代表,但是无法解决一词多义和同音异议的问题。多原型向量空间模型(Reisinger and Mooney 2010)是将一个单词的上下文分成不同的群(groups),然后为每个群生成不同的原型向量。遵循这个想法, (Huang et al. 2012) 提出了基于神经语言模型(Bengio et al. 2003)的多原型词嵌入。
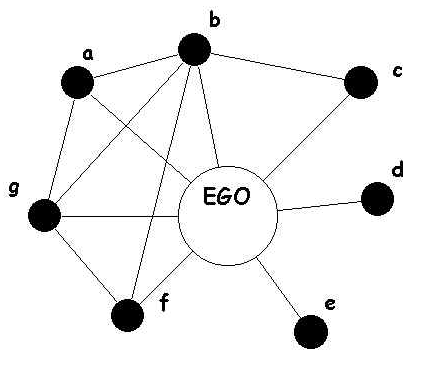
本文的贡献是一种学习词义向量的新方法。与先前的方法相比,该方法依赖于现有的单原型词嵌入,通过自我网络聚类,将词向量转换为语义向量。所谓的ego network,它的节点是由唯一的一个中心节点(ego),以及这个节点的邻居(alters)组成的,它的边只包括了ego和alter之间,以及alter与alter之间的边,其中,图里面的每个alter和它自身的邻居又可以构成一个ego network,而所有节点的ego network合并起来,就可以组成真实的social network了。
此外,本文方法中配有词义消歧WSD机制,因此上下文中的词可以可以映射到这些语义表示上。
本文所阐述的方法的一个优点是可以使用现有的词嵌入和/或现有的语义库来构建词义嵌入。这种方法与最先进的无监督WSD系统相当。
学习词义嵌入
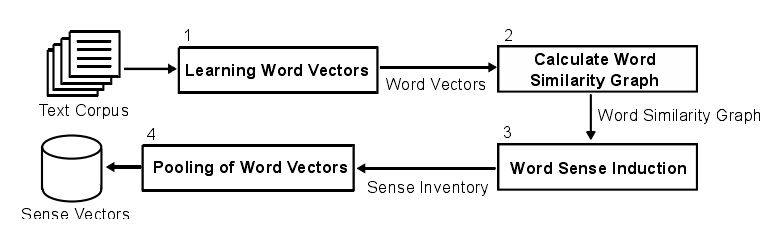
四个阶段:1.学习词向量 2.基于向量相似性构建最近邻居图 3.利用自我网络聚类归纳词义 4.关于语义归纳的词向量聚合
1.学习词向量
使用word2vec学习词向量,所训练的COBW词嵌入有100或300维,上下文窗口大小为3,最小词频为5。在训练时,修改了word2vec的标准实现,以便能够保存WSD方法之一所需的上下文向量。
2.计算词相似图
对于每个单词,检索其200个最近邻居,而只有少数几个词具有更强烈的语义相关词。词相似度图是基于前一步中学习的词嵌入或者使用JoBim Text框架所提供的语义相似性来计算的。
(1) word2vec
使用w2v提取情况下,词的最近邻居是各个词向量的最高余弦相似性的项。出于可伸缩性的原因,使用快向量乘法,使用1000个向量的块来执行相似度计算。
(2) JoBim Text
这是一种无监督的方法,每个词都表示为一组基于稀疏依赖性的特征,这种特征是使用Malt解析器提取的。使用LMI得分对特征进行归一化,接着对默认值进行进一步修剪。两个词的相似性等于共同特征的数量。
3.语义归纳
语义由单词簇表示,为了归纳语义,首先我们构建单词t的自我网络G,然后对该网络进行图形聚类。引用相同含义的词语倾向于紧密相连,而指向不同意义的词语的联系较少。
在算法1中呈现的语义归纳每次迭代便处理词相似图T中的一个字t。首先,检索自我网络G的节点V,这些是图T中t的N个最相似词。t本身不是自我网络的一部分。其次,将G中的节点连接到来自T的n个最相似的词。最后,自我网络与Chinese Whispers (CW)算法聚类。(注:CW是用来分割加权的无向图节点,CW算法的目标就是查找传播相同信息到相邻节点的节点组。)
由于该方法是无参数的,故不对词义的数量进行假设。
语义归纳算法有三个元参数:目标自我词 t 的自我网络大小N;自我网络连接(n)是允许邻居v在自我网络中具有的最大连接数;集群k的最小尺寸。参数n调整语义库的粒度。
词义聚类中的每个单词的权重等于该词与其模糊词 t 之间的相似性得分。
4.词向量池化
这个过程要计算归纳语义库中每种语义的语义嵌入。假设一个词的词义是表示这种词义的词的组合。语义向量定义为表示集群项的词向量的函数。设W是训练语料库中所有单词的集合,让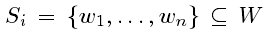 成为上一步中获得的语义聚类。考虑一个函数
成为上一步中获得的语义聚类。考虑一个函数 将单词映射到它们的向量和函数
将单词映射到它们的向量和函数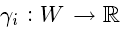
将集群词映射到集群Si中的权重。这里尝试了两种计算感测向量的方法: