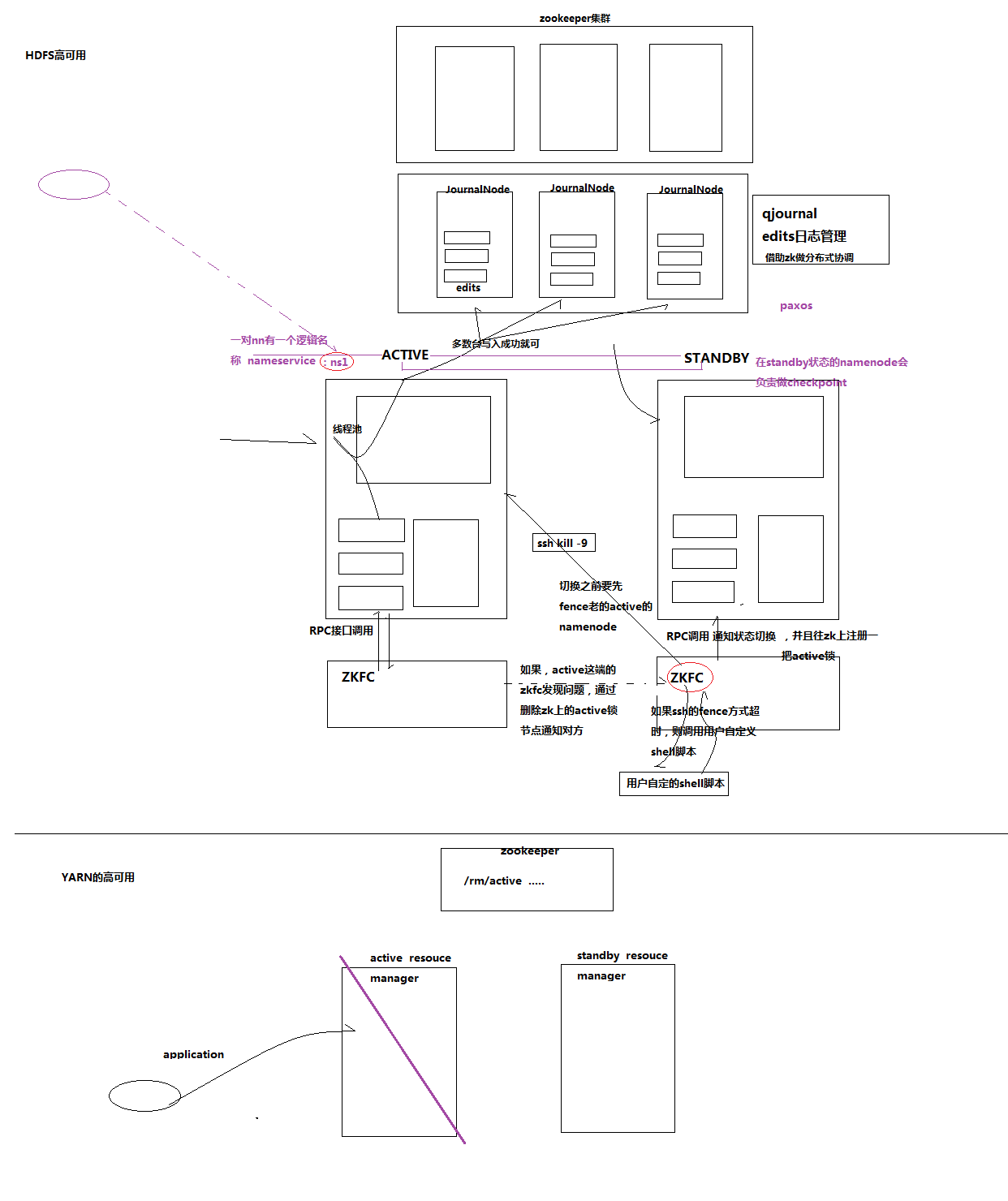
PS:视频一直就是在演示 高可用(比较偏运维一点)

PS:
Active是对外提供服务的,standBy是从属备用的;但是他们是怎样保证同步的数据的呢?一个运行中zookeeper上的第三方那个工具 qJournal
PS:什么时候感知到服务挂了呢,进行切换呢?就是使用zkfc技术
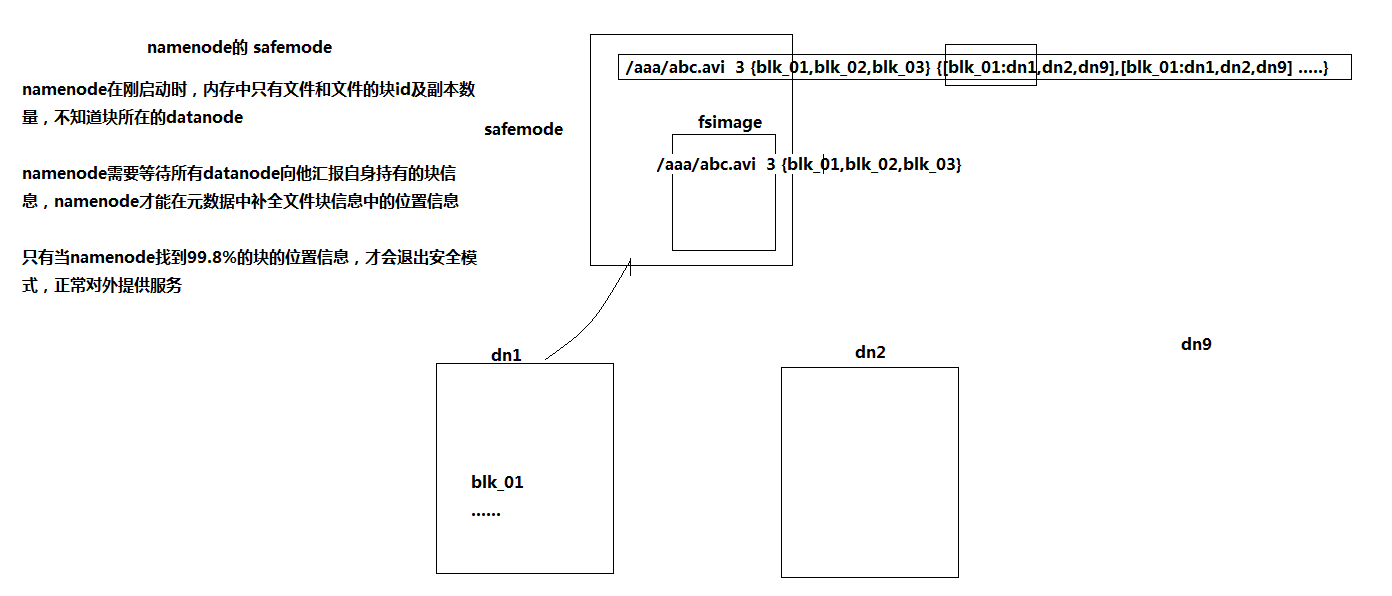
PS:namenode的安全模式
PS:Ferdaration是就是由多个HDFS构成。一般用的比较少
---------------------------Hive
1.1.1 什么是Hive
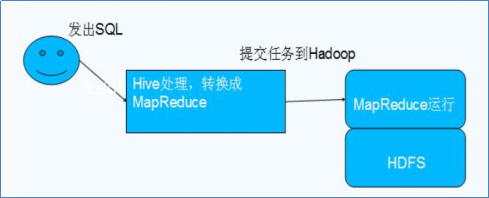
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
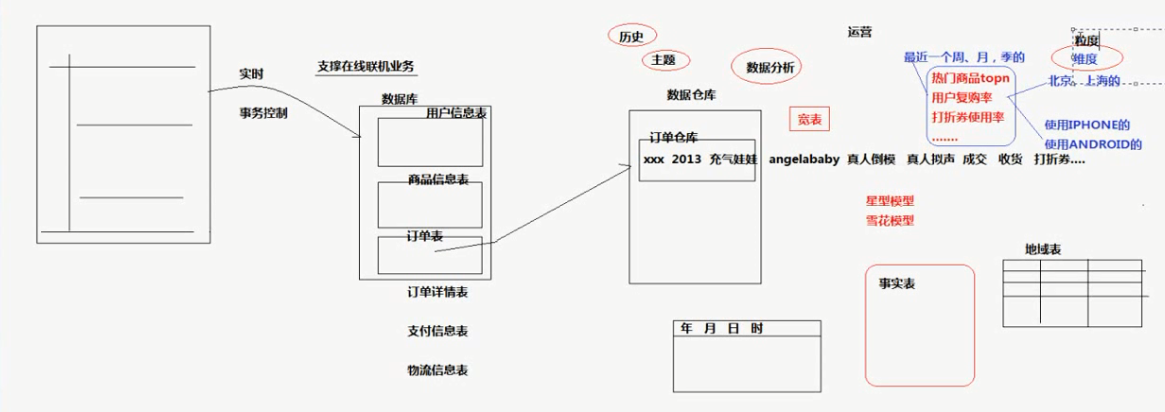
PS:数据仓库, 如下图左边是一个网站,中间是相应的数据库,但是随着数据的增多,网站运行变得缓慢。这时,就会把一些不常用的表保存起来,比如订单表,他在数据库中保存的形式
是宽表,以不同的粒度和维度去保存,结构形式是星系或者雪花型
1.1.1 为什么使用Hive
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
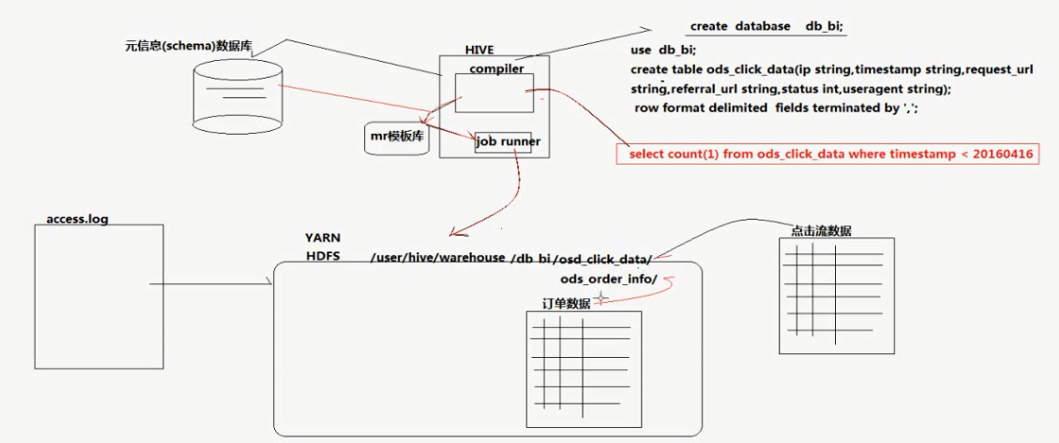
PS:它可以使用sql去生成MapReduce程序,首先在HDFS文件中,不同的sql会得到不同的结构表。
在生成MapReduce程序上,Hive内部有一个编译器,会把SQL语言执行生成为MapReduce程序,而且内部会有一个表,记录着数据表的信息。
----------------------------------------------Hive的安装与体验-------
PS:Hive是一个工具不是集群。可以放在任何一台机器上
1.启动hdfs
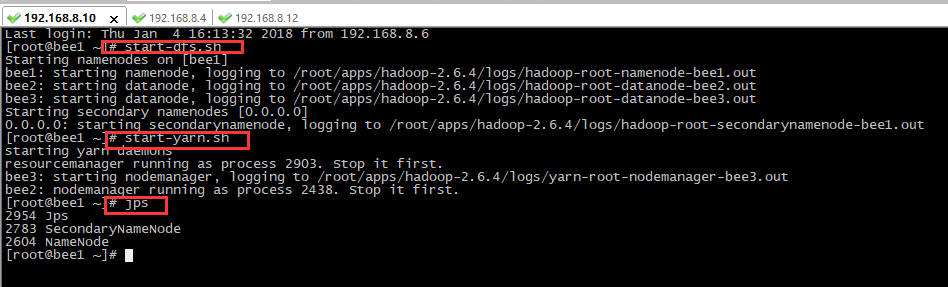
2.上传jar包

解压文件、移除包、重命名文件夹
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps/

------------------------
其实,我们什么也不用配置就能启动hive,但是hive使用的是dubin数据库,所以我们使用mysql,测试mysql使用第一句

在hive/conf中创建hive-site.xml文件
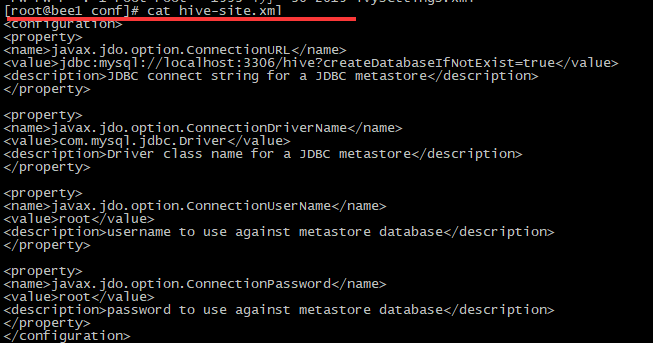
根据上面配置文件需要classpath 的驱动包,hive的classpath在lib中
下图为上传以后,查找文件

PS:启动的时候一定要这样写,出现这个问题的原因就是hive 中jline比hadoop的版本要高,所以要替换hadoop中的jline(功能是提供命令行敲字符)
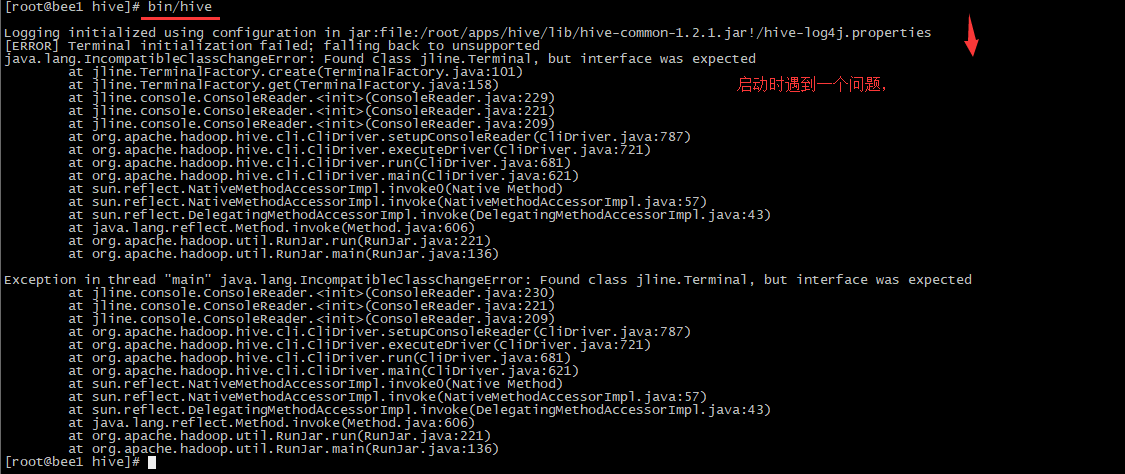
解决问题,删除,复制


----------------------------------Hive初体验
QQ: Linux中hive无法使用Delete和Backspace删除键
1.创建数据库,然后在hdfs中有个shizhan03.db的文件


2.在这个库里面创建 表格


1.编辑数据,上传到hdfs


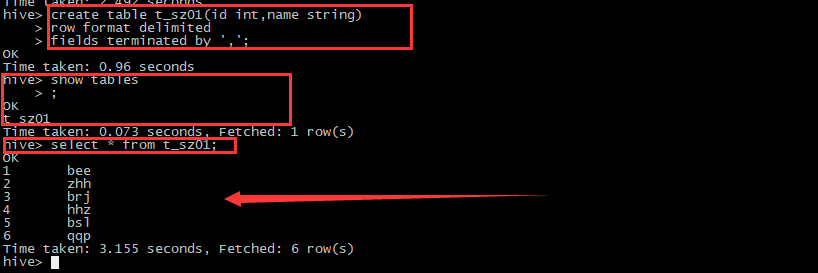
2.创建库,查找上传后的数据
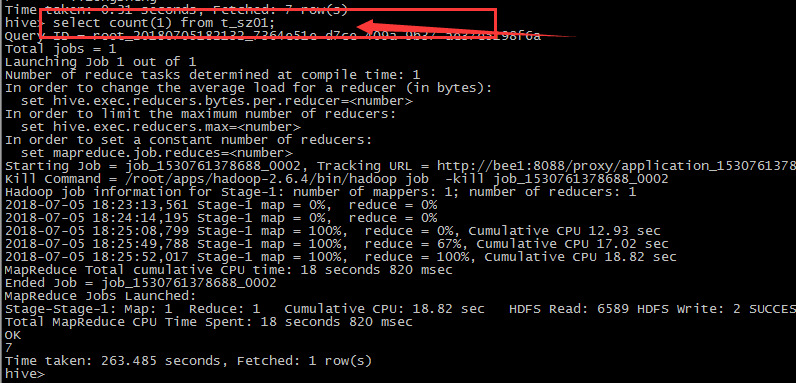
PS: 后天执行的mapReduce
-----------------------------------------概念
1.1 Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据
1.2 Hive与传统数据库对比

总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析

1.6.2 启动hive的方种形式
Hive交互shell
bin/hive
Hive thrift服务
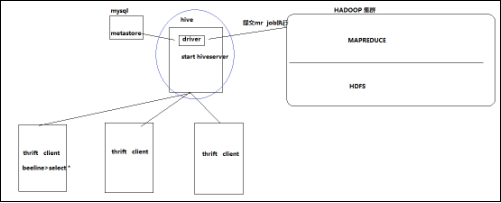
启动方式,(假如是在hadoop01上):
启动为前台:bin/hiveserver2
启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
启动成功后,可以在别的节点上用beeline去连接
v 方式(1)
hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//mini1:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
方式(2)
或者启动就连接:
bin/beeline -u jdbc:hive2://mini1:10000 -n hadoop
接下来就可以做正常sql查询了


------------------------------------------





PS:加载数据还可以使用hadoop -fs put ,提交到某个位置


PS:
1.Hive在解析数据的时候, 符合格式的就自动解析出来,不符合的直接解析为NULL
2.外和内表在删除时结构会自动删除,但是外表的数据还在
3.分区 这个概念他是一个 伪字段,但是由于这些他会在数据查询的时候自动帮你查找,但是不是真正的字段数据
作用:就是让你在统计的时候少统计一些数据,体现在数据上就是文件夹
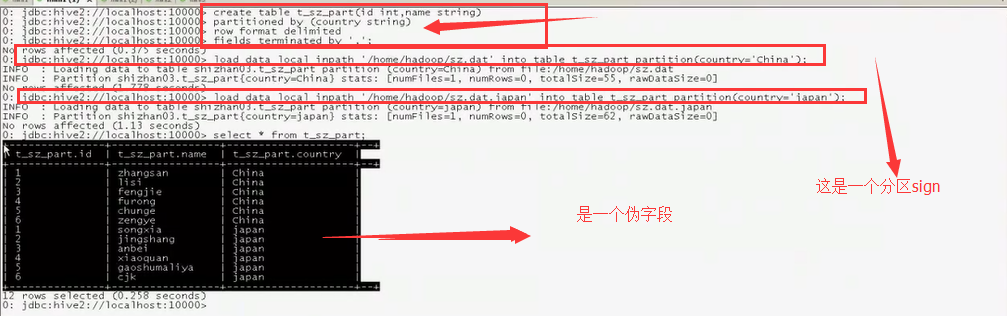
-----------------------分桶概念------------
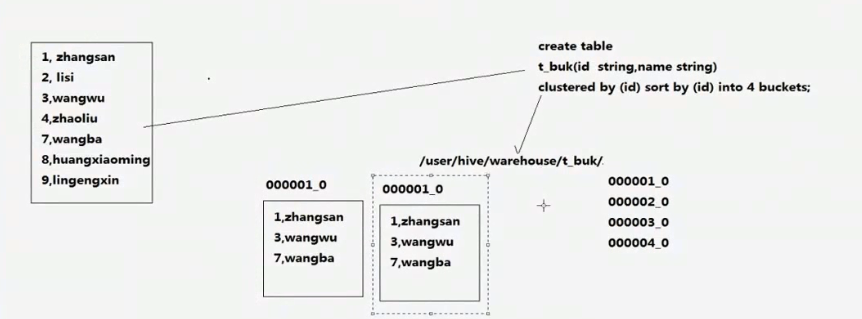
PS:分桶的数据不适合 load进来,适合 select 的数据
---------------------------Join操作,不明白的话看文档--------------------------
关于hive中的各种join
准备数据
1,a
2,b
3,c
4,d
7,y
8,u
2,bb
3,cc
7,yy
9,pp
建表:
create table a(id int,name string)
row format delimited fields terminated by ',';
create table b(id int,name string)
row format delimited fields terminated by ',';
导入数据:
load data local inpath '/home/hadoop/a.txt' into table a;
load data local inpath '/home/hadoop/b.txt' into table b;
实验:
** inner join
select * from a inner join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 7 | y | 7 | yy |
+-------+---------+-------+---------+--+
**left join
select * from a left join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 1 | a | NULL | NULL |
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 4 | d | NULL | NULL |
| 7 | y | 7 | yy |
| 8 | u | NULL | NULL |
+-------+---------+-------+---------+--+
**right join
select * from a right join b on a.id=b.id;
**
select * from a full outer join b on a.id=b.id;
+-------+---------+-------+---------+--+
| a.id | a.name | b.id | b.name |
+-------+---------+-------+---------+--+
| 1 | a | NULL | NULL |
| 2 | b | 2 | bb |
| 3 | c | 3 | cc |
| 4 | d | NULL | NULL |
| 7 | y | 7 | yy |
| 8 | u | NULL | NULL |
| NULL | NULL | 9 | pp |
+-------+---------+-------+---------+--+
**
select * from a left semi join b on a.id = b.id;
+-------+---------+--+
| a.id | a.name |
+-------+---------+--+
| 2 | b |
| 3 | c |
| 7 | y |
+-------+---------+--+
------------------------------一个大数据广告项目的介绍
PS:
目的:广告商为了精准的对目标客户投放广告
分为三个:用户 、广告中介商 、 广告商
---------------------------------
婷婷是一个女孩,她可以在各种广告提供商浏览数据,不同的提供商提供不同的广告。
当婷婷点击某个按钮以后,含有js代码。到中间商这一层之后,通过广告引擎来推送广告,可以是图片或者是视频
怎样确定婷婷这个女孩的需要呢?
首先,在她浏览的大量数据中,会有各种数据,这个数据经过 图运算以后就会变得有联系,进而形成用户画像仓库。
最后广告推送引擎就是通过对婷婷这个人来进行判断的。

------------------------------Hive有内置函数
PS:自定义函数也都是套路,有模板
4.3 Hive自定义函数和Transform
PS :这些自定义函数就是和mysql类似的 select concat('','') from t_xx ;
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
4.3.1 自定义函数类别
UDF 作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数)
UDAF(用户定义聚集函数):接收多个输入数据行,并产生一个输出数据行。(count,max)
4.3.2 UDF开发实例
1、先开发一个java类,继承UDF,并重载evaluate方法
|
package cn.itcast.bigdata.udf import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class Lower extends UDF{ public Text evaluate(final Text s){ if(s==null){return null;} return new Text(s.toString().toLowerCase()); } } |
2、打成jar包上传到服务器
3、将jar包添加到hive的classpath
hive>add JAR /home/hadoop/udf.jar;
4、创建临时函数与开发好的java class关联
|
Hive>create temporary function toprovince as 'cn.itcast.bigdata.udf.ToProvince'; |
5、即可在hql中使用自定义的函数strip
Select strip(name),age from t_test;
----------------------------------------我的实践--parseJson-------------------------------------
package cn.itcast.bigdata.udf; import org.apache.hadoop.hive.ql.exec.UDF; import parquet.org.codehaus.jackson.map.ObjectMapper; public class JsonParser extends UDF { public String evaluate(String jsonLine) { ObjectMapper objectMapper = new ObjectMapper(); try { MovieRateBean bean = objectMapper.readValue(jsonLine, MovieRateBean.class); return bean.toString(); } catch (Exception e) { } return ""; } }
package cn.itcast.bigdata.udf; //{"movie":"1721","rate":"3","timeStamp":"965440048","uid":"5114"} public class MovieRateBean { private String movie; private String rate; private String timeStamp; private String uid; public String getMovie() { return movie; } public void setMovie(String movie) { this.movie = movie; } public String getRate() { return rate; } public void setRate(String rate) { this.rate = rate; } public String getTimeStamp() { return timeStamp; } public void setTimeStamp(String timeStamp) { this.timeStamp = timeStamp; } public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } @Override public String toString() { return movie + " " + rate + " " + timeStamp + " " + uid; } }
1.编写代码,上传jar
2.创建表格,导入数据


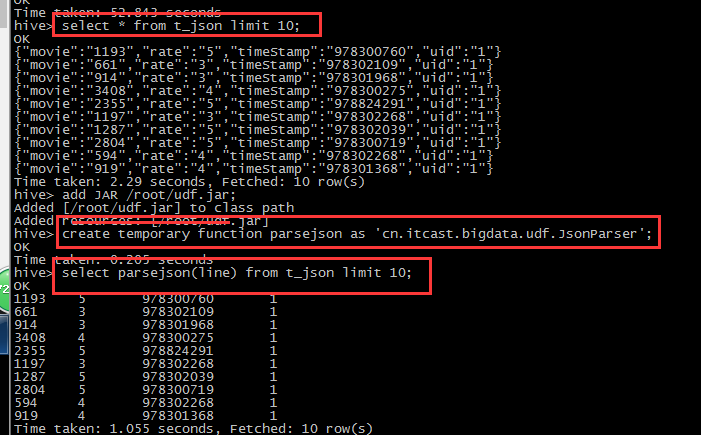
PS: UDF就是为了写适合的 特殊函数
------内置json转换函数

4.3.3 Transform实现
Hive的 TRANSFORM 关键字提供了在SQL中调用自写脚本的功能
适合实现Hive中没有的功能又不想写UDF的情况
使用示例1:下面这句sql就是借用了weekday_mapper.py对数据进行了处理.
|
CREATE TABLE u_data_new ( movieid INT, rating INT, weekday INT, userid INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '; add FILE weekday_mapper.py; INSERT OVERWRITE TABLE u_data_new SELECT TRANSFORM (movieid, rating, unixtime,userid) USING 'python weekday_mapper.py' AS (movieid, rating, weekday,userid) FROM u_data; |
其中weekday_mapper.py内容如下
|
#!/bin/python import sys import datetime for line in sys.stdin: line = line.strip() movieid, rating, unixtime,userid = line.split(' ') weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print ' '.join([movieid, rating, str(weekday),userid]) |
使用示例2:下面的例子则是使用了shell的cat命令来处理数据
|
FROM invites a INSERT OVERWRITE TABLE events SELECT TRANSFORM(a.foo, a.bar) AS (oof, rab) USING '/bin/cat' WHERE a.ds > '2008-08-09'; |
------------------------------------transform案例: 1、先加载rating.json文件到hive的一个原始表 rat_json create table rat_json(line string) row format delimited; load data local inpath '/home/hadoop/rating.json' into table rat_json; 2、需要解析json数据成四个字段,插入一张新的表 t_rating insert overwrite table t_rating select get_json_object(line,'$.movie') as moive,get_json_object(line,'$.rate') as rate from rat_json; 3、使用transform+python的方式去转换unixtime为weekday 先编辑一个python脚本文件 ########python######代码 vi weekday_mapper.py #!/bin/python import sys import datetime for line in sys.stdin: line = line.strip() movieid, rating, unixtime,userid = line.split(' ') weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print ' '.join([movieid, rating, str(weekday),userid]) 保存文件 然后,将文件加入hive的classpath: hive>add FILE /home/hadoop/weekday_mapper.py; hive>create TABLE u_data_new as SELECT TRANSFORM (movieid, rate, timestring,uid) USING 'python weekday_mapper.py' AS (movieid, rate, weekday,uid) FROM t_rating; select distinct(weekday) from u_data_new limit 10;