这个HBase学习了第二遍也不是太透彻
PS:
启动Hbase之前先启动Zookeeper、HDFS、yarn
1. hbase简介(是基于HDFS.相当于是一个缓存层)
1.1. 什么是hbase(列式的分布式数据库)
HBASE是一个高可靠性、高性能、面向列(以前学习的Mysql都是面向行的)、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理(既能存储又能处理,MapReduce能运行在HDFS就能运行在HBASE上,因为HBASE的底层是存到HDFS上的)大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
PS: HDFS只能保存128M的数据,所以出现了HBase,把数据放在上层,每满了128M向下保存到HDFS中,这就是出现HDDFS的部分原因。
PS:
1.Hbase是列式分布式系统,不能多表关联。 只能存储数据
1.1. 与传统数据库的对比
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
1.2. hbase集群中的角色
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer
----------------------------HBase的安装
1.上传文件

2.解压,重命名
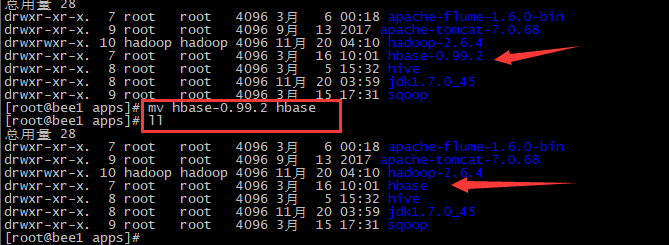
3.添加系统环境变量

PS:所有gc都换成bee1,然后依次是发送给bee2,bee3;根据下面的进行安装
http://blog.csdn.net/achuo/article/details/51170946
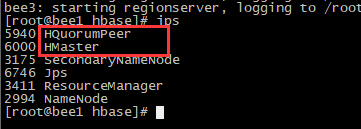
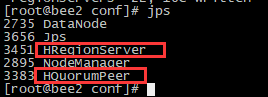
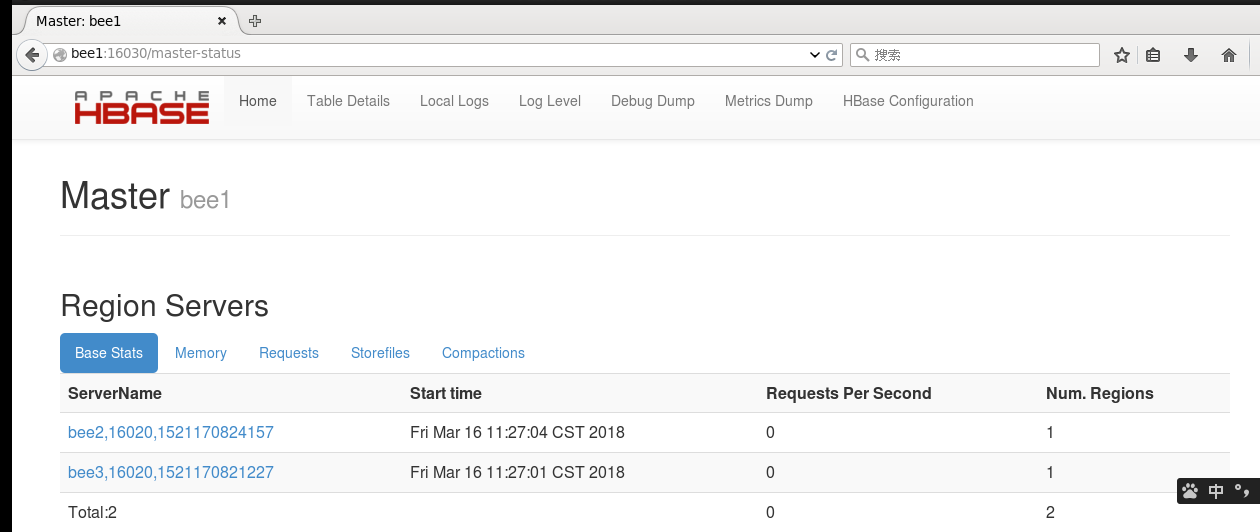
PS:安装成功如图所示
--------------------------------Hbase数据结构
1.1. hbase数据模型
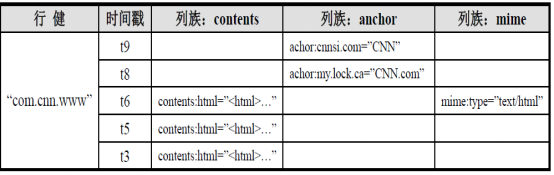
PS:行键类似于id; 时间戳每保存数据,都有一个版本
与nosql数据库们一样,row key是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个row key访问
2.通过row key的range(正则)
3.全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度 是 64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储。
设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
1.1.1. Columns Family
列簇 :HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
1.1.1. Cell
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存贮。

关键字:无类型、字节码
1.1.2. Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。

PS:如上图excel所示,列族就是多个列的组合; 一个列族就是一个表,就是一个文件
--------HBase Shell模式
PS:输入 hbase shell 进入该模式

|
名称 |
命令表达式 |
|
创建表 |
create '表名', '列族名1','列族名2','列族名N' |
|
查看所有表 |
list |
|
描述表 |
describe ‘表名’ |
|
判断表存在 |
exists '表名' |
|
判断是否禁用启用表 |
is_enabled '表名' is_disabled ‘表名’ |
|
添加记录 |
put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , '值' |
|
查看记录rowkey下的所有数据 |
get '表名' , 'rowKey' |
|
查看表中的记录总数 |
count '表名' |
|
获取某个列族 |
get '表名','rowkey','列族' |
|
获取某个列族的某个列 |
get '表名','rowkey','列族:列’ |
|
删除记录 |
delete ‘表名’ ,‘行名’ , ‘列族:列' |
|
删除整行 |
deleteall '表名','rowkey' |
|
删除一张表 |
先要屏蔽该表,才能对该表进行删除 第一步 disable ‘表名’ ,第二步 drop '表名' |
|
清空表 |
truncate '表名' |
|
查看所有记录 |
scan "表名" |
|
查看某个表某个列中所有数据 |
scan "表名" , {COLUMNS=>'列族名:列名'} |
|
更新记录 |
就是重写一遍,进行覆盖,hbase没有修改,都是追加 |
PS:保存数据,然后显示
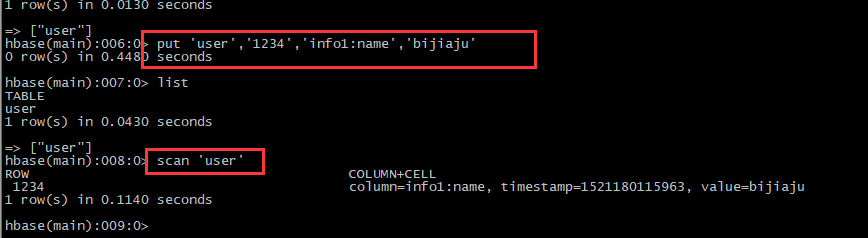

PS:HBase写 快 读 慢。
PS:HBase的API
package cn.itcast_01_hbase; import java.util.ArrayList; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.MasterNotRunningException; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.ZooKeeperConnectionException; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HConnection; import org.apache.hadoop.hbase.client.HConnectionManager; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.filter.ColumnPrefixFilter; import org.apache.hadoop.hbase.filter.CompareFilter; import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.filter.FilterList.Operator; import org.apache.hadoop.hbase.filter.RegexStringComparator; import org.apache.hadoop.hbase.filter.RowFilter; import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; import org.apache.hadoop.hbase.util.Bytes; import org.junit.After; import org.junit.Before; import org.junit.Test; public class HbaseTest { /** * 配置ss */ static Configuration config = null; private Connection connection = null; private Table table = null; @Before public void init() throws Exception { config = HBaseConfiguration.create();// 配置 config.set("hbase.zookeeper.quorum", "master,work1,work2");// zookeeper地址 config.set("hbase.zookeeper.property.clientPort", "2181");// zookeeper端口 connection = ConnectionFactory.createConnection(config); table = connection.getTable(TableName.valueOf("user")); } /** * 创建一个表 * * @throws Exception */ @Test public void createTable() throws Exception { // 创建表管理类 HBaseAdmin admin = new HBaseAdmin(config); // hbase表管理 // 创建表描述类 TableName tableName = TableName.valueOf("test3"); // 表名称 HTableDescriptor desc = new HTableDescriptor(tableName); // 创建列族的描述类 HColumnDescriptor family = new HColumnDescriptor("info"); // 列族 // 将列族添加到表中 desc.addFamily(family); HColumnDescriptor family2 = new HColumnDescriptor("info2"); // 列族 // 将列族添加到表中 desc.addFamily(family2); // 创建表 admin.createTable(desc); // 创建表 } @Test @SuppressWarnings("deprecation") public void deleteTable() throws MasterNotRunningException, ZooKeeperConnectionException, Exception { HBaseAdmin admin = new HBaseAdmin(config); admin.disableTable("test3"); admin.deleteTable("test3"); admin.close(); } /** * 向hbase中增加数据 * * @throws Exception */ @SuppressWarnings({ "deprecation", "resource" }) @Test public void insertData() throws Exception { table.setAutoFlushTo(false); table.setWriteBufferSize(534534534); ArrayList<Put> arrayList = new ArrayList<Put>(); for (int i = 21; i < 50; i++) { Put put = new Put(Bytes.toBytes("1234"+i)); put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("wangwu"+i)); put.add(Bytes.toBytes("info"), Bytes.toBytes("password"), Bytes.toBytes(1234+i)); arrayList.add(put); } //插入数据 table.put(arrayList); //提交 table.flushCommits(); } /** * 修改数据 * * @throws Exception */ @Test public void uodateData() throws Exception { Put put = new Put(Bytes.toBytes("1234")); put.add(Bytes.toBytes("info"), Bytes.toBytes("namessss"), Bytes.toBytes("lisi1234")); put.add(Bytes.toBytes("info"), Bytes.toBytes("password"), Bytes.toBytes(1234)); //插入数据 table.put(put); //提交 table.flushCommits(); } /** * 删除数据 * * @throws Exception */ @Test public void deleteDate() throws Exception { Delete delete = new Delete(Bytes.toBytes("1234")); table.delete(delete); table.flushCommits(); } /*********************************下面这三个都是查询*/ /** * 单条查询 * * @throws Exception */ @Test public void queryData() throws Exception { Get get = new Get(Bytes.toBytes("1234")); Result result = table.get(get); System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password")))); System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("namessss")))); System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")))); } /** * 全表扫描 * * @throws Exception */ @Test public void scanData() throws Exception { Scan scan = new Scan(); //scan.addFamily(Bytes.toBytes("info")); //scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("password")); scan.setStartRow(Bytes.toBytes("wangsf_0"));//从哪开始 scan.setStopRow(Bytes.toBytes("wangwu"));//从哪结束 ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password")))); System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")))); //System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password")))); //System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")))); } }
6.13.2.过滤器的种类
过滤器的种类:
列植过滤器—SingleColumnValueFilter
过滤列植的相等、不等、范围等
列名前缀过滤器—ColumnPrefixFilter
过滤指定前缀的列名
多个列名前缀过滤器—MultipleColumnPrefixFilter
过滤多个指定前缀的列名
rowKey过滤器—RowFilter
通过正则,过滤rowKey值。
/** * 全表扫描的过滤器 * 列值过滤器 * * @throws Exception */ @Test public void scanDataByFilter1() throws Exception { // 创建全表扫描的scan Scan scan = new Scan(); //过滤器:列值过滤器 SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, Bytes.toBytes("zhangsan2")); // 设置过滤器 scan.setFilter(filter); // 打印结果集 ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password")))); System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")))); //System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password")))); //System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")))); } } /** * rowkey过滤器 应用比较广泛的 * @throws Exception */ @Test public void scanDataByFilter2() throws Exception { // 创建全表扫描的scan Scan scan = new Scan(); //匹配rowkey以wangsenfeng开头的 RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^12341")); // 设置过滤器 scan.setFilter(filter); // 打印结果集 ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password")))); System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")))); //System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password")))); //System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")))); } } /** * 匹配列名前缀 * @throws Exception */ @Test public void scanDataByFilter3() throws Exception { // 创建全表扫描的scan Scan scan = new Scan(); //匹配rowkey以wangsenfeng开头的 ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("na")); // 设置过滤器 scan.setFilter(filter); // 打印结果集 ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("rowkey:" + Bytes.toString(result.getRow())); System.out.println("info:name:" + Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")))); // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")) != null) { System.out.println("info:age:" + Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")) != null) { System.out.println("infi:sex:" + Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")) != null) { System.out .println("info2:name:" + Bytes.toString(result.getValue( Bytes.toBytes("info2"), Bytes.toBytes("name")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")) != null) { System.out.println("info2:age:" + Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")) != null) { System.out.println("info2:sex:" + Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")))); } } } /** * 过滤器集合 * @throws Exception */ @Test public void scanDataByFilter4() throws Exception { // 创建全表扫描的scan Scan scan = new Scan(); //过滤器集合:MUST_PASS_ALL(and),MUST_PASS_ONE(or) FilterList filterList = new FilterList(Operator.MUST_PASS_ONE); //匹配rowkey以wangsenfeng开头的 RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^wangsenfeng")); //匹配name的值等于wangsenfeng SingleColumnValueFilter filter2 = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, Bytes.toBytes("zhangsan")); filterList.addFilter(filter); filterList.addFilter(filter2); // 设置过滤器 scan.setFilter(filterList); // 打印结果集 ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("rowkey:" + Bytes.toString(result.getRow())); System.out.println("info:name:" + Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")))); // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")) != null) { System.out.println("info:age:" + Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")) != null) { System.out.println("infi:sex:" + Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")) != null) { System.out .println("info2:name:" + Bytes.toString(result.getValue( Bytes.toBytes("info2"), Bytes.toBytes("name")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")) != null) { System.out.println("info2:age:" + Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")))); } // 判断取出来的值是否为空 if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")) != null) { System.out.println("info2:sex:" + Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")))); } } } @After public void close() throws Exception { table.close(); connection.close(); } }
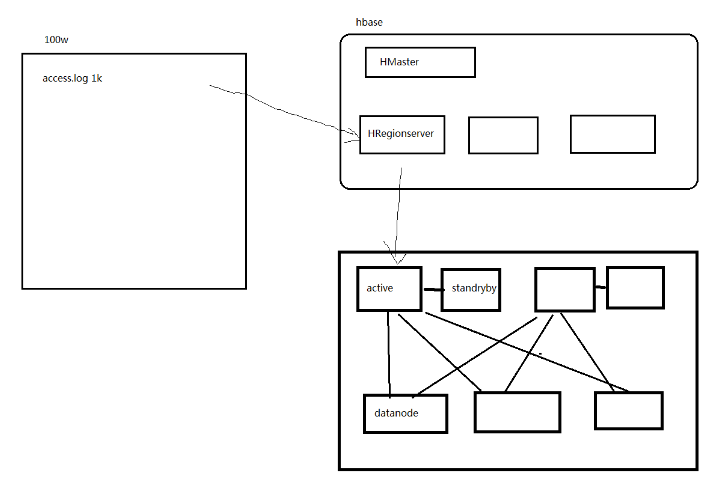
1. hbase原理
1.1. 体系图
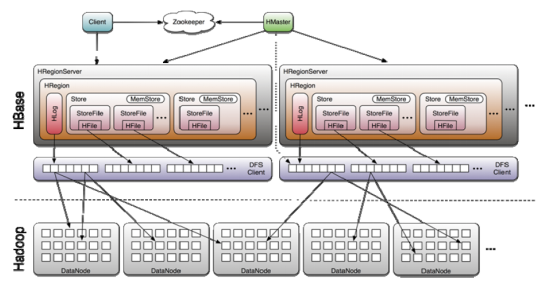
1.1.1. 写流程
1、 client向hregionserver发送写请求。
2、 hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
3、 hregionserver将数据写到内存(memstore)
4、 反馈client写成功。
1.1.2. 数据flush过程
1、 当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除Hlog中的历史数据。
2、 并将数据存储到hdfs中。
3、 在hlog中做标记点。
1.1.3. 数据合并过程
1、 当数据块达到4块,hmaster将数据块加载到本地,进行合并
2、 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
3、 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
4、 注意:hlog会同步到hdfs
1.1.4. hbase的读流程
1、 通过zookeeper和-ROOT- .META.表定位hregionserver。
2、 数据从内存和硬盘合并后返回给client
3、 数据块会缓存
1.1.5. hmaster的职责
1、管理用户对Table的增、删、改、查操作;
2、记录region在哪台Hregion server上
3、在Region Split后,负责新Region的分配;
4、新机器加入时,管理HRegion Server的负载均衡,调整Region分布
5、在HRegion Server宕机后,负责失效HRegion Server 上的Regions迁移。
1.1.6. hregionserver的职责
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
HRegion Server管理了很多table的分区,也就是region。
1. MapReduce操作Hbase
1.1. 实现方法
Hbase对MapReduce提供支持,它实现了TableMapper类和TableReducer类,我们只需要继承这两个类即可。
1、写个mapper继承TableMapper<Text, IntWritable>
参数:Text:mapper的输出key类型; IntWritable:mapper的输出value类型。
其中的map方法如下:
map(ImmutableBytesWritable key, Result value,Context context)
参数:key:rowKey;value: Result ,一行数据; context上下文
2、写个reduce继承TableReducer<Text, IntWritable, ImmutableBytesWritable>
参数:Text:reducer的输入key; IntWritable:reduce的输入value;
ImmutableBytesWritable:reduce输出到hbase中的rowKey类型。
其中的reduce方法如下:
reduce(Text key, Iterable<IntWritable> values,Context context)
参数: key:reduce的输入key;values:reduce的输入value;
1.2. 准备表
1、建立数据来源表‘word’,包含一个列族‘content’
向表中添加数据,在列族中放入列‘info’,并将短文数据放入该列中,如此插入多行,行键为不同的数据即可
2、建立输出表‘stat’,包含一个列族‘content’
3、通过Mr操作Hbase的‘word’表,对‘content:info’中的短文做词频统计,并将统计结果写入‘stat’表的‘content:info中’,行键为单词
package cn.itcast_01_hbase; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; /** * mapreduce操作hbase * @author wilson * */ public class HBaseMr { /** * 创建hbase配置 */ static Configuration config = null; static { config = HBaseConfiguration.create(); config.set("hbase.zookeeper.quorum", "slave1,slave2,slave3"); config.set("hbase.zookeeper.property.clientPort", "2181"); } /** * 表信息 */ public static final String tableName = "word";//表名1 public static final String colf = "content";//列族 public static final String col = "info";//列 public static final String tableName2 = "stat";//表名2 /** * 初始化表结构,及其数据 */ public static void initTB() { HTable table=null; HBaseAdmin admin=null; try { admin = new HBaseAdmin(config);//创建表管理 /*删除表*/ if (admin.tableExists(tableName)||admin.tableExists(tableName2)) { System.out.println("table is already exists!"); admin.disableTable(tableName); admin.deleteTable(tableName); admin.disableTable(tableName2); admin.deleteTable(tableName2); } /*创建表*/ HTableDescriptor desc = new HTableDescriptor(tableName); HColumnDescriptor family = new HColumnDescriptor(colf); desc.addFamily(family); admin.createTable(desc); HTableDescriptor desc2 = new HTableDescriptor(tableName2); HColumnDescriptor family2 = new HColumnDescriptor(colf); desc2.addFamily(family2); admin.createTable(desc2); /*插入数据*/ table = new HTable(config,tableName); table.setAutoFlush(false); table.setWriteBufferSize(500); List<Put> lp = new ArrayList<Put>(); Put p1 = new Put(Bytes.toBytes("1")); p1.add(colf.getBytes(), col.getBytes(), ("The Apache Hadoop software library is a framework").getBytes()); lp.add(p1); Put p2 = new Put(Bytes.toBytes("2"));p2.add(colf.getBytes(),col.getBytes(),("The common utilities that support the other Hadoop modules").getBytes()); lp.add(p2); Put p3 = new Put(Bytes.toBytes("3")); p3.add(colf.getBytes(), col.getBytes(),("Hadoop by reading the documentation").getBytes()); lp.add(p3); Put p4 = new Put(Bytes.toBytes("4")); p4.add(colf.getBytes(), col.getBytes(),("Hadoop from the release page").getBytes()); lp.add(p4); Put p5 = new Put(Bytes.toBytes("5")); p5.add(colf.getBytes(), col.getBytes(),("Hadoop on the mailing list").getBytes()); lp.add(p5); table.put(lp); table.flushCommits(); lp.clear(); } catch (Exception e) { e.printStackTrace(); } finally { try { if(table!=null){ table.close(); } } catch (IOException e) { e.printStackTrace(); } } } /** * MyMapper 继承 TableMapper * TableMapper<Text,IntWritable> * Text:输出的key类型, * IntWritable:输出的value类型 */ public static class MyMapper extends TableMapper<Text, IntWritable> { private static IntWritable one = new IntWritable(1); private static Text word = new Text(); @Override //输入的类型为:key:rowKey; value:一行数据的结果集Result protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { //获取一行数据中的colf:col String words = Bytes.toString(value.getValue(Bytes.toBytes(colf), Bytes.toBytes(col)));// 表里面只有一个列族,所以我就直接获取每一行的值 //按空格分割 String itr[] = words.toString().split(" "); //循环输出word和1 for (int i = 0; i < itr.length; i++) { word.set(itr[i]); context.write(word, one); } } } /** * MyReducer 继承 TableReducer * TableReducer<Text,IntWritable> * Text:输入的key类型, * IntWritable:输入的value类型, * ImmutableBytesWritable:输出类型,表示rowkey的类型 */ public static class MyReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //对mapper的数据求和 int sum = 0; for (IntWritable val : values) {//叠加 sum += val.get(); } // 创建put,设置rowkey为单词 Put put = new Put(Bytes.toBytes(key.toString())); // 封装数据 put.add(Bytes.toBytes(colf), Bytes.toBytes(col),Bytes.toBytes(String.valueOf(sum))); //写到hbase,需要指定rowkey、put context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())),put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { config.set("df.default.name", "hdfs://master:9000/");//设置hdfs的默认路径 config.set("hadoop.job.ugi", "hadoop,hadoop");//用户名,组 config.set("mapred.job.tracker", "master:9001");//设置jobtracker在哪 //初始化表 initTB();//初始化表 //创建job Job job = new Job(config, "HBaseMr");//job job.setJarByClass(HBaseMr.class);//主类 //创建scan Scan scan = new Scan(); //可以指定查询某一列 scan.addColumn(Bytes.toBytes(colf), Bytes.toBytes(col)); //创建查询hbase的mapper,设置表名、scan、mapper类、mapper的输出key、mapper的输出value TableMapReduceUtil.initTableMapperJob(tableName, scan, MyMapper.class,Text.class, IntWritable.class, job); //创建写入hbase的reducer,指定表名、reducer类、job TableMapReduceUtil.initTableReducerJob(tableName2, MyReducer.class, job); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
-----------------------day17
PS:Redis就是个Map; Mongdb就是个List
PS:云笔记这个项目就是 保存形式是用hbase保存的,而不是使用mysql; 还有就是使用hive操作hbase