title: 面试简略复习
tags: 面试 复习
renderNumberedHeading: true
grammar_cjkRuby: true
slug: 面试简略复习
需求-产品-研发-测试-运维 流程
你们需求的开发流程是什么样的

1. 需求提出:产品或者客户提出,UI,前后端开发,测试评估业务意义,成本等。
2. 需求PRD:产品根据需求列出需求的细节,流程歧义等定义边界。并配有原型图,文字说明,主要是,需求,需求目标,业务逻辑,参与敲定版本的还是上述那些人。
3. 交互设计:UI根据PRD设计出效果图,一般变动不大,如果大说明需求PRD没有设计好。
4. 概要设计和详细设计:小需求改动可能直接详细设计或者确认-改动-发布完成即可。
1. 技术是把双刃剑,你用了技术之后你是不是需要列出他的优点缺点,出问题之后的解决方案,还有可能出现的问题,注意点等等。
2. 你需要考虑这个需求涉及到哪些服务了,需要新增哪些接口(功能列表),修改哪些接口,表有现场的还是要新建表,字段要新建么?
mysql
- mysql 字符utf8mb4 支持emoji
- mysql分两类索引算法Hash和B+树;B+树的情况下用于两种引擎MyISAM和InnoDB的区别:前者是非聚簇索引(索引数据是记录的地址),后者是聚簇索引(索引数据就是记录本身,其中主索引是key(主键),辅助索引是记录的其他数据,如果要查其他数据就要先查主键索引再查辅助索引走两遍索引)
- 事务:原子性,一致性,隔离性,持久性
- MyISAM是表级锁,InnoDb是行级锁
redis
- value的5中数据结构:string,list,set,sorted set,hash、
- 线程:单线程,异步,多路复用实现高性能(多连接(网络io socket,io),复用一个线程,IO持久化无法复用通过COW(copy on write)创建一个共享内存的进程(子进程)进行io操作)
- 持久化:AOF更新频率高优先使用,RDB性能好
- redis锁:是把指令合并成一行做一个指令处理形成原子操作。
- 常见缓存场景问题:
- 缓存穿透:非热点数据,无效请求查询类DB,解决业务层增加身份校验和无效请求过滤。
- 缓存击穿:某个key再高并发的时候正好过期,解决增加线程锁机制
- 缓存雪崩:多个key同时过期(过期时间打散,分发key到多个master)
- 缓存降级:一般是突然访问上升缓存存储不够,为了保证服务可用,对不重要的数据不进行缓存,比如收货地址可以用缓存默认地址不查询DB全部缓存。
- 缓存预热:一般是不确定哪些数据是热点数据时进行预热处理,哪些数据达到阈值就对哪些数据缓存。
springcloud
- CAP:zk是CP,eureka是AP
- 5大组件:
- Hystrix 断路器防止级联故障
- eureka 服务注册与发现
- Ribbon 负载均衡
- zuul 网关 路由规则
- Feign 代码注解基于http访问而不是rpc的协议规范对接口进行暴露(一般整合Ribbon和Hystrix)
2大核心: - cloud bus 消息总线 节点消息管理
- 链路追踪Sleuth:服务节点,连读id,链路的某一环节的id,是否输出监控信息展示
Flume
- source 实现EventRead,AbstractSource ,Configuration,eventSource接口
- channel
- sink
- intercepter 拦截器:host,regex
- precessor: channelSelector,sinkPrecessor-default,failover,load_balance
ZK
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态
- 如果是looking状态,不存在其他节点投自己存在其他节点且没有leader的时候找sid最大的节点投票;
- 这个过程中如果没有节点票数超过半数,大家保持Looking状态。
- 若果超过半数,最大票数(一般活着的节点默认sid最大的那台)成为leader,其他改为following状态。
- 如果已经存在leader就投自己一票然后自己状态改为following状态。
HDFS
hdfs HA机制,一台namenode宕机了,joualnode,namenode,edit.log fsimage的变化
-
jounalnode
HA是为了解决单点问题,通过JN集群共享状态,通过ZKFC 选举active,监控状态,自动备援。
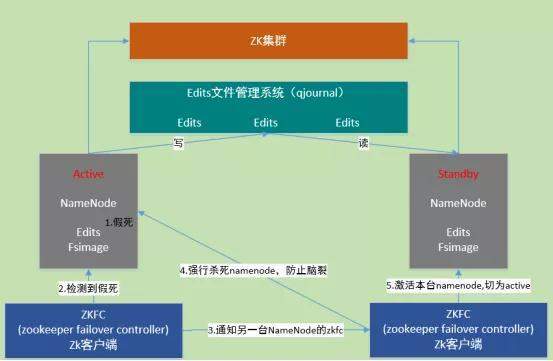
Active Namenode将数据写入共享文件管理系统,而StandbyNamenode监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致。如此,在紧急情况下standby便可快速切为active namenode。- 自动故障转移机制:
-
active Namenode宕机(假死)。
-
active Namenode zkfc检测到假死
-
通知另一台namenode的zkfc
-
另一台机机器强行杀死之前的active namenode
-
激活standby namenode,切为active状态
-
- 自动故障转移机制:
namenode,edit,fsimage
- Namenode滚动当前正在写的edit文件,该文件为待合并状态,也会生成新的edits.inprogress文件,后续的修改日志将写入该文件中
- namenode将fsimage文件和edits文件加载到内存进行合并。dump成新的fsimage文件fsimage.chkpoint。
- namenode将fsimage.chkpoint重命名为fsimage
MR
Map
inputformat.readline->XMapper.context.write->ouputCollector-序列化->环形缓冲区-spillerThread.spill溢出->1.Partition分区,ComposeTo排序-Combiner->Merger.merge()-Combiner->Disk
Reduce
Fetcher.fetch()->Merger.merge()-Iterator.hasnext()-GropingComparetor.CompareTo()->XReducer.iterator.next()->context.write()->outputFormat.writeLine

HIVE
如何判断一个模型的好坏
- 算法模型
我们会用不同的度量去评估我们的模型,而度量的选择,完全取决于模型的类型和模型以后要做的事;一般基于方差,基尼系数等可以对算法进行评估的数学模型。 - 数仓模型
- 模型完整度:des,ads,dm层直接饮用ods的比例太大就是跨层引用率过高就不是最优
- **复用率:dw,dws层产出的表的数量 **
- 规范度
- 数据可回滚,重跑数据结果不变
- 核心模型和扩展模型分离
维度建模四步骤
业务流程-定义粒度-确定维度-确定事实
事实表:一般是是具有度量(数值型数据)
分三类可加性,半可加性(部分维度粒度下可加)如价格,不可加性如订单状态
数据分层概念
数据倾斜解决
- GroupBy造成的倾斜:set hive.map.aggr=true #开启局部聚合;set hive.groupby.skewindata=true;#开启对map的输出结果进行打散操作。
- count(distinct)进行去重统计优化:改写成先分组groupby再count,利用上着的打散特性。
- 小表join大表(1G数据存储大小的边界区分):使用默认开启的mapjoin,复制小表制定列在map阶段进行join计算。从而不需要分发数据就没有数据倾斜。
- 倾斜的值是明确而且数量很少(比如null值):解决方案使用case when对这些值匹配的字段key进行concat随机数进行打散。
- **动态分治思想+映射关系:把倾斜的键值和不倾斜的键值分开处理,不倾斜的正常处理即可,倾斜的做mapjoin,然后union all结果即可。
hive的优化
- 行列过滤,代码优化
- 列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *
- 行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,这样效率低,可以直接先子查询后再关联。(这个非常有用,实际开发中大数据处理效率会高很多,善用子查询关联);但是这种对左外关联和右外关联有时候就不一定适用了。尤其表中有null值的时候就不适合使用了,使用时要注意。
- 开启JVM重用
- CombineHiveInputFormat具有对小文件进行合并
- hive.exec.parallel值为true开启并行执行
- Fetch抓取: Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算;hive-default.xml.template文件中hive.fetch.task.conversion默认是more,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
拉链表的逻辑及回滚处理
维度表:是事实表的分析角度也是查询约束条件,维度的细节级别就是事实表的粒度
各个维度粒度组合决定事实表的粒度,从而形成单行记录的说明
粒度下的一个度量可加计算就是统计分析。
主题
一般根据业务线划分
主题域一般按照业务关联的实体划分
缓慢变化维处理
1. 什么也不该,保留原始值
2. 直接覆盖
3. 增加新行,需要为新航分配新的代理键
4. 增加新属性列
5. 增加微型维度(某些维度属性变化较快导致维度表越来越大可以把这些属性柴丽出来单独构建微型维度表)
6. 双重外键并且方式1与方式2结合
在方式2的基础上,不仅是维度的代理键作为事实表外键,维度的自然键(如果自然键会被重新分配,发生变化,应该使用持续性超自然键)也同时作为事实表外键。
事实表通过代理键连接维表获取历史维度属性,通过自然键连接维表获取当前维度属性
为表指定键的策略有两种:
- 自然键。自然键是已经存在的一个或多个属性,它在业务概念中是唯一的。对于表Customer来说,存在两个候选键,CustomerNumber与SocialSecurityNumber。
代理键。
- 引入一个不具有业务含义的列作为键,称作代理键。例如图1中表Address的列AddressID。地址不具有一个“简单”的自然键,因为需要使用Address表的所有列组成一个键(取决于你的问题域,可能仅仅需要组合Street和ZipCode列),所以此时引入一个代理键是一个更好的选择
交叉维度处理
桥接表可以捕获多对多关系,并且由于源系统中的关系是已知的.桥接表可以解决掉维度之间的多对多关系,也解决掉的维度表的多值维度问题。
多值维度: 当事实表的一行涉及到维度表的多行时就产生多值维度,同样当维度表的一行需要获取单一属性的多个值时也会产生多值维度。交叉维度是多值维度的一个特例是维度之间的多对多关系;多值维度是事实表和维度表的多对多关系。
多值维度的解决方案:
1. 扁平化多值维度,比如一个账户可以三个人拥有,可以引入三个账户拥有人列。
2. 可以用桥接表:即中间表,维护比较麻烦,计算易出错。
3NF(3范式概念)
一范式让表的列不可分割
二范式让表的列不部分依赖主键
三范式让列之间不存在传递依赖
Hive执行计划Explain
三部分:语句的语法树,语句的stage依赖关系(代表shuffle),每个stage的详细介绍(列出每个sql关键字操作的列)
驱动器有四部分:解析器(解析成AST语法树),编译器(编译成逻辑执行计划),优化器(执行计划优化),执行器(逻辑计划变物理计划MR或者Spark)
Yarn流程
- Job.submit(rm)-response(jobid,hdfsPath)
- 扫描HDFS文件切片ArrayList(splits)
- 上传job.xml,job.splits,job.jar到hdfs
- req->RM告知上传job信息完毕
- RM把job放入JOB队列
- NMX领取任务->下载job.xml,job.jar等->创建AppMaster容器
- AppMaster请求RM分配NMX,Y Task容器把task放到队列->Task容器领取task任务
- 发送shell命令启动task计算
- 返回task执行的进度等信息给AppMaster
- AppMaster向RM申请销毁自己。

Akka

Kafka
1.原理
存储机制

副本选举机制

分区及副本关系

Spark
界定
- 原理
- 在%或者:前加<>表示上下界
- 视图界定T%V 要求必须存在一个从T到V的隐式转换。
- 上下文界定的形式为T:M, 其中M是另一个泛型类,它要求必须存在一个类型为M[T]的“隐形值”
例如 class Pair[T: Ordering]隐式值
上述定义要求必须存在一个类型为Ordering[T]的隐式值。 该隐式值可以被用在该类的方法中
当你声明一个使用隐式值的方法时,需要添加一个"隐式参数"
def smaller(implicit ord: Ordering[T])隐士参数
视图界定[T%Ordered[T]]<=>隐士函数即具有转换类型关系的方法def或者函数 (科里化里:函数做参被使用(implicit ord:T=>Ordered[T]))
上下文界定[T:Ordering]<=>隐士值即具有继承实现关系的对象实例可以通过关系进行转换类型 (科里化里:值作参数被使用(implicit ord:Ordering[T]))

sparkonYarn
onYarn把driver和client分开;client模式把ExecutorLanucher和driver分开.


1:N或者N:1都是宽依赖,只有1:1窄依赖.


源码
- 源码解析


Flink
watermark与时间语义的关系
- watermark是特殊的时间戳标记记录数据可以认为插入到正常日志记录的特殊事件记录。事件有时间语义
- 时间语义:EventTime,IngestionTime,processingTime分别是日志的三个时间节点创建时间,进入flink时间,执行计算的服务器节点时间
- 采取这三类特殊的时间作为waterMark数据把系统处理数据的水位线(watermark)与日志时间关联起来达到对数据处理的偏移量定位的能力,因此与时间戳有关,watermark必须单调递增。
watermark与窗口关系
-
Watermark是一种衡量eventtime进展的机制,而正确的处理乱序事件,通常用Watermark机制结合window来实现
-
数据流中的watermark用于表示timestamp小于waterMark的数据都已经到达了,因此,window的执行也是由watermark触发的
-
watermark用来让程序自己平衡延迟和结果正确性。
-
周期性生成watermark默认process语义是0ms,event语义是200ms
3s,15s,1m三个参数的作用?
val assignTimeWatermark = dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(3)) {//watermark3秒延迟
override def extractTimestamp(t: SensorReading): Long = t.timestamp * 1000L
})
//...
.timeWindow(Time.seconds(15))//设置窗口
.allowedLateness(Time.minutes(1))//设置延迟时间
15s:是时间窗口大小:如何判断根据日志eventTime判断日志属于哪个窗口里的数据被处理
3s:窗口触发关闭条件watermark>=窗口结束时间;watermark条件满足即过来的日志数据时间>=watermark+3s
1m: allowedLateness窗口等待1分钟:这个才是真正意义上的数据迟到处理输出=>来一条处理一条
(已经关闭还要再等待)没有关闭时到watermark关闭进行输出等待1分钟时来一条就基于之前的结果比较输出一次。
watermark-数据统计结果-状态
两类延迟时间:三类数据
- 一类延迟是窗口关闭的出发条件:(一类数据)过来的日志事件流时间需要大于等于watermark时间多少=》造成结果是计算发生并输出计算结果。
- 另类延迟是窗口关闭后对后续过来的数据依旧有在该窗口内的日志事件处理(二类数据),推测会借助flink-cep状态窗口记录窗口关闭时的结果,重新累计新来的数据得出新的结果。会导致:xx时间累计用户20W结果重新刷新结果xx时间累计200005这种结果跳变。
- 三类数据经过以上方式都没有在约定的两类时间内过来的数据,窗口输出彻底关闭后迟到的数据,一般输出到测输出流。
状态和ProcessFunction
当定时器timer触发时,会执行回调函数onTimer(),注意定时器timer智能在keyedStreams上面使用。
实现processFunc一般需要三点:
- process处理逻辑
- 状态:记录中间数据
- onTimer触发器方法
计算公式:两类时间都是跟watermark比较的
watermark=maxtimestamp-maxOutOfOrderness(3s)
1min=watermark-windowStartTimestampOfCurrenttimestamp
watermark-时间语义-barrier-checkpoint关系
算法的barrir传递策略(!各个子任务,分区的barrir对齐)




barrier有一个到达该 task就要做保存checkpoint操作;后面的数据进行缓存(这个过程叫暂停算子的该task)其他算子正常运行。
sum even,sum odd完成保存后通知jobmanager保存完成


同上流程sink完成checkpoint后通知jobmanager

总结:checkpoint是完全完成是指程序的source,tranform,sink各个阶段的各个算子的各个task的各个分区数据都完成barrier在各自的阶段算子及task和分区一致的情况下保持一致=>并完成checkpoin存储。
watermark-barrier(ck)-2FC两段提交
- 两阶段提交(Two-Phase-Commit,2PC) 幂等写入和预写日志事务都不完美,这个两阶段完美。
- 对于每个checkpoint,sink任务会启动一个事务,并将接下来所有接收的数据添加到事务里
- 然后将这些数据写入外部sink系统,但不提交他们--这时只是“预提交”
- 当它收到checkpoint完成的通知时,它才正式提交事务,实现结果的真正写入
- 这种方式真正实现了exactly-once,它需要一个提供事务支持的外部sink系统。Flink提供了TwoPhaseCommitSinkFunction接口(如kafka sink连接器就是实现这个接口)
有可能sink的状态保存比window的状态保存快花费时间少,所以sink保存完成并不是checkpoint完成。
- sink事务预提交状态,数据都保存在事务中=》当前事务还不能关闭,会开启下一个事务。

- 所有状态保存完成时(所有阶段的算子及分区的计算状态CK保存完毕)才正式提交事务
- 对kafka另外的要求:3.1下游消费kafka的数据,必须是已确认的数据,如果是sink未确认的数据就可能导致数据闪电回放等数据不一致。3.2 kafka事务关闭外部15分钟flink内部超时时间是1H,导致kafka事务失败,数据没有完成提交,但是flink checkpoint 认为完成了。
ElasticSearch
Hbase
rowkey一般如何设计,你项目中是如何设计的:保证唯一,有序,简短64kb以下
核心数据比如userid和itemid+时间戳+随机hash