信息存储
大多数计算机使用八位的块,或者字节,作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存的每个字节都由一个唯一的数字来标识,称为它的地址,所有可能地址的集合就称为虚拟地址空间。顾名思义,这个虚拟地址空间只是一个展现给机器级程序的概念性映像。实际的实现是将动态随机访问存储器(DRAM)、闪存、磁盘存储器、特殊硬件和操作系统结合起来,为程序提供一个看上去统一的字节数组。
在后面我们将讲述编译器和运行时系统是如何将存储器空间划分为更可管理的单元,来存放不同的程序对象,即程序数据、指令和控制信息。可以用各种机制来分配和管理程序不同部分的存储。这种管理完全是在虚拟地址空间里完成的。例如,C语言中一个指针的值(无论它指向一个整数、一个结构或是某个其他程序对象)都是某个存储块的第一个字节的虚拟地址。C编译器还把每个指针和类型信息联系起来,这样就可以根据指针值的类型,生成不同的机器级代码来访问存储在指针所指向的位置处的值。尽管C编译器维护着这个类型信息,但它生成的实际机器级程序并不包含关于数据类型的信息。每个程序对象可以视为一个字节块,而程序本身就是一个字节序列。
十六进制表示法
一个字节由八位组成,在二进制表示法中,它的值域时000000002~111111112。如果看成十进制整数,它的值域就是1010~25510。两种符号表示法对于描述位模式来说都不是非常方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是,以16位基数,或者叫做十六进制数,来表示位模式。十六进制(简写为“hex”)使用数字0~9以及字符A~F来表示十六个可能的值。图2-1展示了16个十六进制数字对应的十进制和二进制值。用十六进制书写,一个字节的值域为0016~FF16。

图2-1 十六进制表示法
以0x或0X开头的数字常量被认为是十六进制的值。字符'A'~'F'既可以 是大写,也可以是小写,甚至是大小写混合。
字数据大小
每台计算机都有一个字长,指明指针数据的标称大小。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小、也就是说,对于一个字长为w位的机器而言,虚拟地址的范围为0~2w-1,程序最多访问2w个字节。
C语言支持整数和浮点数的多种数据格式。图2-2展示了C语言各种数据类型分配的字节数:
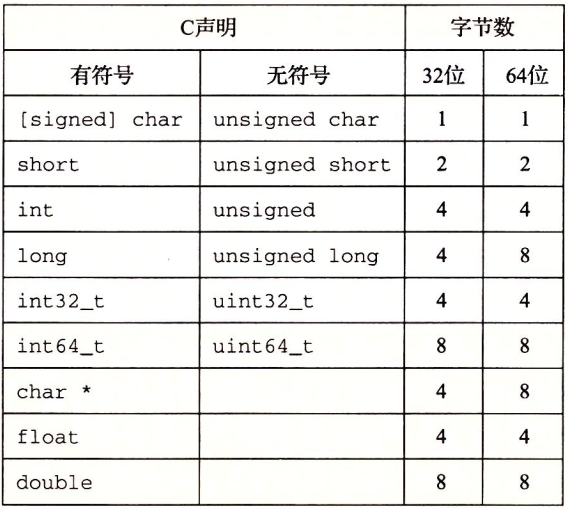
图2-2 基本C数据类型的典型大小(以字节为单位)
寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在内存中如何排列这些字节。几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。例如,假设一个int的变量x的地址为0x100,那么x的四个字节将被存储在内存的0x100、0x101、0x102和0x103位置。
排列表示一个对象的字节有两个通用的规则。考虑一个w位的整数,其表示为[xw-1,xw-2,……,x1,x0],其中xw-1是最高有效位,而x0是最低有效位。假设w是8的倍数,这些位就能被分成为字节,其中最高有效字节包含[位xw-1,xw-2,……xw-8],而最低有效字节包含位[x7,x6……x1,x0],其他字节包含中间的位。某些机器选择在内存中按照最低有效字节到最高有效字节顺序存储对象,而另一些机器则相反。如果从最低有效字节排在前面,则称为小端法;如果最高有效字节排在最前面,则称为大端法。
假设变量x的类型为int,位于地址0x100处,它的十六进制值为0x01234567。地址范围0x100~0x103的字节顺序依赖于机器的类型:

在字0x01234567,高位字节的十六进制值为0x01,而低位字节值为0x67。
下面展示一段代码,它使用强制类型转换来访问和打印不同程序对象的字节表示。我们用typedef将数据类型byte_pointer定义为一个指向类型为"unsigned char"的对象的指针。这样一个字节指针引用一个字节序列,其中每个字节都被认为是一个非负整数。第一个例程show_bytes的输入是一个字节序列的地址,它用一个字节指针以及一个字节数来表示。该字节数指定为数据类型size_t,表示数据结构大小的首选数据类型。show_bytes打印出每个以十六进制表示的字节。
#include <stdio.h>
typedef unsigned char *byte_pointer;
void show_bytes(byte_pointer start, size_t len) {
size_t i;
for (i = 0; i < len; i++)
printf(" %.2x", start[i]);
printf("
");
}
void show_int(int x) {
show_bytes((byte_pointer) &x, sizeof(int));
}
void show_float(float x) {
show_bytes((byte_pointer) &x, sizeof(float));
}
void show_pointer(void *x) {
show_bytes((byte_pointer) &x, sizeof(void *));
}
过程show_int、show_float和show_pointer展示了如何使用程序show_bytes来分别输出类型为int、float和void *的C程序对象的字节表示。可以观察到它们仅仅给show_bytes一个指向它们参数x的指针&x,且这个指针被强制类型转换为"unsigned char *byte_pointer"。这种强制类型转换告诉编译器,程序应该把这个指针看成一个字节序列,而不是指向一个原始数据类型的对象。然后,这个指针会被看成是对象使用的最低字节地址。
这些过程使用C语言的运算符sizeof来确定对象的字节数。一般来说,表达式sizeof(T)返回存储一个类型为T的对象所需要的字节数。使用sizeof而不是一个固定的值,是向编写不同机器类型上可移植的代码迈进一步。
void test_show_bytes(int val) {
int ival = val;
float fval = (float) ival;
int *pval = &ival;
show_int(ival);
show_float(fval);
show_pointer(pval);
}
int main(int argc, char *argv[])
{
test_show_bytes(12345);
return 0;
}
下面是在Linux64机器上运行上述代码的结果:
[root]# gcc -o show_bytes show_bytes.c [root]# ./show_bytes 39 30 00 00 00 e4 40 46 4c 52 3c 7d fd 7f 00 00
参数12345的十六进制标识为0x00003039。我们可以看到最低有效字节0x39先输出,这说明它是小端法机器。而float数据的字节,除了内容的表达有所不同外,字节顺序也是最低有效字节先输出。另一方面,指针值的长度是之前int和float的数据字节两倍,因为Linux64使用8字节地址。
可以观察到,浮点型和整型数据都是对数值12345编码,但它们有截然不同的字节模式:整型为0x00003039,浮点型为0x4640e400。一般而言,这两种格式使用不同的编码方法。如果我们将这些十六进制扩展为二进制,并将它们适当的移位,就会发现一个有13个相匹配的位的序列,用一串星号表示出来:

布尔代数
图2-3定义了几种布尔代数的运算:

图2-3 布尔代数的运算
我们可以将上述四个布尔运算扩展到位向量的运算,位向量就是固定长度为w、由0、1组成的串。假设a和b分别表示位向量[aw-1,aw-2,……,a0]和[bw-1,bw-2,……,b0]。我们将a&b定义为一个长度为w的位向量,其中第i个元素为ai&bi,0<=i<w。可以用类似的方式将运算|、^和~扩展到位向量。
例如w=4,从参数a=[0110],b=[1100]那么四种运算a&b、a|b、a^b和~b分别得到以下结果:

C语言中的位级运算
我们在布尔运算中使用的那些符号就是C语言所使用的:|就是OR(或)、&就是AND(与),~就是NOT(取反),而^就是异或。这些运算能运用到任何整型的数据类型上,以下是一些对char数据类型表达式求值的例子:

C语言中的逻辑运算
C语言还提供了一组逻辑运算符||、&&和!,分别对应逻辑命题中的OR、AND和NOT运算。逻辑运算很容易和位级运算相混淆,但它们的功能时完全不同的。逻辑运算认为所有的非零的参数都表示TRUE,而参数0表示FALSE。它们返回1或者0,分别表示结果为TRUE或者为FALSE。以下是一些表达式求值的示例:

C语言中的移位运算
C语言还提供了一组移位运算,向左或者向右移动位模式。对于一个位表示为[xw-1,xw-2,……w0]的操作数x,C表达式x<<k会产生一个值,其位表示为[xw-k-1,xw-k-2,……,w0,0……0]。也就是说,x向左移动k位,丢弃最高的k位,并在右端补k个0。移位量应该是一个0~w-1之间的值。移位运算时从左至右可结合的,所以x<<j<<k等价于(x<<j)<<k。
有一个相应的右移运算x>>k,但它的行为有点微秒。一般而言,机器支持两种形式的右移:逻辑右移和算数右移。逻辑右移是在左端补k个0,得到的结果是:[0,……,0,xw-k-1,xw-k-2……,xk]。算数右移是左端补k个最高有效位的值,得到的结果是[xw-1,……,xw-1,xw-2,……xk]。让我们来看一个例子,下面给出了一个对8位参数x的两个不同的值做不同的移位操作得到的结果:

斜体的数字表示的是最右端(左移)或最左端(右移)填充的值。可以看到目前除了一个条目之外,其他都包含填充0,唯一的例外是算数右移[10010101]的情况。因为操作数的最高位是1,填充的值就是1.
C语言标准并没有明确定义对于有符号数应该使用哪种类型的右移,算数右移或逻辑右移都可以。然而实际上,几乎所有的编译器/机器组合都对有符号数使用算数右移,且许多程序员也假设机器会使用这种右移。另一方面,对于无符号数,右移必须是逻辑的。