3.1 假设检验的基本概念
例3.1 已知小麦亩产服从正态分布,传统小麦品种平均亩产800斤,现有新品种产量未知,试种10块,每块一亩,产量为:
775,816,834,836,858,863,873,877,885,901
问:新产品亩产是否超过了800斤?
假设检验就是概率意义上的反证法。要证明命题H1: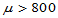 ,可以首先假设H0:
,可以首先假设H0: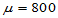 。本体中容易计算样本均值超过800了,有没有可能超过800的原因是由于抽样的随机性引起的?是否总体均值根本没有变化?我们看如下的统计量:
。本体中容易计算样本均值超过800了,有没有可能超过800的原因是由于抽样的随机性引起的?是否总体均值根本没有变化?我们看如下的统计量:
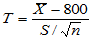
容易看出,如果新品种确有增产效应,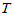 应偏大,不利于H0,取
应偏大,不利于H0,取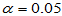 ,查表求临界值
,查表求临界值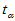 ,使得
,使得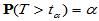 ,即构造不利于H0,有利于H1的小概率事件,如果在一次试验中该小概率事件发生了,就有理由拒绝H0,认为H1成立。
,即构造不利于H0,有利于H1的小概率事件,如果在一次试验中该小概率事件发生了,就有理由拒绝H0,认为H1成立。
严格逻辑意义上的反证法思路如下:欲证H1成立,先假设其否命题H0成立,然后找出逻辑意义上的矛盾,从而推翻H0成立,严格证明H1成立。假设检验的思路类似,只不过引出的不是矛盾,而是小概率事件在一次实验中发生。
我们称想要证明的命题H1为备择假设,对立的命题H0称为原假设,面对样本,我们必须表态是接受原假设还是拒绝原假设,这有可能出现两类错误。如果客观上原假设的确成立,面对样本的异常我们拒绝了原假设,这种"以真为假"的错误我们称为第一类错误,发生的概率用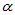 表示;如果客观上备择假设成立,我们却接受了原假设,这种"以假为真"的错误我们称为第二类错误,用发生的概率用
表示;如果客观上备择假设成立,我们却接受了原假设,这种"以假为真"的错误我们称为第二类错误,用发生的概率用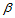 表示。假设假设检验一般首先控制第一类错误,即:当我们拒绝原假设时有比较充足的理由,犯错误的概率不超过预设的
表示。假设假设检验一般首先控制第一类错误,即:当我们拒绝原假设时有比较充足的理由,犯错误的概率不超过预设的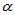 ,称
,称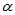 为显著性水平。常用的显著性水平有
为显著性水平。常用的显著性水平有
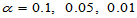
这种预设显著性水平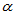 的假设检验也称为显著性检验,以后我们提到的假设检验都是显著性检验。对于显著性检验,当接受原假设时,可以认为是拒绝的证据不足。
的假设检验也称为显著性检验,以后我们提到的假设检验都是显著性检验。对于显著性检验,当接受原假设时,可以认为是拒绝的证据不足。
对于例3.1的问题,取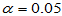 ,当
,当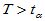 时拒绝原假设。这里
时拒绝原假设。这里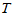 称为检验统计量,
称为检验统计量,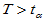 所确定的
所确定的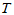 的取值范围称为拒绝域。
的取值范围称为拒绝域。
x=[775,816,834,836,858,863,873,877,885,901];
T=(mean(x)-800)/(std(x)/sqrt(9)),
ta=tinv(0.95,9),
计算结果T=4.1669>ta=1.8331,故拒绝原假设,认为确有增产。
之所以查表求临界值,是因为当初计算机及数学软件尚未普及,人们利用稀有的计算机资源计算出了一些关键的临界值,供没有计算机的人们膜拜使用。因此上述解题套路是几乎所有教科书上使用的方法,不妨称为"查表法"。
由于计算机及数学软件的普及,统计方法的使用套路也应该更新,如果写作业写论文都用计算机打字,真正数学计算反而要翻书本查表,怎么看也都很滑稽。
其实,Matlab可以计算常用分布在任意一点的分布函数的值,例如对于上述T=4.1669,可以直接计算分布函数在该点的值:
p=tcdf(T,9)
计算结果为0.9988,超过了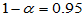 。或者计算出1-p=0.0012,小于我们预设的显著性水平
。或者计算出1-p=0.0012,小于我们预设的显著性水平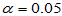 。面对0.0012这个值,我们拒绝了原假设,就是使用了概率意义上的反证法。我们可以做一个比喻:张三每天上网游戏,期末考试肯定不及格,我们说:"要想张三及格,除非明天太阳从西边出来"。这里原假设是"及格",备择假设"不及格"是我们想证明的东西。其等价的逆否命题是:因为明天太阳不会从西边出来,所以张三一定不及格。这是我们说话的内含逻辑。"太阳从西边出来"是不可能事件,我们使用的是语文上"夸张"的修辞方法以表达对张三的极度鄙视。
。面对0.0012这个值,我们拒绝了原假设,就是使用了概率意义上的反证法。我们可以做一个比喻:张三每天上网游戏,期末考试肯定不及格,我们说:"要想张三及格,除非明天太阳从西边出来"。这里原假设是"及格",备择假设"不及格"是我们想证明的东西。其等价的逆否命题是:因为明天太阳不会从西边出来,所以张三一定不及格。这是我们说话的内含逻辑。"太阳从西边出来"是不可能事件,我们使用的是语文上"夸张"的修辞方法以表达对张三的极度鄙视。
现在,面对新品种亩产数据,我们的结论是:要说没有增产效应,除非明天下大雹子。这里没有"夸张",因为1-p=0.0012大约为千分之一,是类似于不可能事件的极小概率事件,和明天下大雹子一样罕见(大约三年才得一见)。我们计算出来的1-p越小,说明备择假设成立的证据越充足。
几十年前,对于自由度为9的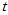 分布,我们只能将
分布,我们只能将
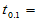 1.3830,
1.3830,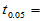 1.8331 ,
1.8331 ,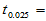 2.2622,
2.2622,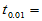 2.8214
2.8214
等少数几个值印在书上,现在我们可以计算p=tcdf(T,9)在任意一点分布函数的值。
3.2 正态总体参数的假设检验
3.2.1 单正态总体均值的假设检验
设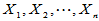 为来自正态总体
为来自正态总体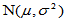 简单随机样本,
简单随机样本,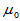 为我们关心的已知的值,原假设为:
为我们关心的已知的值,原假设为:
H0: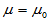
(1)方差已知情形
此时,检验统计量为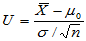 ,H0成立时
,H0成立时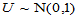 ,依据备择假设的不同提法,分三种情况分别给出拒绝域。
,依据备择假设的不同提法,分三种情况分别给出拒绝域。
1)双侧检验 备择假设H1: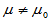 拒绝域:
拒绝域: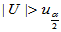
这种情形我们关心的是总体均值是否发生了变化,增多减少都是我们同等关注的。例如要研究某种药物的副作用,是否引起血压的变化,变大变小都是副作用,如果实验证明了确有副作用,就该停产或慎用。
2)单侧检验(右侧) 备择假设H1: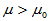 拒绝域:
拒绝域: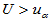
这种情形我们关心的是总体均值是否有增加效应,例如小麦亩产。无增产效应或者减产都是我们不希望看到的,我们希望证明的是增产了。
3)单侧检验(左侧) 备择假设H1: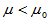 拒绝域:
拒绝域: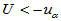
这种情形我们希望看到总体均值变小了。每匹布上疵点的个数。新工艺后是否有减少。
(2)方差未知情形
原假设H0: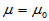
此时,检验统计量为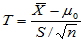 ,H0成立时
,H0成立时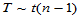 ,依据备择假设的不同提法,分三种情况分别给出拒绝域。
,依据备择假设的不同提法,分三种情况分别给出拒绝域。
1)双侧检验 备择假设H1: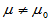 拒绝域:
拒绝域: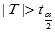
2)单侧检验(右侧) 备择假设H1: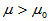 拒绝域:
拒绝域: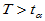
3)单侧检验(左侧) 备择假设H1: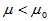 拒绝域:
拒绝域: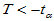
其实,上一章中区间估计与这里的双侧检验本质上是相同的:区间套中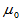 接受原假设,没套中则拒绝原假设。只不过检验统计量的计算更简单些。类似于单侧检验,也可以有单侧区间估计。
接受原假设,没套中则拒绝原假设。只不过检验统计量的计算更简单些。类似于单侧检验,也可以有单侧区间估计。
3.2.2 单正态总体方差的假设检验
设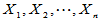 为来自正态总体
为来自正态总体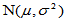 简单随机样本,
简单随机样本,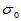 为我们关心的已知的值,原假设为H0:
为我们关心的已知的值,原假设为H0: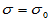 ,检验统计量为
,检验统计量为
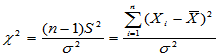
当H0成立时,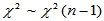 ,由此可查
,由此可查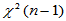 临界值表,构造拒绝域。
临界值表,构造拒绝域。
(1)双侧检验 此时备择假设为H1: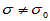 ,也就是说,我们希望通过样本找到总体方差比较
,也就是说,我们希望通过样本找到总体方差比较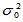 有明显变化的证据,无论变大变小都是我们希望证明的。
有明显变化的证据,无论变大变小都是我们希望证明的。
此时取临界值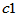 与
与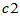 ,使得
,使得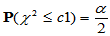 ,
,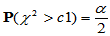 ,拒绝域为:
,拒绝域为: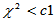 (方差变小了),或者
(方差变小了),或者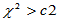 (方差变大了)。
(方差变大了)。
当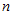 已经赋值的时候,执行如下Matlab命令可得到临界值。
已经赋值的时候,执行如下Matlab命令可得到临界值。
a=0.05, n=20, c1=chi2inv(a/2,n-1), c2=chi2inv(1-a/2,n-1),
(2)单侧检验(右侧) 此时备择假设为H1: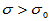 ,也就是说,我们关心的是方差是否变大了。此时临界值为
,也就是说,我们关心的是方差是否变大了。此时临界值为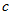 满足
满足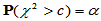 ,可用
,可用
c=chi2inv(1-a,n-1)
(3)单侧检验(左侧) 此时备择假设为H1: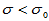 ,也就是说,我们关心的是方差是否变小了。此时临界值为
,也就是说,我们关心的是方差是否变小了。此时临界值为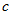 满足
满足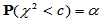 ,可用
,可用
c=chi2inv(a,n-1)
3.2.3 两正态总体均值的假设检验
设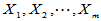 为来自正态总体
为来自正态总体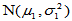 的简单随机样本,
的简单随机样本,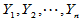 为来自正态总体
为来自正态总体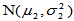 的简单随机样本,且两样本独立。为比较两个总体的期望,提出如下原假设:
的简单随机样本,且两样本独立。为比较两个总体的期望,提出如下原假设:
H0: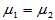
与前面类似,备择假设有双侧、单侧(左侧、右侧)等提法。
(1)方差已知情形
此时检验统计量为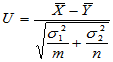 ,当H0成立时
,当H0成立时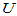 服从标准正态分布,临界值
服从标准正态分布,临界值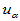 ,
,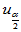 含义及计算方法同前。
含义及计算方法同前。
1)双侧检验 H1: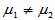 ,拒绝域:
,拒绝域: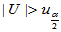
2)右侧检验 H1: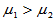 ,拒绝域:
,拒绝域: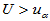
3)左侧检验 H1: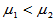 ,拒绝域:
,拒绝域: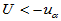
(2)方差未知但相等情形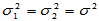
此时原假设仍为H0: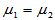 ,备择假设同样有三种提法。检验统计量为:
,备择假设同样有三种提法。检验统计量为:
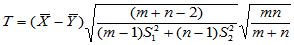
当H0成立时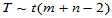 ,由此得临界值
,由此得临界值 ,
,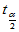 。
。
1)双侧检验 H1: ,拒绝域:
,拒绝域: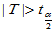
2)右侧检验 H1: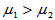 ,拒绝域:
,拒绝域: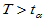
3)左侧检验 H1: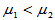 ,拒绝域:
,拒绝域: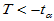
3.2.4 两正态总体方差的假设检验
设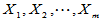 为来自正态总体
为来自正态总体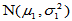 的简单随机样本,
的简单随机样本,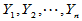 为来自正态总体
为来自正态总体 的简单随机样本,且两样本独立。为比较两个总体的方差,提出如下原假设:
的简单随机样本,且两样本独立。为比较两个总体的方差,提出如下原假设:
H0: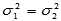
与前面类似,备择假设有双侧、单侧(左侧、右侧)等提法。此时检验统计量为 ,当H0成立时,
,当H0成立时,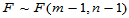 ,在Matlab中,如果m,n已经赋值,例如m=8,n=10则
,在Matlab中,如果m,n已经赋值,例如m=8,n=10则
c1=finv(0.025,7,9),c2=finv(0.975,7,9)
分别给出了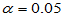 时的两个临界值,双侧检验的拒绝域为
时的两个临界值,双侧检验的拒绝域为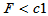 或
或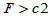 。
。
c3=finv(0.05,7,9)
给出了左侧检验临界值,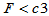 时拒绝原假设,认为备择假设H1:
时拒绝原假设,认为备择假设H1: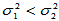 成立。
成立。
c4=finv(0.95,7,9)
给出了右侧检验临界值,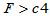 时拒绝原假设,认为备择假设H1:
时拒绝原假设,认为备择假设H1: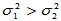 成立。
成立。
3.2.5 大样本非正态总体均值的假设检验
设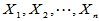 为来自非正态总体的简单随机样本,设总体均值
为来自非正态总体的简单随机样本,设总体均值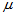 与总体方差
与总体方差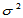 有限,原假设
有限,原假设
H0: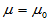
此时可以将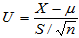 作为近似的检验统计量,当样本容量很大时(例如100),由中心极限定理知H0成立时
作为近似的检验统计量,当样本容量很大时(例如100),由中心极限定理知H0成立时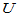 近似服从标准正态分布,可以仿照3.2.1小节中的算法检验如下三个备择假设:
近似服从标准正态分布,可以仿照3.2.1小节中的算法检验如下三个备择假设:
H1: ; H1:
; H1: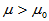 ; H1:
; H1: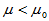
设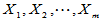 为来自非正态总体的简单随机样本,
为来自非正态总体的简单随机样本,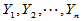 为来自非正态总体的简单随机样本,且两样本独立。两个总体有有限的均值与方差,均值为
为来自非正态总体的简单随机样本,且两样本独立。两个总体有有限的均值与方差,均值为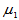 与
与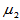 ,为比较两个总体的期望,提出如下原假设:
,为比较两个总体的期望,提出如下原假设:
H0: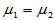
与前面类似,备择假设有双侧、单侧(左侧、右侧)等提法。此时可以将
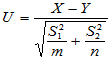
近似作为检验统计量,当两个样本容量都很大时(例如100),由中心极限定理知H0成立时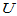 近似服从标准正态分布,可以仿照3.2.3小节中的算法检验如下三个备择假设:
近似服从标准正态分布,可以仿照3.2.3小节中的算法检验如下三个备择假设:
H1: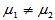 ; H1:
; H1: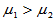 ; H1:
; H1: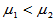
3.3 三个常用的非参数检验
大样本情形下,对于非正态总体,可以利用中心极限定理近似用标准正态分布进行假设检验。小样本情形,若总体不是正态分布的,可以使用非参数检验的方法。非参数检验的效率稍差,但适应各种总体类型,应用范围较广。
3.3.1 符号检验
例3.2 已知原来工艺下生产的某种灯泡的中位数为800小时,现改进生产工艺,试产10只灯泡,实验得到每只寿命为:
775,816,834,836,858,863,873,877,885,901
问:新工艺生产的灯泡寿命中位数是否超过了800小时?
H0: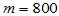
一般情况下,灯泡寿命不是正态分布的,不能用例3.1的方法。符号检验使用的是计数统计量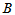 ,先设
,先设
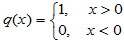
则有
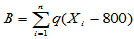
即记录样本点中大于800的个数。若H0成立,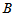 应该大约占样本容量的一半左右,若
应该大约占样本容量的一半左右,若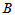 异常的大,说明备择假设H1:
异常的大,说明备择假设H1: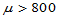 成立。
成立。
H0成立时,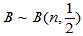 ,可以利用二项分布构造拒绝域:
,可以利用二项分布构造拒绝域:
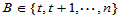
使得若H0成立时
 ,
,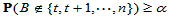
利用二项分布的分布律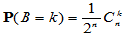 可以计算出临界值
可以计算出临界值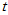 ,用如下Matlab函数文件计算。
,用如下Matlab函数文件计算。
function t=bt(n,a)
SS=2^n*a;
S=0;
c=1;
k=n+1;
while S<=SS
k=k-1;
S=S+c;
c=c*k/(n-k+1);
end
t=k+1;
以上自定义函数扩展了Matlab的功能,可以替代教科书上的"符号检验临界值表",并且可以使用任意的n及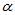 。
。
在例3.2中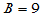 ,
,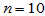 ,对于
,对于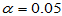 ,使用命令t=bt(10,0.05)可以得到临界值9,
,使用命令t=bt(10,0.05)可以得到临界值9,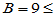 临界值9,落在拒绝域内,故拒绝原假设,认为新工艺生产的灯泡寿命中位数超过了800小时。
临界值9,落在拒绝域内,故拒绝原假设,认为新工艺生产的灯泡寿命中位数超过了800小时。
只要去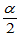 代替
代替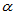 ,也可以进行双侧符号检验。
,也可以进行双侧符号检验。
例3.3 20个品酒师对A、B两种白酒进行品尝,有17个品酒师认为A品质好,3个品酒师认为B品质好,在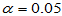 的显著性水平下,检验两种白酒品质是否存在差异?
的显著性水平下,检验两种白酒品质是否存在差异?
解
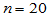 ,设原假设为
,设原假设为
H0:两种白酒品质无差异
令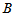 表示认为A品质好的品酒师的人数,则H0成立时
表示认为A品质好的品酒师的人数,则H0成立时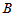 应该在10左右取值,如果
应该在10左右取值,如果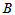 值异常大,或者异常小,都说明两种白酒品质有差异。取临界值
值异常大,或者异常小,都说明两种白酒品质有差异。取临界值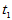 与
与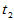 ,使得
,使得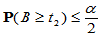 ,
,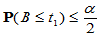 ,由于
,由于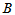 关于
关于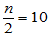 对称,故有
对称,故有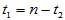 ,因此可用水平为
,因此可用水平为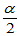 的单侧检验求出临界值
的单侧检验求出临界值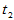 。命令
。命令
t2=bt(20,0.05/2)
得到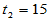 ,因此
,因此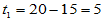 ,此例中拒绝域为
,此例中拒绝域为
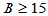 ,或者
,或者 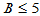
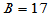 落在拒绝域内,可以认为两种白酒品质有显著差异。
落在拒绝域内,可以认为两种白酒品质有显著差异。
有些教科书中没有0.025的临界值,而我们的函数bt.m扩展了功能。
Matlab中有自带的SIGNTEST函数,可以直接用于符号检验。默认的检验是双侧的。
对于配对实验的两总体均值检验问题,也可用符号检验。
3.3.2 Wilcoxon秩和检验
我们要研究的问题是两总体均值的假设检验,设
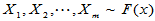 ,
,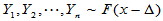
要检验第二个总体是否有增加效应,即检验如下问题:
H0: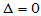 H1:
H1: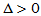
Wilcoxon秩和检验的方法是:将两个样本混合为
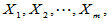
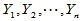
混合之后样本容量为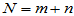 ,每个样本点在样本中从小到大排列的名次称为该样本点的秩,用
,每个样本点在样本中从小到大排列的名次称为该样本点的秩,用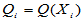 表示
表示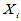 在混合样本中的秩,
在混合样本中的秩,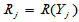 表示
表示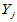 在混合样本中的秩,检验统计量为
在混合样本中的秩,检验统计量为
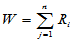
例如诸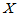 为 1.1,3.3,5.5,7.7,诸
为 1.1,3.3,5.5,7.7,诸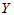 为2.2,4.4,6.6,以下列表给出混合样本及秩
为2.2,4.4,6.6,以下列表给出混合样本及秩
混合样本 | 1.1 | 3.3 | 5.5 | 7.7 | 2.2 | 4.4 | 6.6 |
秩 | 1 | 3 | 5 | 7 | 2 | 4 | 6 |
则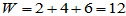 。
。
若H0成立,则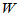 的值应该适中。注意到每个秩序的平均值为
的值应该适中。注意到每个秩序的平均值为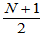 ,故H0成立时,
,故H0成立时, ,
,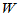 的值在此值附近应该是正常的。若
的值在此值附近应该是正常的。若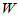 的值异常偏大,说明第二个总体确有增加效应。利用matlab自身的函数
的值异常偏大,说明第二个总体确有增加效应。利用matlab自身的函数
p = ranksum(X,Y)
可以进行双侧的秩和检验。返回的p值小于给定的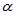 则拒绝原假设,认为H1:
则拒绝原假设,认为H1: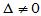 成立。
成立。
H0成立时,可以证明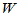 关于
关于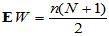 对称,要检验H1:
对称,要检验H1: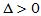 ,只要判定
,只要判定 ,并且p = ranksum(X,Y)
,并且p = ranksum(X,Y)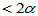 即可。
即可。
自定义rsum函数用于求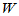
function W=rsum(x,y)
[s,t]=size(x);
m=max(s,t);
if t<m
x=x';
end
[s,t]=size(y);
n=max(s,t);
N=m+n;
if t<n
y=y';
end
xy=[x,y];
[z,I]=sort(xy);
W=0;
for i=1:N
if(I(i))>m
W=W+i;
end
end
为了求出Wilcoxon秩和检验的临界值,我们给出如下定理,证明参见文献[1]。
定理3.1
在H0成立时,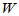 的概率分布为
的概率分布为
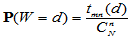
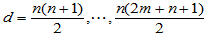
其中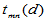 表示从
表示从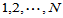 中取
中取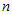 个数其和恰为
个数其和恰为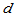 的取法的个数。
的取法的个数。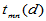 可用如下初始条件及递推公式计算:
可用如下初始条件及递推公式计算:
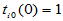
 当
当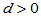
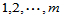
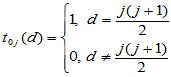
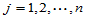
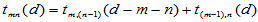
自己编程tmnd.m计算如下:
function tmn=tmnd(m,n,d)
N=m+n;
nn=n*(n+1)/2;
NN=n*(2*m+n+1)/2;
if m<0 | n<0 | d<nn | d>NN
tmn=0;
elseif m>0 & n==0 & d==0
tmn=1;
elseif m>0 & n==0 & d>0
tmn=0;
elseif m==0 & n>0 & d==nn
tmn=1;
elseif m==0 & n>0 & d~nn
tmn=0;
else
T=zeros(m,n,NN);
for i=1:m
for k=1:i+1;
T(i,1,k)=1;
end
end
for j=1:n
kk=j*(j+1)/2;
KK=(j+1)*(j+2)/2-1;
for k=kk:KK
T(1,j,k)=1;
end
end
for i=2:m
for j=2:n
s=i+j;
for k=1:d
if k<=s
T(i,j,k)=T(i-1,j,k);
else
T(i,j,k)=T(i,j-1,k-s)+T(i-1,j,k);
end
end
end
end
tmn=T(m,n,d);
end
可以证明,H0成立时,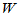 的概率分布关于E=n*(m+n+1)/2对称,我们给出单侧检验临界值的求法,以下自定义函数wr.m,其中输入参数m,n,alpha分别是对照组样本容量、实验组样本容量、检验的显著性水平,而输出值c表示右侧临界值,即满足
的概率分布关于E=n*(m+n+1)/2对称,我们给出单侧检验临界值的求法,以下自定义函数wr.m,其中输入参数m,n,alpha分别是对照组样本容量、实验组样本容量、检验的显著性水平,而输出值c表示右侧临界值,即满足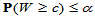 的最小正整数。
的最小正整数。
function c=wr(m,n,alpha)
% return the min c such that P(W>=c)<=alpha
NN=n*(2*m+n+1)/2;
nn=n*(n+1)/2;
N=m+n;
E=n*(N+1)/2;
a=1;
for k=1:n
a=a*(N+1-k)/k;
end
Alpha=a*alpha;
k=nn;
P=0;
while P<Alpha
P=P+tmnd(m,n,k);
k=k+1;
end
c1=k-1;
c=2*E-c1;
上述函数可用于右侧检验。若左侧检验,c1=2*E-c即为左侧临界值。若双侧检验,先求出c2=wr(m,n,alpha/2),再由c1=2*E-c2即可。
例3.4 某班级共15名同学,某次英语水平考试,分数如下:
男:53,55,59,65,71,77,81
女:56,62,68,76,84,86,90,96
在显著性水平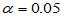 下,能否认为女生英语水平高于男生?要求采用Wilcoxon秩和检验。
下,能否认为女生英语水平高于男生?要求采用Wilcoxon秩和检验。
解 注意这是一个单侧检验问题,使用matlab命令:
x=[53,55,59,65,71,77,81]
y=[56,62,68,76,84,86,90,96]
rsum(x,y)
c=wr(7,8,0.05)
上述计算中,注意到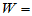 rsum(x,y)=78,而临界值为c=78,
rsum(x,y)=78,而临界值为c=78, 的值落在拒绝域内,故可拒绝原假设,认为女生成绩显著高于男生。
的值落在拒绝域内,故可拒绝原假设,认为女生成绩显著高于男生。
3.3.3 Wilcoxon符号秩检验
设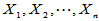 为来自连续总体
为来自连续总体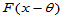 的简单随机样本,
的简单随机样本,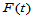 关于
关于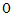 点对称,检验假设
点对称,检验假设
H0: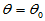 H1:
H1: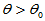
Wilcoxon符号秩检验统计量为:
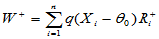
其中
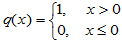
 ,即把
,即把 依照绝对值由小到大排列,
依照绝对值由小到大排列,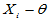 的名次。
的名次。
H0成立时,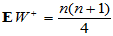 ,故在此值附近取值说明原假设成立。若
,故在此值附近取值说明原假设成立。若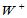 异常大,则要拒绝原假设,说明H1:
异常大,则要拒绝原假设,说明H1: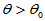 成立。
成立。
对于双侧检验问题
H0: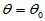 H1:
H1: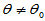
Matlab有自带的函数
p=signrank(x,m)
这里x为样本,m代表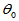 ,若显著性水平为
,若显著性水平为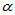 ,则
,则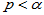 时拒绝原假设。
时拒绝原假设。
对于单侧检验,H1: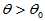 ,要拒绝原假设需要同时满足两个条件:条件一,
,要拒绝原假设需要同时满足两个条件:条件一,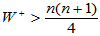 ;条件二,p=signrank(x,m)<
;条件二,p=signrank(x,m)<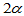 。为计算
。为计算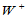 ,自编函数:
,自编函数:
function wp=rpsum(x,m);
n=length(x);
x=x-m;
y=abs(x);
[z,I]=sort(y);
wp=0;
for i=1:n
if x(I(i))>0
wp=wp+i;
end
end
保存了上述函数后,即可进行单侧检验。
例3.5 某班级共15名同学,某次英语水平考试,分数如下:
53,55,59,65,71,77,81,56,62,68,76,84,86,90,96
在显著性水平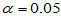 下,能否认为平均成绩高于60分?要求分别用:
下,能否认为平均成绩高于60分?要求分别用:
(1)符号检验;(2)Wilcoxon符号秩检验。
解 注意这是一个单侧检验问题:
H0: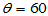 H1:
H1: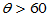
使用matlab命令:
x=[53,55,59,65,71,77,81,56,62,68,76,84,86,90,96]
(1)符号检验
注意这里n=15,B=11,利用前面自定义的bt.m函数计算:
t=bt(15,0.05)
得到临界值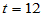 ,B=11<
,B=11<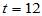 ,没有落入拒绝域,故接受H0,认为平均成绩没有明显高于60分。
,没有落入拒绝域,故接受H0,认为平均成绩没有明显高于60分。
(2)Wilcoxon符号秩检验
E=n*(n+1)/4,
wp=rpsum(x,60),
计算结果发现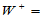 wp=106> E=60,满足单侧检验条件一,再计算
wp=106> E=60,满足单侧检验条件一,再计算
p=signrank(x,60)
结果得p=0.0071<2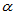 ,故拒绝原假设,认为平均成绩明显高于60分。
,故拒绝原假设,认为平均成绩明显高于60分。
3.4 检验的功效函数
为了简单起见,我们只讨论位置参数的单侧检验:
H0: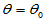 H1:
H1: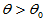
其中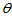 为总体的中位数。
为总体的中位数。
对于上述检验,当总体为方差已知正态总体时,有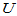 检验;当总体为方差未知正态总体时,有
检验;当总体为方差未知正态总体时,有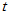 检验;当总体为连续对称总体时,有符号检验及Wilcoxon符号秩检验。自然有一个问题,如何评价不同的检验方法的优劣?
检验;当总体为连续对称总体时,有符号检验及Wilcoxon符号秩检验。自然有一个问题,如何评价不同的检验方法的优劣?
对于相同的样本容量,对于相同的显著性水平,一般比较区间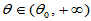 时拒绝的概率
时拒绝的概率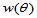 ,此时
,此时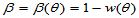 为犯第二类错误的概率。不同的检验方法犯第一类错误的概率已经被
为犯第二类错误的概率。不同的检验方法犯第一类错误的概率已经被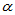 控制了,具有相同的水平,此时比较
控制了,具有相同的水平,此时比较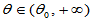 时的
时的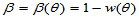 ,小者为好;或者等价地说,比较
,小者为好;或者等价地说,比较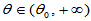 时的
时的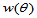 ,越大越好。
,越大越好。
称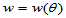 ,
,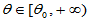 为检验的功效函数。功效大的检验就是好的检验。
为检验的功效函数。功效大的检验就是好的检验。
以下画出正态总体方差已知时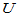 检验的功效函数。H0时,不妨设总体服从标准正态分布,
检验的功效函数。H0时,不妨设总体服从标准正态分布,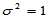 已知,均值用m表示。
已知,均值用m表示。
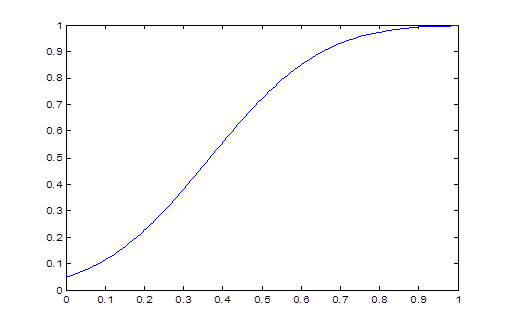
以下固定样本容量n=20,固定显著性水平a=0.05,此时检验临界值为
u0=norminv(0.95)=1.6449。当m>0时,检验统计量为
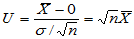
容易计算
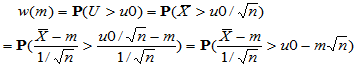
=1-normcdf(u0-m*sqrt(20))
以下利用Matlab作图功能画出此时的功效函数。
u0=norminv(0.95)
m=0:0.01:1;
w=1-normcdf(u0-m*sqrt(20));
plot(m,w)
结果如图3-1所示。
 图图3-1 n=20,
图图3-1 n=20, =0.05单侧
=0.05单侧 检验功效函数
检验功效函数
请读者自己研究,随着样本容量的增加,功效函数的图形会有怎样的变化?
注意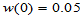 ,这是水平为
,这是水平为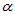 的检验的出发点,类似于百米赛跑,此点是起跑点。如果相同起跑点,随着
的检验的出发点,类似于百米赛跑,此点是起跑点。如果相同起跑点,随着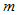 的增加,功效函数越来越大,对于两条功效函数曲线,在备择假设的范围内大者为佳。
的增加,功效函数越来越大,对于两条功效函数曲线,在备择假设的范围内大者为佳。
上述功效函数容易得到精确的曲线,稍微复杂的情形,拒绝概率的精确值不易计算,可以使用随机模拟的方法得到功效函数。
例如,要研究t检验的功效函数、符号检验的功效函数、Wilcoxon符号秩检验的功效函数,并与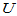 检验的功效函数进行对比。首先固定如下四个因素:
检验的功效函数进行对比。首先固定如下四个因素:
(1)总体分布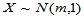 ;
;
(2)样本容量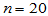 ;
;
(3)显著性水平a=0.05;
(4)取定
前三条都满足时,三种方法的临界值就完全确定了,拒绝域也完全确定了:
t检验: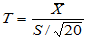 ,拒绝域为
,拒绝域为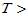 t0=tinv(0.95,19)=1.7291;
t0=tinv(0.95,19)=1.7291;
符号检验: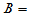 大于0样本点个数,拒绝域
大于0样本点个数,拒绝域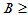 t=bt(20,0.05)=15;
t=bt(20,0.05)=15;
Wilcoxon符号秩检验:拒绝域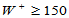
为评价不同的检验,我们可以分别计算功效函数。这可以采用随机模拟的方法,利用万次随机试验中拒绝的频率近似代替拒绝概率。
以下命令文件保存为p123.m
m=0:0.1:1;
p1=zeros(1,11);
p2=zeros(1,11);
p3=zeros(1,11);
t0=tinv(0.95,19);
b0=15;
w0=150;
s20=sqrt(20);
N=10000;
for mm=1:11
for k=1:N
x=randn(1,20)+m(mm);
T=s20*mean(x)/std(x);
if T>=t0
p1(mm)=p1(mm)+1;
end
B=0;
for i=1:20
if x(i)>0
B=B+1;
end
end
if B>=b0
p2(mm)=p2(mm)+1;
end
wp=rpsum(x,0);
if wp>=w0
p3(mm)=p3(mm)+1;
end
end
p1(mm)=p1(mm)/N;
p2(mm)=p2(mm)/N;
p3(mm)=p3(mm)/N;
mm
end
P=[p1;p2;p3]
plot(m,p1,m,p2,m,p3)
计算结果为
P =
0.0482 0.1105 0.2100 0.3522 0.5304 0.6958 0.8292 0.9132 0.9609 0.9874 0.9953
0.0192 0.0460 0.0864 0.1619 0.2551 0.3775 0.5247 0.6528 0.7711 0.8456 0.9123
0.0468 0.1063 0.2000 0.3379 0.5084 0.6746 0.8091 0.9007 0.9558 0.9823 0.9926
图形为
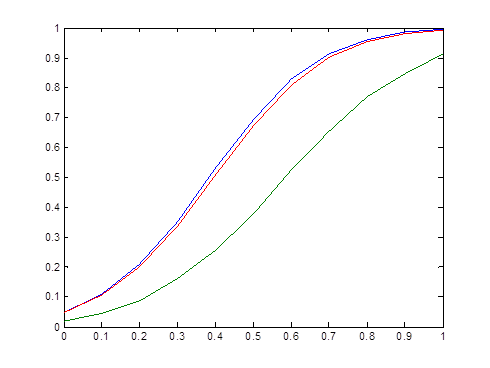
图3-2 功效函数比较图
当总体为正态总体时,可以看出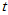 检验功效较高,Wilcoxon符号秩检验功效稍差,符号检验功效很差。
检验功效较高,Wilcoxon符号秩检验功效稍差,符号检验功效很差。
如果总体不是正态总体,例如服从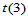 +m,将上述p123.m程序中取样本的语句改为:
+m,将上述p123.m程序中取样本的语句改为:
x=trnd(3,1,20)+m(mm);
则结果Wilcoxon符号秩检验功效明显高于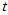 检验,结果如下
检验,结果如下
P =
0.0472 0.0881 0.1499 0.2350 0.3368 0.4436 0.5442 0.6512 0.7230 0.8092 0.8541
0.0218 0.0456 0.0829 0.1462 0.2305 0.3247 0.4271 0.5480 0.6482 0.7496 0.8260
0.0482 0.0941 0.1633 0.2701 0.3883 0.5145 0.6252 0.7419 0.8134 0.8944 0.9297
如果总体服从自由度为1的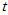 分布,即Cauchy分布,将抽样语句改为:
分布,即Cauchy分布,将抽样语句改为:
x=trnd(1,1,20)+m(mm);
计算结果如下
P =
0.0311 0.0453 0.0574 0.0785 0.1020 0.1199 0.1569 0.1934 0.2270 0.2423 0.2767
0.0199 0.0395 0.0732 0.1145 0.1691 0.2294 0.3137 0.3944 0.4775 0.5495 0.6087
0.0485 0.0815 0.1303 0.1815 0.2412 0.3020 0.3794 0.4556 0.5294 0.5896 0.6443
可以发现,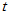 检验的表现极差,功效比符号检验小很多。
检验的表现极差,功效比符号检验小很多。
3.5 总体分布的假设检验
设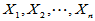 为来自总体
为来自总体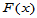 的简单随机样本,
的简单随机样本,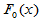 为已知的一个固定的分布函数,要进行如下的检验:
为已知的一个固定的分布函数,要进行如下的检验:
H0: H1:
H1: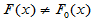
对此检验问题,有两种常用的方法。
对总体分布进行假设检验,一般要求样本容量较大,例如至少100。
3.5.1
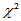 检验
检验
取正整数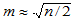 ,将样本排序为
,将样本排序为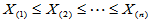 ,将区间
,将区间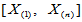
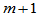 等分,分点为
等分,分点为
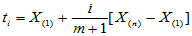 ,
, 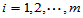
这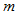 个分点将
个分点将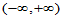 分割为
分割为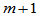 个小区间,
个小区间,
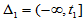 ,
,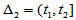 ,
,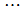 ,
,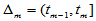 ,
,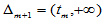
记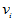 为落入
为落入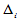 的样本点的个数,显然
的样本点的个数,显然 ,称
,称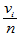 为
为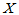 落入
落入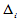 的频率。
的频率。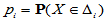 表示H0成立时
表示H0成立时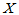 落入
落入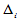 的概率,即
的概率,即
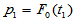 ,
,
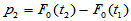 ,
,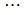 ,
,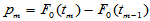 ,
,

检验统计量取为:
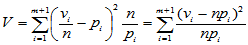
可以证明,当H0成立时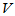 近似服从自由度为
近似服从自由度为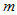 的
的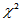 分布,对于显著性水平
分布,对于显著性水平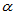 ,取临界值
,取临界值
v0=chi2inv(1-alpha,m)
当V>v0时,拒绝H0。以下自定义函数文件ftc.m用于检验,调用格式是
[H,VV,v0]=ftc(x,alpha)
其中x为样本,alpha为检验的显著性水平,这两个是输入变量,使用前必须赋值;三个输出变量,H等于0或者1,分别表示接受原假设、拒绝原假设,VV为检验统计量的值,v0为临界值。另外,使用之前必须保存函数文件F0.m才能使用,例如
function y=F0(x)
y=normcdf(x);
定义了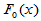 之后,就可以使用下面的ftc.m用于检验了。
之后,就可以使用下面的ftc.m用于检验了。
function [H,VV,v0]=ftc(x,alpha)
n=length(x);
m=floor(sqrt(n、2));
x=sort(x);
a=x(1); b=x(n); d=b-a;
t=zeros(1,m);
for i=1:m
t(i)=a+i*d/(m+1);
end
v=zeros(1,m+1);
p=zeros(1,m+1);
p(1)=F0(t(1)); p(m+1)=1-F0(t(m));
for i=2:m
p(i)=F0(t(i))-F0(t(i-1));
end
i=1; j=1;
while x(j)<=t(m)
if x(j)<=t(i)
v(i)=v(i)+1;
j=j+1;
else
i=i+1;
end
end
v(m+1)=n-sum(v);
VV=0;
for i=1:m+1
VV=VV+(v(i)-n*p(i))^2/(n*p(i));
end
v0=chi2inv(1-alpha,m);
H=0;
if VV>v0
H=1;
end
以下在Matlab命令窗口中键入如下命令,尝试使用如上检验,为避免大量数据输入,采用随机数。
x=trnd(5,1,100);
[H,VV,v0]=ftc(x,0.05)
计算结果为:H =1, VV =
69.3992,v0 =
14.0671。我们从自由度为5的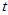 分布总体中抽取容量为100的样本,冒充标准正态分布,结果被检验出原假设不成立,总体不是标准正态分布。当自由度变大时,例如80,
分布总体中抽取容量为100的样本,冒充标准正态分布,结果被检验出原假设不成立,总体不是标准正态分布。当自由度变大时,例如80,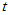 分布很接近标准正态分布,这是就检验不出来了。读者自行尝试。
分布很接近标准正态分布,这是就检验不出来了。读者自行尝试。
3.5.2 Kolmogorov检验
Kolmogorov检验利用的是经验分布函数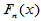 :
:
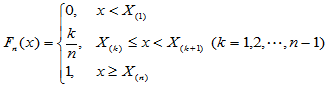
检验统计量为
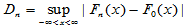
可以证明,对于任意的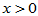 ,
,
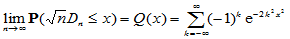
为了求出临界值,先给出自定义函数KolQ.m用于计算上述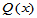 。
。
function Q=KolQ(x)
n=length(x);
for i=1:n
Q(i)=0;
if x(i)>0
a=1;
k=1;
while abs(a)>10^(-10)
Q(i)=Q(i)+a;
a=2*(exp(-2*k^2*x(i)^2))*(-1)^k;
k=k+1;
end
end
end
上述函数编写成了可以处理向量,这样可以方便作图。键入命令:
x=0.3:0.01:1.3;
Q=KolQ(x);
plot(x,Q)
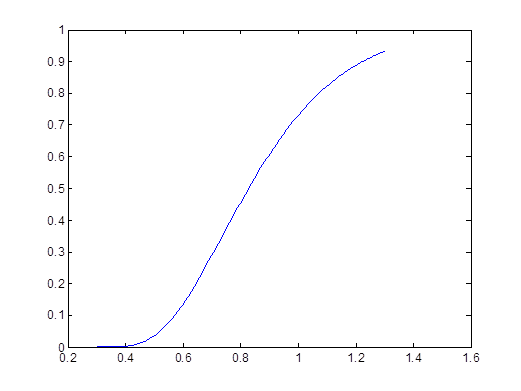
图3-3 Q(x)的图形
上述命令得到图3-3,易见在我们关心的范围内,Q(x)单调增加,这为我们下面用二分法求临界值提供了依据。如果根据计算出的Q(x)值,反向查表得到临界值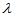 ,使得
,使得
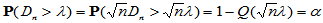
则拒绝域为: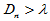 。以下函数KolDinv.m给出了求临界值的方法。
。以下函数KolDinv.m给出了求临界值的方法。
function lambda=KolDinv(n,alpha)
pp=1-alpha;
s=sqrt(n);
a=1/s;
b=1;
for k=1:40
c=(a+b)/2;
lambda=(a+b)/2;
x=s*lambda;
if KolQ(x)>pp
b=c;
else
a=c;
end
end
这里给出的计算程序是经过反复验证的,与教科书附表有较大误差,说明原来教科书计算的舍入误差较大,多年流传下来没有更新。
有了临界值,还需要计算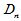 的值。由于经验分布函数是阶梯函数,而总体分布函数是单调增加的,故上确界一定会在样本点处取得。因此,只需要计算诸
的值。由于经验分布函数是阶梯函数,而总体分布函数是单调增加的,故上确界一定会在样本点处取得。因此,只需要计算诸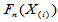 的左右极限与
的左右极限与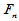 的差异即可。
的差异即可。
以下只考虑连续总体,样本点相同值情形,给出求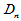 的方法。
的方法。
function D=KolD(x)
n=length(x);
x=sort(x);
D=0;
for i=1:n
a=abs( F0(x(i))-(i-1)/n );
b=abs( F0(x(i))-i/n );
c=max(a,b);
if D<c
D=c;
end
end
要调用函数D=KolD(x),首先在Matlab默认的保存路径中应该还有函数文件F0.m,这样就可以进行检验了。
以上给出了两种检验总体分布的方法,下面对两种方法进行比较。不妨取定总体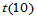 ,样本容量为50,分别使用两种方法检验:
,样本容量为50,分别使用两种方法检验:
H0:样本来自标准正态总体;
H1:样本不是来自标准正态总体;
看看哪种方法拒绝的概率大,为此进行万次抽样,分别计算两者的拒绝频率。注意,由于临界值是固定的,因此一定在万次循环之前首先求出。否则,求临界值比计算统计量麻烦得多,每次多用0.1秒钟,万次循环也受不了。请读者自行编程解决两种方法的比较问题。
