自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
目录
1 绪论
1.1 概念介绍
1.2 机器学习
1.3 表示学习
1.3.1 局部表示和分布式表示
1.3.2 表示学习
1.4 深度学习
1.4.1 端到端学习
1.5 神经网络
1 绪论
1.1 概念介绍
深度学习是机器学习的一个分支,指从有限的样例中,通过算法总结出规律,可以应用到新的数据上。
人工神经网络是受人脑的神经系统启发而构造的数学模型,神经网络由神经元连接而成,有输入和输出,中间的信息处理传递路径比较长,复杂的神经网络比较深,所以叫深度学习。
人工智能发展时间线

1.2 机器学习
从有限的数据中学习出有一般性的规律,并对未知的数据进行预测。数据有多种多样的数据形式:图像、声音、文本。机器学习处理数据的步骤:
(1) 数据预处理:去噪声,去除文本的停用词。
(2) 特征提取:从原始数据中提取有效的特征。
(3) 特征转换:对特征进一步加工,比如降维:特征抽取,特征选择。常用的特征转换方法有主成分分析和线性判别分析。
(4) 预测。学习一个函数并预测结果。
1.3 表示学习
对原始数据进行一个抽象概括,提高分析预测的抽象能力。例如分析车辆数据,如果基于的是底层数据(汽车的像素数据),每辆车的颜色,形状,大小都不一样,分析了奔驰的数据,保时捷就识别不出。所以需要从更抽象的高层语义上去表示数据的特征,才能提高算法识别的准确性和通用性。那什么是好的表示,如何学到好的表示?
好的表示有三个特点
(1) 强表示能力,同样大小的向量可以表示更多的信息。
(2) 包含高层的语义信息,使后续的任务学习更加简单。
(3) 一般通用性,可以迁移到其他任务。
1.3.1 局部表示和分布式表示
局部表示:以颜色威力,用不同的名字来表示颜色:中国红,琥珀蓝等,也称为离散表示或符号表示,解释性好,用一维向量表示,每种颜色的一维向量中只有一个值为1, 其他都是0。每增加一种颜色,都要增加向量的长度。所以不容易扩展而且不好判断颜色之间的关系。
分布式表示:用RGB值来表示,三维的向量,维度低,值不同,表示不同的颜色。
嵌入:将从高维度的局部表示转换到低纬度的分布式表示过程。
1.3.2 表示学习
高层次的语义表示一般为分布式表示,例如RGB三个值表示颜色。通常需要从底层特征开始,经过多步非线性转换才能得到。
1.4 深度学习
为了学习到好的表示,需要构建一定深度的模型,通过学习算法让模型自动学习出好的特征表示(从底层特征,到中层特征,到高层特征),把原始数据变成让更高层次,更抽象的表示。从而提升预测模型的准确性,通用性。深度就是非线性特征的转换次数。深度学习就是从数据中学到有效的特征表示。也可以看作是从输入节点到输出节点所经过的最长路径的长度。深度学习需要解决是的贡献度分配问题,即一个系统中不同的组件或参数对最终系统输出结果的贡献或影响。通过误差反向传播,不断的强化模型,从而比较好的解决贡献度分配问题。

浅层学习
不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。

1.4.1 端到端学习
复杂的任务需要分割成多个子模块,例如语言理解,词性理解,语义分析等多个步骤。分块学习会造成每个模块单独优化,误差对下一个模块的学习影响很大,端到端学习是指不进行分块训练,直接优化任务的总目标,中间过程不需要人为的干预。
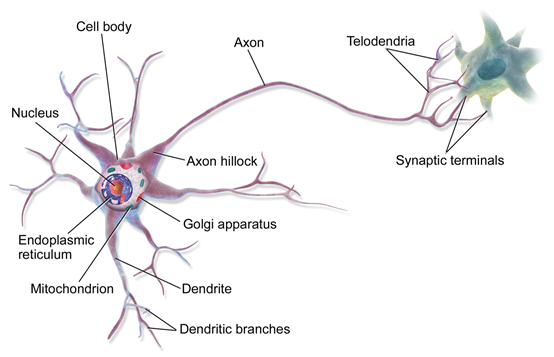
1.5 神经网络
神经网络是模拟神经元结构而构造的数学模型,神经元由轴突和树突组成,轴突的信号传递到树突,如果树突接收到的信号总和超过阈值,则细胞会兴奋,产生电脉冲,传递给其他神经元。神经网络模拟神经元的结构、机理,、功能。由多个节点连接而成,节点之间的连接被赋予了不同的权重,权重代表影响大小,每个节点代表一个函数,其他节点的信息仅供权重计算之后,输入到激活函数,得到新的值,传递给下一个节点。
1.6 常用的深度学习框架
深度学习框架具有的特性
(1)简易和快速的原型设计
(2)自动梯度计算
(3)无缝CPU和GPU切换
