1、得到页面的HTML代码


第一个参数是URL
第二三个参数可以不传送,数据和时间
2、request请求
HTTP是基于请求和应答的,客户端发出请求,服务端做出响应,所以urllib2创建一个request对象,代表发送的HTTP请求。

3、数据传送POST和GET
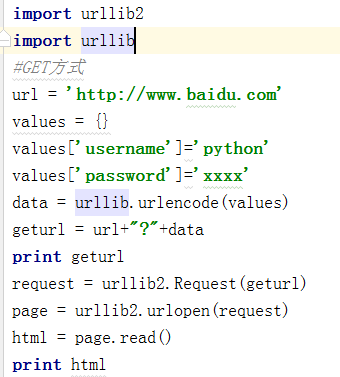
GET方式
直接把参数写到URL当中。
和我们平常GET访问方式一模一样,用一个问号连接传送的数据
POST方式

4、Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。

5、异常处理
【1】URLEeeor
产生的原因:
网络无连接
服务器不存在
连接不到服务器
在代码中,我们需要用try-except语句来包围并捕获相应的异常

【2】HTTPEeeor
每个来自服务器的HTTP应答都包含一个数值的状态码。有时候,状态码表明服务器不能满足我们做出的请求。默认的handlers将会帮我们处理一些应答(例如,应答是一个重定向,要求客户端从不同的URL抓取资源,urllib2将会替你处理好)。但是总有一些不能处理好,urloprn将会抛出一个HTTPError异常。典型的异常有404(页面丢失),403(请求被禁止),401(要求验证)


注意,HTTPError一定要放在最前面进行捕获。因为HTTPError是URLError的子集,不然的话会一直捕获到的是URLError

6、Cookie
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
但是URLopen只接受三个参数:url、data、timeout
urllib2库.官方文档翻译 - 莫利斯安的博客 - 博客频道 - CSDN.NET http://blog.csdn.net/u014343243/article/details/49308043