对于验证码这个问题,通常我们可以采取以下三个途径来解决该问题:
1、第一种方法,在被测系统中暂时屏蔽验证功能。
即临时修改应用,无论用户输入的是什么验证码,都认为是正确的。
优点:这种方法最容易实现,对测试结果也不会有太大的影响(当然,这种方式去掉了“验证验证码”这个环节,不过这个环节本来就很难成为系统性能瓶颈)。
缺点:但这种方法有一个致命的问题:如果被测系统是一个实际已上线的系统,屏蔽验证功能会对已经在运行的业务造成非常大的安全性的风险,因此,对于已上线的系统来说,用这种方式就不合适了;
2、第二种方法,留一个后门,我们设定一个所谓的“万能验证码”,只要用户输入这个“万能验证码”,我们就验证通过,否则,还是按照原先的验证方式进行验证。
这种方法在第一种方法的基础上稍微进行一些改进。第一种方法带来了很大的安全性问题,那么我们可以考虑,不取消验证,但在其中这种方式仍然存在安全性的问题,但由于我们可以通过管理手段将“万能验证码”控制在一个小的范围内,而且只在性能测试期间保留这个小小的后门,相对第一种方法来说,在安全性方面已经有较大的改进了;
3、写一个验证码获取的DLL,在测试脚本中进行调用即可。
验证码也在不断的进步。在获取验证码的时候,我们需要根据验证码的难易程度进行。
识别验证码:需要使用到pillow,pytesseract、tesseract-ocr.
pillow
PIL (Python Image Library) 是 Python 平台处理图片的标准库,兼具强大的功能和简洁的 API。但是目前PIL最新版本是1.1.7(PIL官方网站:http://www.pythonware.com/products/pil/)
该版本只支持python2.4、2.5、2.6、2.7。看了网上相关资料后,使用了Pillow。 Pillow 库则是 PIL 的一个分支,维护和开发活跃,Pillow 兼容 PIL 的绝大多数语法,推荐使用。
Pillow的Github主页:https://github.com/python-pillow/Pillow
Pillow的文档(对应版本v3.0.0):https://pillow.readthedocs.org/en/latest/handbook/index.html
Pillow的文档中文翻译(对应版本v2.4.0):http://pillow-cn.readthedocs.org/en/latest/
Pillow的安装:
方法一:在pycharm环境中直接安装。
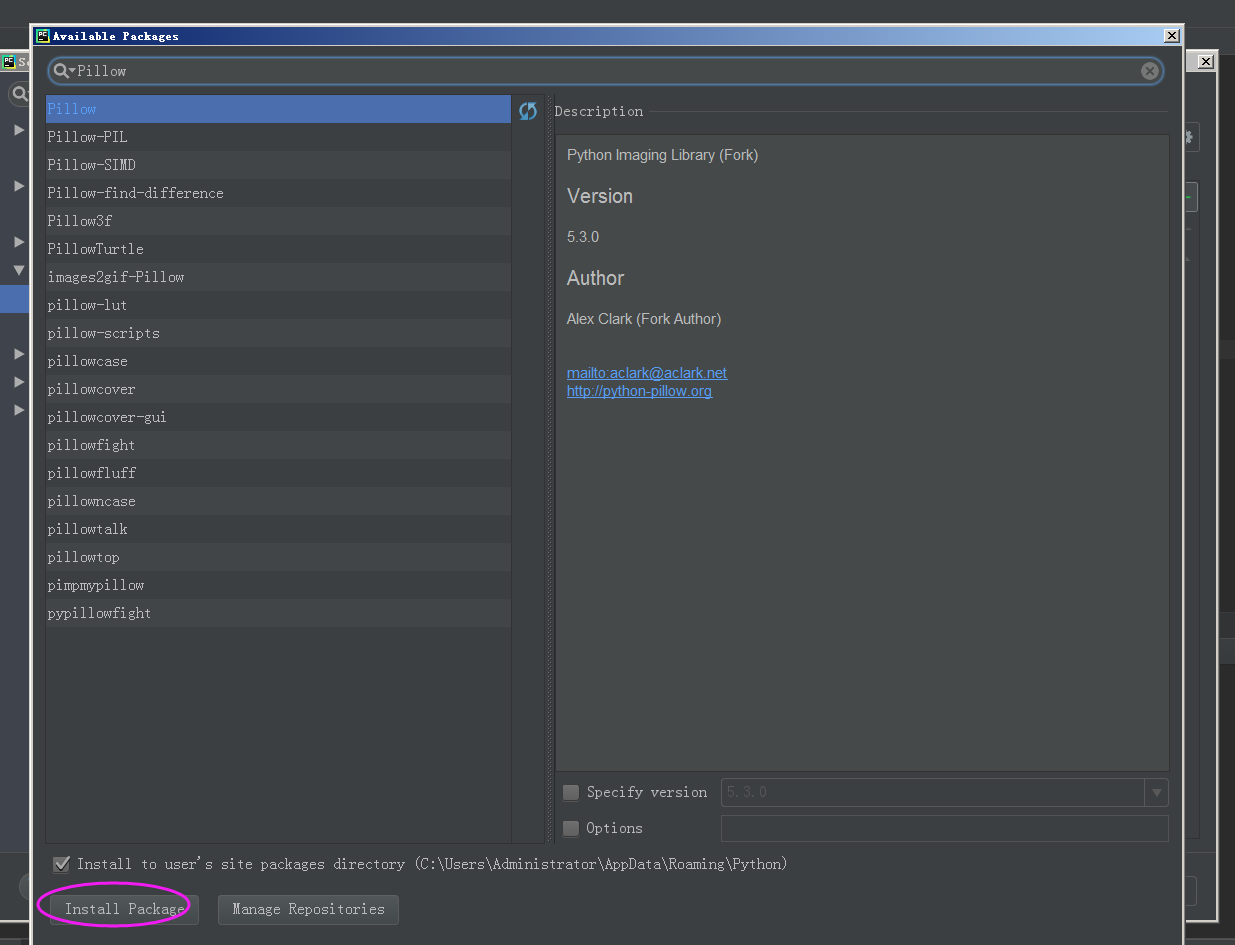
方法二:使用pip进行安装:pip install Pillow
pytesseract
pytesseract安装
方法一;
在pycharm环境中直接安装。
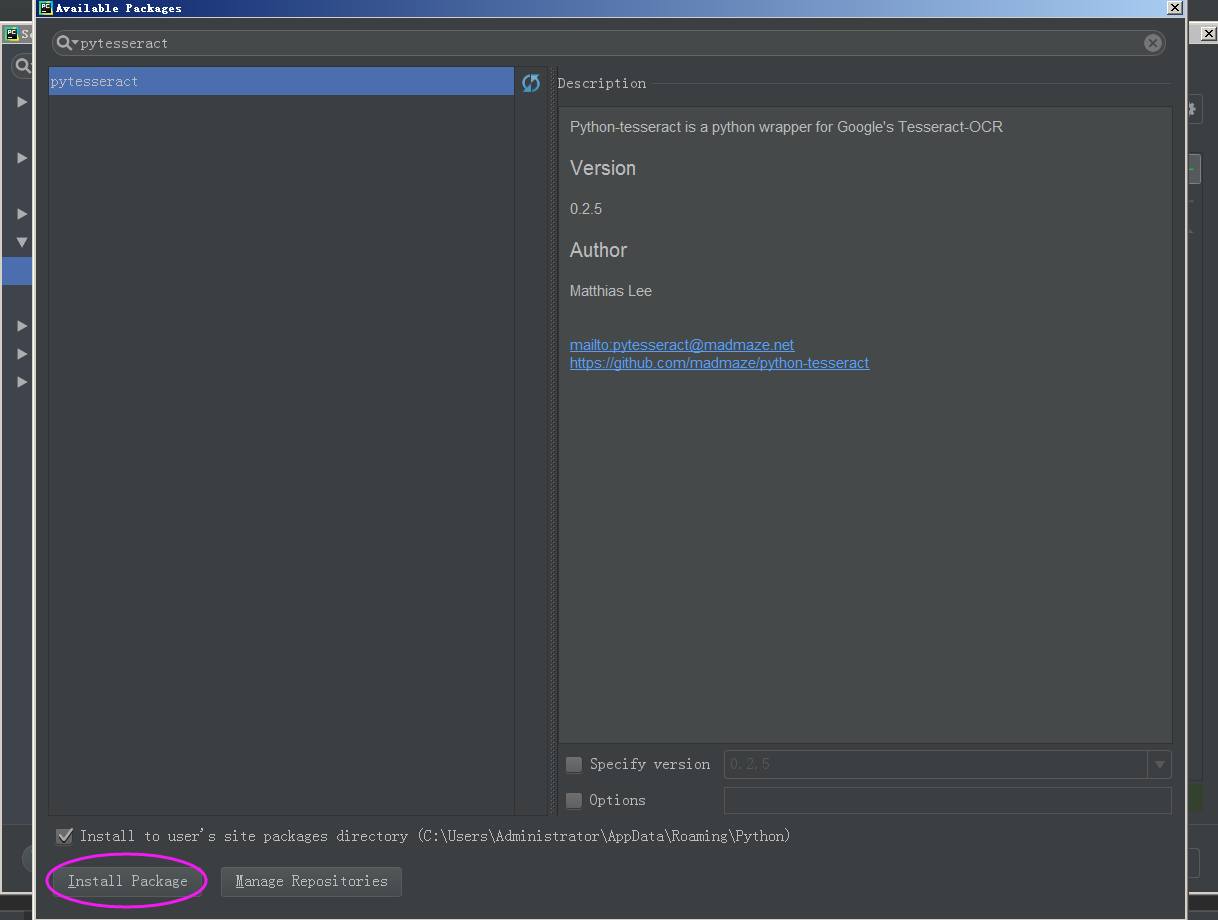
方法二:pip install pytesseract
真实案例的使用

代码如下:
from selenium import webdriver
import time
from PIL import Image
import pytesseract
driver=webdriver.Chrome()
driver.get("http://www.xxx.com/index.html#/user/login")
time.sleep(3)
driver.find_element_by_id('userName').send_keys("iotqy")#输入登录账户
driver.find_element_by_id("password").send_keys("123456")#输入登录密码
driver.save_screenshot('e://hbgj_login.png')#截取当前网页,该网页有我们需要的验证码
yzm=driver.find_element_by_xpath('//*[@id="root"]/div/div[1]/div[2]/div/form/div[1]/span/span/span[2]/div') #定位验证码
location=yzm.location#获取验证码x,y轴坐标
size=yzm.size#获取验证码的长宽
rangle=(int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))#截取的位置坐标
i=Image.open('e://hbgj_login.png') #打开截图
frame4=i.crop(rangle)#使用Image的crop函数,从截图中再次截取我们需要的区域
frame4.save("e://yzm.jpg")#将截取到的验证码保存为jpg图片
qq=Image.open("e://yzm.jpg")#打开jpg验证码图片
text=pytesseract.image_to_string(qq).strip()#使用image_to_string识别验证码
driver.find_element_by_name("code").send_keys(text)#将识别的图片验证码信息输入到验证码输入文本框中
driver.find_element_by_xpath('//*[@id="root"]/div/div[1]/div[2]/div/form/div[3]/div/div/span/button').click()#点击登录按钮
=====================================================================================================================================
出现的问题:
1、KeyError: 'RGBA'
OSError: cannot write mode RGBA as JPEG
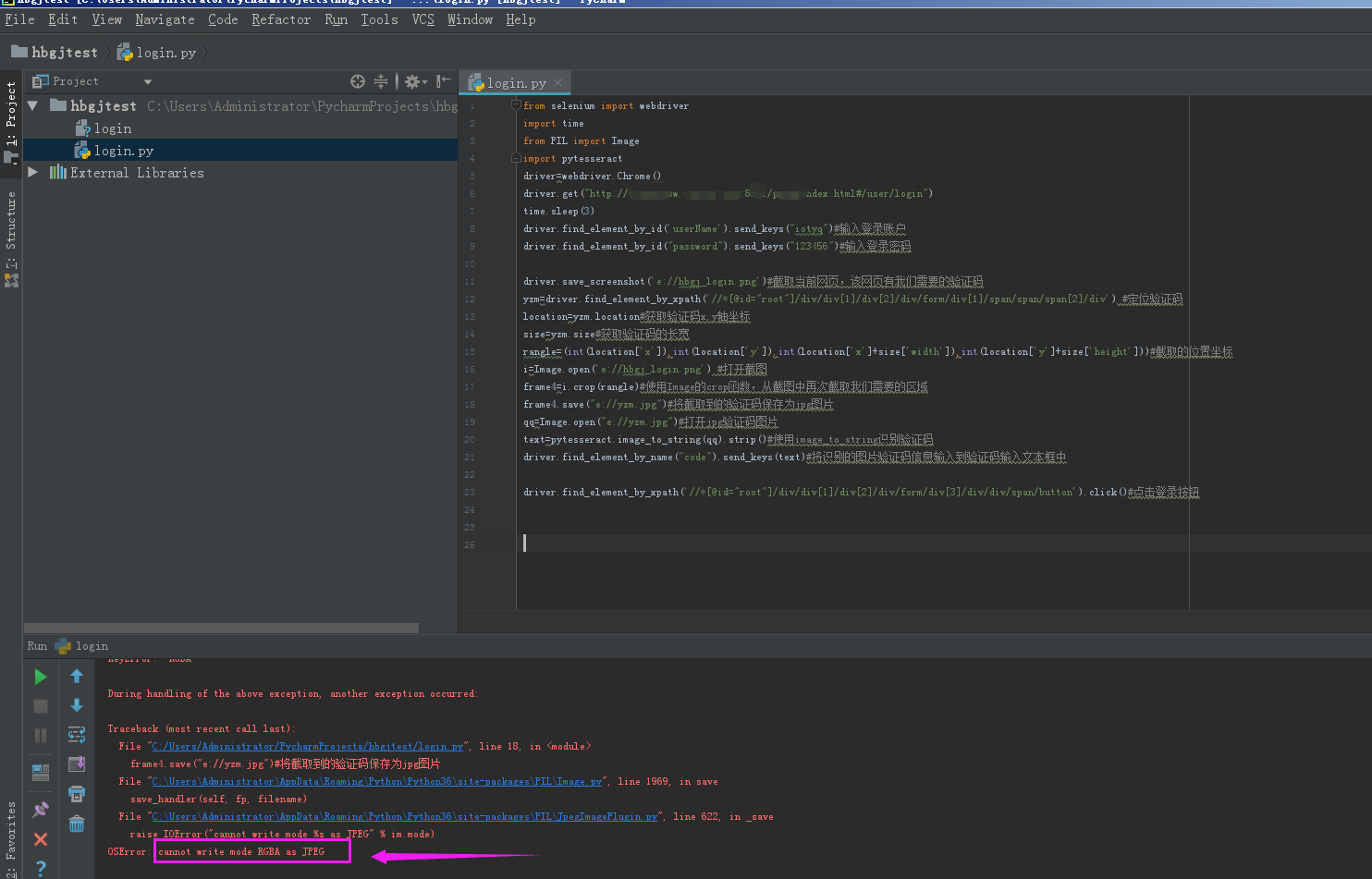
解决办法:将截取到的验证码由jpg格式改为png格式。
改动如下:

2、上诉改动后,出现新的错误
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
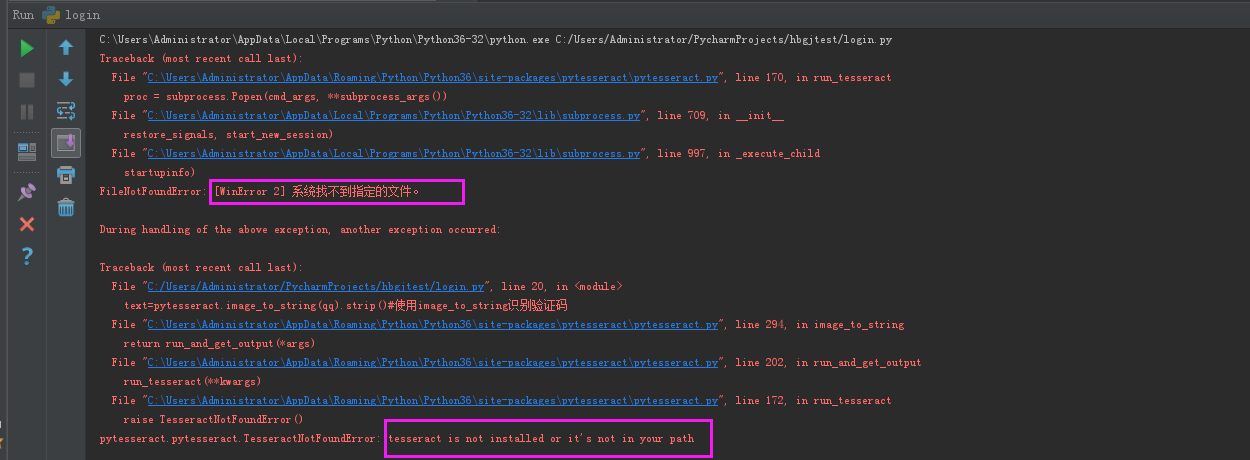
解决办法:安装tesseract-ocr
OCR(Optical Character Recognition, 光学字符识别) 软件
安装包含两个部分:ORC引擎本身以及对应语言的训练数据
github地址: https://github.com/tesseract-ocr/tesseract
windows:
The latest installer can be downloaded here: tesseract-ocr-setup-3.05.01.exe and tesseract-ocr-setup-4.00.00dev.exe (experimental).
下载安装包tesseract-ocr-setup-3.05.01.exe,安装到默认路径:C:Program Files (x86)Tesseract-OCR
安装tesseract-ocr完成后:处理方式中任选一。
①处理方法一:把安装路径(C:Program Files (x86)Tesseract-OCR)添加到环境变量PATH中去
②处理方法二:修改pytesseract.py文件,指定tesseract.exe安装路径
tesseract_cmd = 'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe‘
③处理方法三:在实际运行代码中指定
pytesseract.pytesseract.tesseract_cmd = 'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
OCR自动识别-识别验证码图片,识别过程:截取登录页面->获取验证码的位置坐标->打开截图->从截图中截取验证码的区域->使用pytesseract工具识别验证码