1、数据仓库warehouse一般不做更改,只做查询
2、OLTP:联机事务处理,比如:转账
OLAP:联机分析处理,比如:只做查询
3、hadoop的思想来源:
GFS (Google的文件系统)即分布式文件系统
4、MapReduce计算模型的来源:
Page Rank 即搜索排名
5、HBase数据库的来源:
BigTable 大表
6、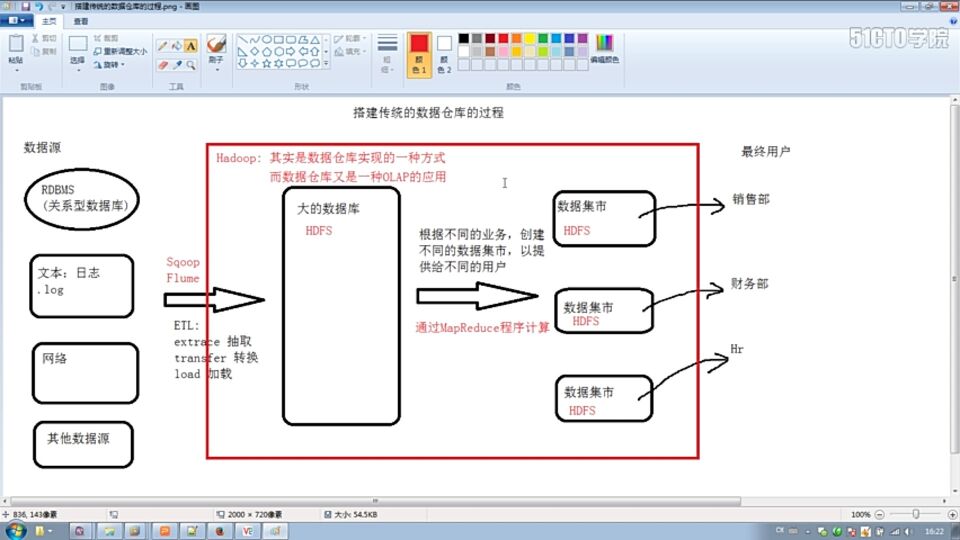
7、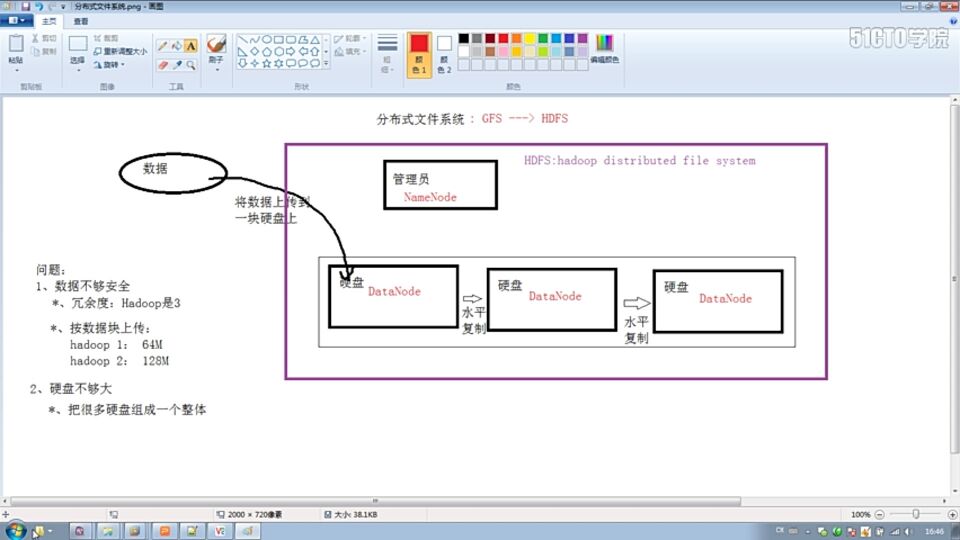
8、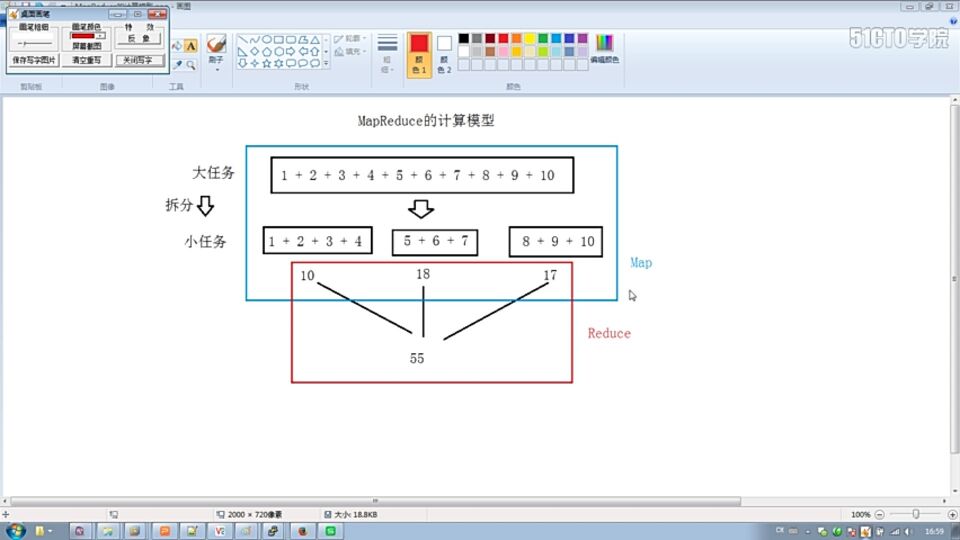
9、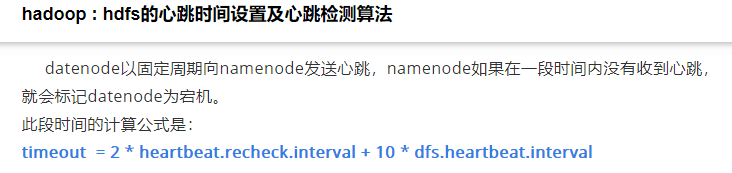

10、Hadoop五大守护进程(jobtracker、tasktracker、namenode、datanode、secondarynamenode)的三种启动与关闭方式
第一种启动方式:
进入【 Hadoop-1.x / bin】目录,执行start-all.sh,JPS查看进程,全部启动成功。
查看start-all.sh 代码发现:
# start dfs daemons
"$bin"/start-dfs.sh --config$HADOOP_CONF_DIR
# start mapred daemons
"$bin"/start-mapred.sh --config$HADOOP_CONF_DIR
start-all.sh启动是依赖于,start-dfs.sh 和 start-mapred.sh 两个启动文件,需要注意的是它的执行顺序,是先执行,start-dfs.sh 之后再执行 start-mapred.sh
第二种启动方式:
进入【 Hadoop-1.x /bin 】目录,执行start-dfs.sh 后再执行 start-mapred.sh,JPS查看进程,全部启动成功。
查看start-dfs.sh和 start-mapred.sh代码发现:
【start-dfs.sh】
# start dfsdaemons
# startnamenode after datanodes, to minimize time namenode is up w/o data
# note:datanodes will log connection errors until namenode starts
"$bin"/hadoop-daemon.sh--config $HADOOP_CONF_DIR start namenode $nameStartOpt
"$bin"/hadoop-daemons.sh--config $HADOOP_CONF_DIR start datanode $dataStartOpt
"$bin"/hadoop-daemons.sh--config $HADOOP_CONF_DIR --hosts masters start secondarynamenode
【start-mapred.sh】
# start mapreddaemons
# startjobtracker first to minimize connection errors at startup
"$bin"/hadoop-daemon.sh--config $HADOOP_CONF_DIR start jobtracker
"$bin"/hadoop-daemons.sh--config $HADOOP_CONF_DIR start tasktracker
值得注意的是start-dfs.sh 和 start-mapred.sh 的启动是依赖于hadoop-daemon.sh 和 hadoop-daemons.sh文件进行启动的;
注意其顺序,启动顺序依次为namenode、datanode、secondarynamenode、jobtracker、tasktracker
第三种启动方式:
进入【 Hadoop-1.x /bin】目录,命令如下:
【$ ./hadoop-daemon.sh namenode】
【$ ./hadoop-daemon.sh datanode】
【$ ./hadoop-daemon.sh secondarynamenode】
【$ ./hadoop-daemon.sh jobtracker】
【$ ./hadoop-daemon.sh tasktracker】
JPS查看进程,全部启动成功
第一种关闭方式:
调用stop-all.sh即可,原理同上
第二种关闭方式:
调用stop-mapred.sh再调用stop-dfs.sh 注意其执行顺序,原理同上
第三种关闭方式:
关闭顺序为:jobtracker、tasktracker、namenode、datanode、secondarynamenode
进入【 Hadoop-1.x /bin】目录,命令如下:
【$ ./hadoop-daemon.sh namenode】
【$ ./hadoop-daemon.sh datanode】
【$ ./hadoop-daemon.sh secondarynamenode】
【$ ./hadoop-daemon.sh jobtracker】
【$ ./hadoop-daemon.sh tasktracker】