一,离线计算和实时计算各自的应用场景?
我观察似乎有些人认为实时计算比离线计算更加牛逼,然而是这个样子的么,只能说没有谁更加牛逼,只是各自的应用场景不同而已。
对于离线计算,想要得到某段时间的报表数据,这个时候可以使用离线计算,比如说进行大规模的矩阵运算,例如人脸识别的场景,这个时候就适合离线计算,人脸识别也算属于比较高端的场景,如果离线计算像想象中的那么low,那么能够完成么?而且,本质上来说,离线计算的诞生就是为了解决大规模矩阵计算,详情可见谷歌当初发表的三篇论文。
对于实时计算,适合处理,对实效性要去较高的场景,比如说推荐系统,如果一个推荐系统的实效性不高,等到用户已经买了东西,还有必要推荐么?还比如说网络安全方面,如果网络安全方面的实效性不高,那么等别人把攻击完成之后,你再去反应,是不是迟了?
当然,实时计算是不适合处理复杂逻辑的,比如说上面的大规模矩阵运算,这个运算是需要耗费大量时间的,既然需要耗费大量的时间,哪里还来的实效性?如何还来的实时性?
所以说,实时计算不是无所不能的,而离线计算也不是一无所能的,不要一听到实时计算就以为特别牛逼高端,一听到离线计算就觉得Lowb傻帽。
二,Storm和Spark的实时性,所谓的批处理让Spark在实时计算中显得一无是处?实时计算选择spark还是storm?
首先需要说明的是,spark可以进行离线计算,也可以进行实时计算,实时计算,体现在sparkstreaming上面,是spark框架的一个方面。
先来说spark,说之前,先见一张图片,

这张是spark官网上面弄下来的sparkstreaming的原理图,一些人看到这个图片,就发现了batches,然后瞬间就明悟了,噢,原来spark的实时计算就是批处理的啊!
事实上呢,的确是这个样子的,可以更详细的分析一下,见下面一张图片:
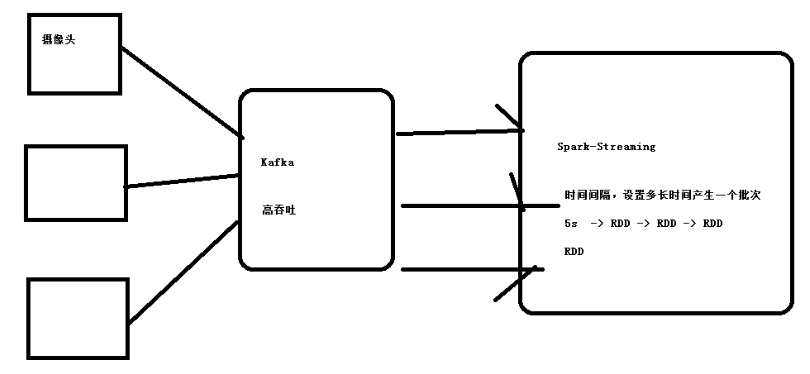
由上面的图片可见,sparkstreaming 实际上就是把一段时间(比如说上面的5秒)的数据集中起来用一个rdd进行处理,然后下一段时间的数据,再用一个rdd处理,然后如此不断循环不间断的处理,从而实现了所谓实时计算。
如此,所谓spark的实时计算,无外乎就是所谓批处理了,不间断批量处理数据就是如此了。
看一个小demo ,如下为sparkStreaming进行单词计数的简单程序代码:
scala代码
object StreamingWordCount { def main(args: Array[String]) { LoggerLevels.setStreamingLogLevels() //StreamingContext val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[2]") val sc = new SparkContext(conf) val ssc = new StreamingContext(sc, Seconds(5)) //接收数据 val ds = ssc.socketTextStream("172.16.0.11", 8888) //DStream是一个特殊的RDD //hello tom hello jerry val result = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_) //打印结果 result.print() ssc.start() ssc.awaitTermination() }
如图,标红的一段,则很清晰的表明了spark的所谓批处理的特性,即处理Seconds(5),5秒钟内的所有数据,然后再处理下个五秒钟的数据。
既然spark的实时计算,是靠所谓的批处理来实现的,那么storm的实时计算,是靠什么来实现的呢?
同样是单词计数的demo,其代码如下:
java代码
/** * 单词计数 * @author Administrator * */ public class WordCountTopology { public static class DataSourceSpout extends BaseRichSpout{ private Map conf; private TopologyContext context; private SpoutOutputCollector collector; /** * 本实例运行的是被调用一次,只能执行一次。 */ public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.conf = conf; this.context = context; this.collector = collector; } /** * 死循环的调用,心跳 */ public void nextTuple() { //读取指定目录下所有文件 Collection<File> files = FileUtils.listFiles(new File("d:\test"), new String[]{"txt"}, true); for (File file : files) { try { //获取每个文件的所有数据 List<String> lines = FileUtils.readLines(file); //把每一行数据发射出去 for (String line : lines) { this.collector.emit(new Values(line)); } FileUtils.moveFile(file, new File(file.getAbsolutePath()+System.currentTimeMillis())); } catch (IOException e) { e.printStackTrace(); } } } /** * 声明输出的内容 */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("line")); } } public static class Splitbolt extends BaseRichBolt{ private Map stormConf; private TopologyContext context; private OutputCollector collector; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.stormConf = stormConf; this.context = context; this.collector = collector; } public void execute(Tuple input) { //获取每一行数据 String line= input.getStringByField("line"); //把数据切分成一个个的单词 String[] words = line.split(" "); for (String word : words) { //把每个单词都发射数据 this.collector.emit(new Values(word)); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("words")); } } public static class Countbolt extends BaseRichBolt{ private Map stormConf; private TopologyContext context; private OutputCollector collector; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.stormConf = stormConf; this.context = context; this.collector = collector; } HashMap<String, Integer> hashMap = new HashMap<String, Integer>(); public void execute(Tuple input) { //获取每一个单词 String word = input.getStringByField("words"); //对所有的单词进行汇总 Integer value = hashMap.get(word); if(value==null){ value = 0; } value++; hashMap.put(word, value); //把结果打印出来 System.out.println("=================================="); for (Entry<String, Integer> entry : hashMap.entrySet()) { System.out.println(entry); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { } } public static void main(String[] args) { TopologyBuilder topologyBuilder = new TopologyBuilder(); topologyBuilder.setSpout("spout_id", new DataSourceSpout()); topologyBuilder.setBolt("bolt_id", new Splitbolt()).shuffleGrouping("spout_id"); topologyBuilder.setBolt("bolt_id_2", new Countbolt()).shuffleGrouping("bolt_id"); LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("topology", new Config(), topologyBuilder.createTopology()); } }
如上,在storm里面,数据是以Tuple的形式出现的,看Countbolt类的excute方法,其方法之中传入的是一个tuple,则可知,storm是一次性处理一个tuple的数据,所谓的tuple,本质来讲,是一个list集合,所以,storm也就是一次性处理一个list的数据,而又看Splitbolt和DataSourceSpout的代码可知,tuple 的大小,从源头来讲是由spout所决定的,即为storm一次性处理的数据,是可以人为控制大小的,就如spark人为的控制时间一样。
说的这里,就显而易见了,没有所谓的spark是批处理,然后其在实时计算方面差了,spark和storm的实时计算内涵,本质上是一致的,只是具体的实现方式不同,一个在空间上做了限制,一个在时间做了上限制。
实际上,一个很浅显的道理,相比较于离线计算,思考怎么去实现实时计算?必然会涉及到两个重要点:一,有一个死循环,用于不断获取数据;二,根据对实效性的要求,限制一次性处理数据的大小,即对死循环进行分段。
接下来,想决定使用哪种框架,还可以比较其他性能方面,比如并行度的问题,如下图:
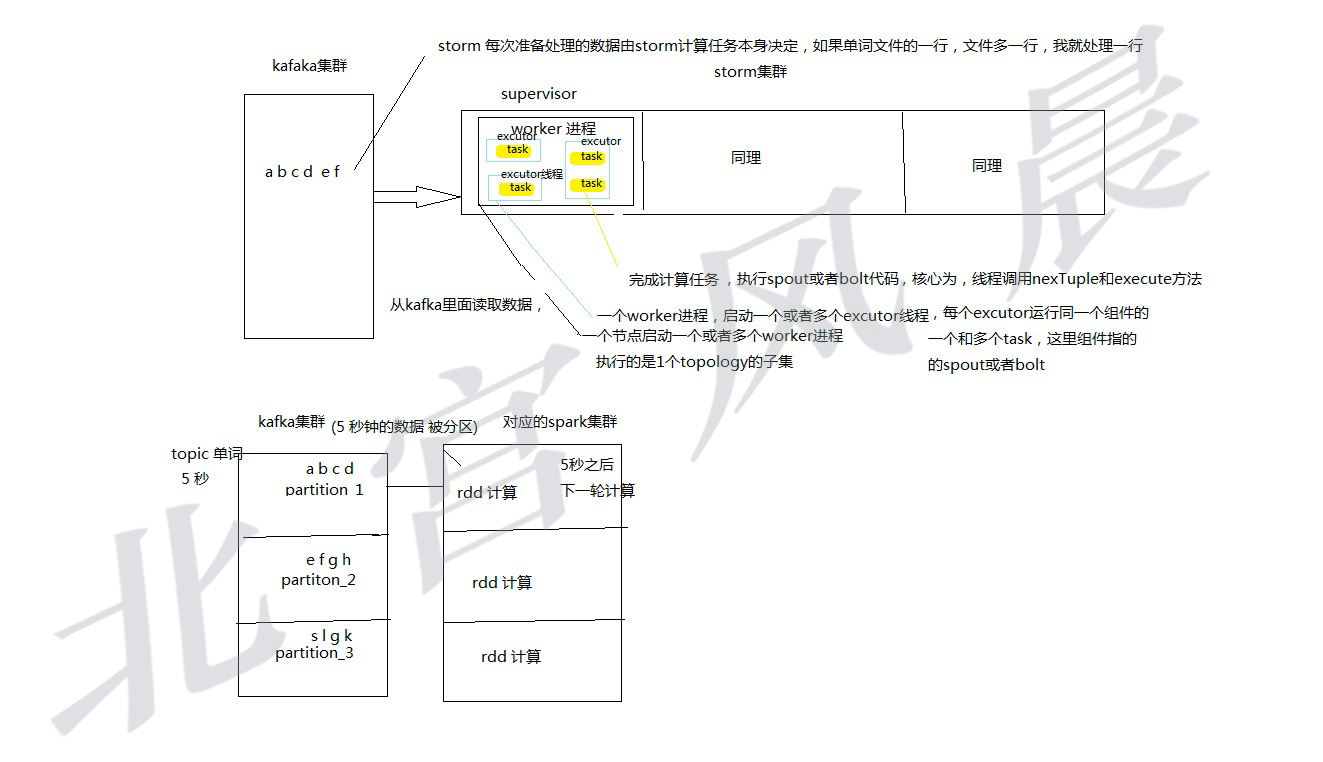
由上图可知,sparkstreaming 和storm 都实现了并行度的问题,只是两者实现的方式有点差异,storm是读取一定量个数据之后,对这些数据在storm集群之中并行化处理,即为可以开启多个线程进行同时处理这批数据。
而sparkstreaming ,在确定处理某一时间段的数据之后,即在分区的服务器上面开始计算任务,产生了并行处理的效果,然后汇总结果。
这两种并行的方式,不好说谁好谁坏,但是可以确定的是,storm在实时度的控制方面是更好一点的,依旧如上面所分析的,因为他可以直接决定处理文件的空间大小,而sparkstreaming,则是通过控制时间来控制处理文件的大小,这个是不好控制的,粒度没有storm小,所以实时性上面来说,还是稍微弱于storm的。然而,sparkstreaming 在控制时间到非常小的范围之后,实际上实时性上已经可以满足一般实时性的要求了。
最后回到最初的问题,是选择spark做实时计算的框架,还是选择storm?
答案是,我会选择spark.
首先,一个公司的业务,既有离线计算,又有实时计算,那么选择hadoop 的同时,选择storm,,就会存在了两套人马,一套维护hadoop,一套维护storm,增加人力使用成本,而如果选择spark,那么离线和事实就可有一起搞定,一套人马即可,spark的实时并不差.
其次,storm 框架的实现语言,是Clojure,这是一门比较偏门,如果运行时出现报错崩溃啥问题,很难找出,连阿里巴巴都把storm翻译成jstorm,才用的习惯,可知,这东西,也不是很好玩的。
再者,谷歌最新的深度学习框架TensorFlow是支持spark的,貌似没有听说过storm ,而spark 可以用python,scala,java 三种语言开发,所以,其兼容性方面storm是较差的。
最后,我还是支持spark.
三,在进行离线计算时,是用mapreduce,还是spark?是什么原因导致Spark的计算速度快?
离线计算,在什么情况下选择mapreduce,什么情况下选择spark,可以从spark计算速度快的原因说起。
从以下几个方面分析:
1,有关并行度的问题:
为了方便理解,画了下面的一张图:

如上图可以看出,不管是是mr还是spark,其计算都考虑了并行度的问题,并且其实现的原理也是大致相同的。
原理大致如下:通过调用hdfs的接口,感知整个文件在hdfs上面的分布状态,即其分片分别在哪些节点上面,如果这台节点上面有分片数据,则在这台节点上面启用一个计算任务,这样的话,计算时只需要进行IO操作,而不需要通过网络去读取数据,待每个节点上面的计算任务完成之后,通过网络传输,再把所有的数据传递给最终的计算任务。
由上可见,并行度,并不是决定spark运算速度快的原因。
2, 计算过程中内存和外存使用情况分析:
拿最简单的wc来进行分析:
mapreduce 的wc的代码:
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * map阶段的业务逻辑就写在自定义的map()方法中 * maptask会对每一行输入数据调用一次我们自定义的map()方法 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将maptask传给我们的文本内容先转换成String String line = value.toString(); //根据空格将这一行切分成单词 String[] words = line.split(" "); //将单词输出为<单词,1> for(String word:words){ //将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task context.write(new Text(word), new IntWritable(1)); } } }
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ /** * * 入参key,是一组相同单词kv对的key */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0; /*Iterator<IntWritable> iterator = values.iterator(); while(iterator.hasNext()){ count += iterator.next().get(); }*/ for(IntWritable value:values){ count += value.get(); } context.write(key, new IntWritable(count)); } }
spark的wc的代码:
object WordCount { def main(args: Array[String]) { //创建SparkConf()并设置App名称 val conf = new SparkConf().setAppName("WC") //创建SparkContext,该对象是提交spark App的入口 val sc = new SparkContext(conf) //使用sc创建RDD并执行相应的transformation和action sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile(args(1)) //停止sc,结束该任务 sc.stop() } }
看单词计数的代码,mapreduce ,是将每个单词的计算结果,一个又一个的写入hdfs之中,这样的话,IO操作相当频繁,耗费时间当然也多,而spark,则是把结果一次性全部写入hdfs之中.
spark代码之中,这里的reduceByKey(_+_),其底层调用的是aggregateByKey(0)(_+_,_+_),即为在每个分区上面,先进行叠加的操作,然后把每个分区的结果,通过网络传到一起去计算。
为了进一步分析,画出如下图:
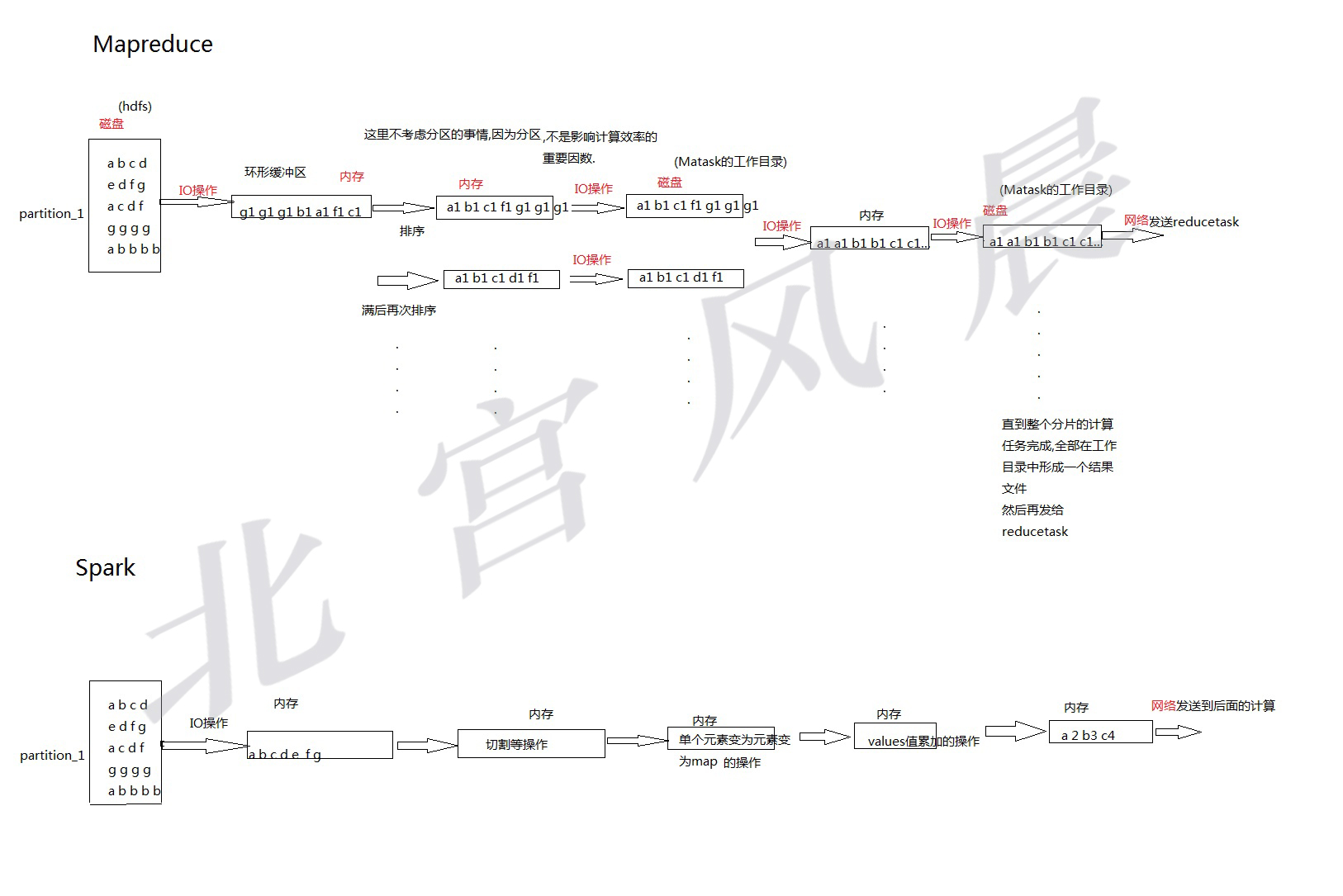
从图中可以看出,虽然说他们的并行度的实现原理大致相同,但是每个并行计算在发生的时候,实现的原理完全不同,对Mr,为了得到一个最终的结果,利用缓存,进行了非常多的IO操作,而spark来说,其把文件加载进入内存之后,一直在内存之中计算,一次IO操作都没有发生,众所周知,IO操作,是非常耗费时间的,所以这就是mr计算速度慢的原因.
同时,还可以看出,spark网络传输的数据,其量上来说,会比mr小上许多,因为其在网络传输前已经进行了运算.
3,其他
spark可以根据血统恢复以前计算的数据结果,同时可以使用cache机制,缓存计算的中间结果,利用chekpoint机制,来保证重要中间结果的安全性,同时不管是cache机制还是checkpoint机制,都可以大大的提升计算的速度.
最后总结,在选择架构时,如果有非常多内存很大的服务器,那么可以选择spark来进行离线计算,如果没有很好的服务器配置,又想实现离线计算,那么就可以考虑玩玩mr.
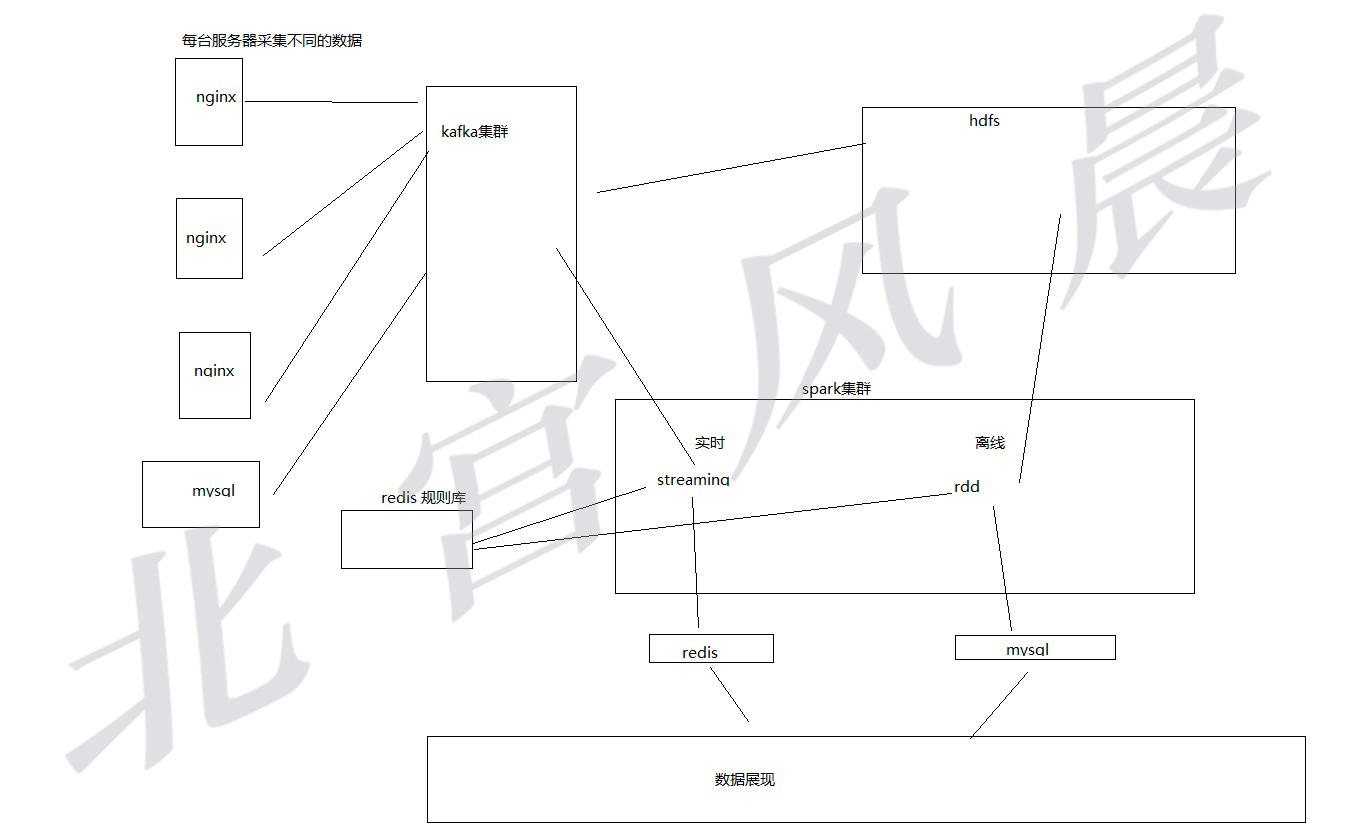
四,一个系统的简单架构。
由于不知需求,所以暂时画图如下架构图.