如果不希望文件被切分,例如判断文件中记录是否有序,可以让minimumSize值大于最大文件的大小,但是文件的大小不能超过blockSize,或者重写FileInputFormat方法isSplitable()返回为false。下面介绍将多个小文件合成一个大的序列文件的例子:
1)自定义完整文件输入处理类如下:
Public class WholeFileInputFormat extends FileInputFormat<NullWritable, ByteWritable>
{
@override//不得分片
protected boolean isSplitable(JobContext context,Path file){return false;}
@override
public RecordReader<NullWritable,BytesWritable> createRecordReader ( InputSplit split,TaskAttemptContext context )throws IOException,InterruptedException
{
WholeFileRecordReader reader=new WholeFileRecordReader();
reader.initialize(split,context);
return reader;
}
}
2)自定义完整文件读取类WholeFileRecordReader:
WholeFileRecordReader类通过initialize()方法传入文件信息,然后调用nextKeyValue()方法一次性读取整个文件的内容,通过布尔值processed判断是否读取执行过。其他函数都是返回值。将FileSplit转为一条记录,键为null,值为文件内容。
package org.edu.bupt.xiaoye.hadooptest;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* 继承RecordReader
* 该类用来将分片分割成记录,从而生成key和value。例如TextInputFormat中的key和value就是RecordReader的子类产生的。
* 在这里,我们继承了这个类,将重写了key和value的生成算法。对一个分片来说,只生成一个key-value对。其中key为空,value为该分片
* 的所有内容
* @author Xiaoye
*/
public class WholeFileRecordReader extends
RecordReader<NullWritable, BytesWritable> {
// 用来盛放传递过来的分片
private FileSplit fileSplit;
private Configuration conf;
//将作为key-value中的value值返回
private BytesWritable value = new BytesWritable();
// 因为只生成一条记录,所以只需要调用一次。因此第一次调用过后将processed赋值为true,从而结束key和value的生成
private boolean processed = false;
/**
* 设置RecordReader的分片和配置对象。
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
this.fileSplit = (FileSplit) split;
this.conf = context.getConfiguration();
}
/**
* 核心算法
* 用来产生key-value值
* 一次读取整个文件内容注入value对象
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed) {
/*
* 注意这儿,fileSplit中只是存放着待处理内容的位置 大小等信息,并没有实际的内容
* 因此这里会通过fileSplit找到待处理文件,然后再读入内容到value中
*/
byte[] contents = new byte[(int) fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null;
try {
in = fs.open(file);
IOUtils.readFully(in, contents, 0, contents.length);
value.set(contents, 0, contents.length);
} finally {
IOUtils.closeStream(in);
}
processed = true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException,
InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException,
InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() throws IOException {
//do nothing
}
3)将若干个小文件打包成顺序文件的mapreduce作业
通过WholeFileRecordReader类读取所有小文件的内容,以文件名称为输出键,以内容未一条记录,然后合并成一个大的顺序文件。
public class SmallFilesToSequenceFileConverter extends configured implement Tool
{
package com.pzoom.mr.sequence;
import java.io.IOException;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
public class SmallFilesToSequenceFileConverter {
///定义map函数
static class SequenceFileMapper extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> {
private Text filenameKey;
//定义设置文件函数
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit)split).getPath();
filenameKey = new Text(path.toString());
}
//定义map函数
@Override
protected void map(NullWritable key, BytesWritable value,
Context context) throws IOException, InterruptedException {
context.write(filenameKey, value);
}
//定义run函数
@Override
public int run (String[] args)throws IOException {
Configuration conf = getConf();
if(conf==null)
{
return -1;
}
Job job=JobBuilder.parseInputAndOutput(this,conf,args);
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);输出序列file
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
return job.waitForCompletion(true)? 0:1;}
//args传入输入输出路径
public static void main(String[] args) throws IOException{
int exitCode=ToolRunner.run(new SmallFilesToSequenceFileConverter(),args);
System.exit(exitCode);
}
}
}
4)执行小文件合并为大文件的命令
各参数含义:采用本地配置文件,两个reduces任务,输入文件夹,输出文件夹
%hadoop jar job.jar SmallFilesToSequenceFileConverter –conf conf/Hadoop-localhost.xml –D mapreduece.job.reduces-2 input/smallfiles output
5)通过命令来查看输出结果
%hadoop fs –conf conf/Hadoop-localhost.xml –text output/part-r-00000
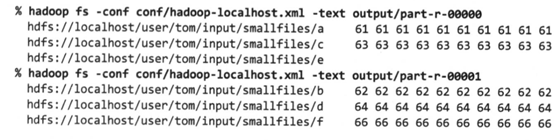
输出结果是以小文件路径为键,以内容为值的合并序列文件
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: