一、爬虫基本原理
1.获取网络数据
用户方式:浏览器提交请求->下载网页代码->解析/渲染成页面
爬虫方式:模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
2.爬虫的基本原理
向网站发起请求,获取资源后分析并提取有用数据的程序
3.爬虫的基本流程
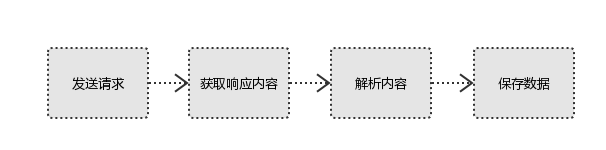
#1、发起请求
使用http库向目标站点发起请求,即发送一个Request,Request包含:请求头、请求体等
#2、获取响应内容
如果服务器能正常响应,则会得到一个Response,Response包含:html,json,图片,视频等
#3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
#4、保存数据
数据库,文件
4.request和response
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
5.Request
#1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
#2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
#3、请求头
User-agent:请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息
一般做爬虫都会加上请求头
#4、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
6.Response
#1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误
#2、Respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
#3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等