转载自:http://www.pythoner.com/238.html 点击打开链接
作者真好!
1.书籍信息
书名:Machine Learning in Action
译名:《机器学习实战》
作者:Peter Harrington
译者:李锐 李鹏 曲亚东 王斌
出版社:人民邮电出版社
ISBN:978-7-115-31795-7
页数:332
2.纸张、印刷与排版
正常的16开本,纸张白色。
字体大小、行段间距正常。代码等特殊模块区分度较高。
3.勘误
本书勘误页(图灵社区):http://www.ituring.com.cn/book/1021
译者勘误页:http://ir.ict.ac.cn/~wangbin/mli-book
个人总结勘误(部分已提交图灵社区):机器学习实战_人民邮电_1版1印_勘误
4.笔记与评价
阅读级别:细读。
推荐级别:细读。
《机器学习实战》一书是图灵6月份出的新书。京东一直处于预定状态,直到6月22号才拿到这本书。本书使用Python语言讲解机器学习的各个算法,和《集体智慧编程》很像,对于代码的讲解非常细致。
本书分为四大部分:第一部分是分类,包括kNN、决策树、朴素贝叶斯、Logistic回归、SVM和AdaBoost;第二部分是利用回归预测数值型数据,包括线性回归、局部加权线性回归、缩减系数、树回归等;第三部分是无监督学习,包括K-means、Apriori、FP-growth等;第四部分是其他工具,包括PCA和SVD两种降维技术,以及MapReduce。本书附录部分包括Python入门(包括Python、NumPy以及一些其他第三方库),线性代数和概率论的简要入门,以及一些数据来源的资源(这里也可以参见《鲜活的数据》一文)。
本书的结构比较清晰,讲解思路也很好,代码、图表、示例都很丰富。不像《Python Algorithm》,《机器学习实战》这本书抛开了繁杂的数学公式和证明,通过大量的示例,以及完整清晰的代码,以程序员更能够理解的方式来讲解这些机器学习的算法。在《Python Algorithm》这样的书中,Python代码甚至看起来不那么重要,写的如同伪代码一般;而在《集体智慧编程》、《机器学习实战》这样的书中,所有的代码都是完整的、可立即执行的,并且附有大量的文字负责讲清楚每一个重要的代码块做了什么、为什么这么做。
由于本书使用的是Python语言讲解,因此大量的使用了NumPy和Matplotlib等Python机器学习中常用的第三方库。这里需要读者对这2个库的一些基本知识有一定熟悉。
需要特别说明的是,本书中对于SVM的讲解要比其他书籍更深入算法,在《集体智慧编程》等书中基本都是直接使用的LIBSVM,而没有自己实现。
本书中作者为函数、变量等的取名使用的都是小驼峰法,不过很多单词使用的都是取前几个字母的缩写形式,看起来会比较容易不知所措,可能需要上下文的代码或文字才能理解。另外,本书作者的代码中对于空格的处理不是很好,看起来并没有什么原则,同样的情况下是否空格却不相同,甚至会出现类似下面这样的语句(P299,L17):
>>>a1=array([1, 2,3])
目测,代码部分译者一般都是直接搬的英文版,并没有做修改,因此这些虽然不影响运行但是看起来不舒服的代码就留了下来。
本书的翻译基本没有原则性的错误,语句也都比较通顺,不过小错误较多(部分错误源自英文版),一般不会影响读者阅读。
对于要研究机器学习的程序员们,这本书很适合入门哦~
5.思维导图
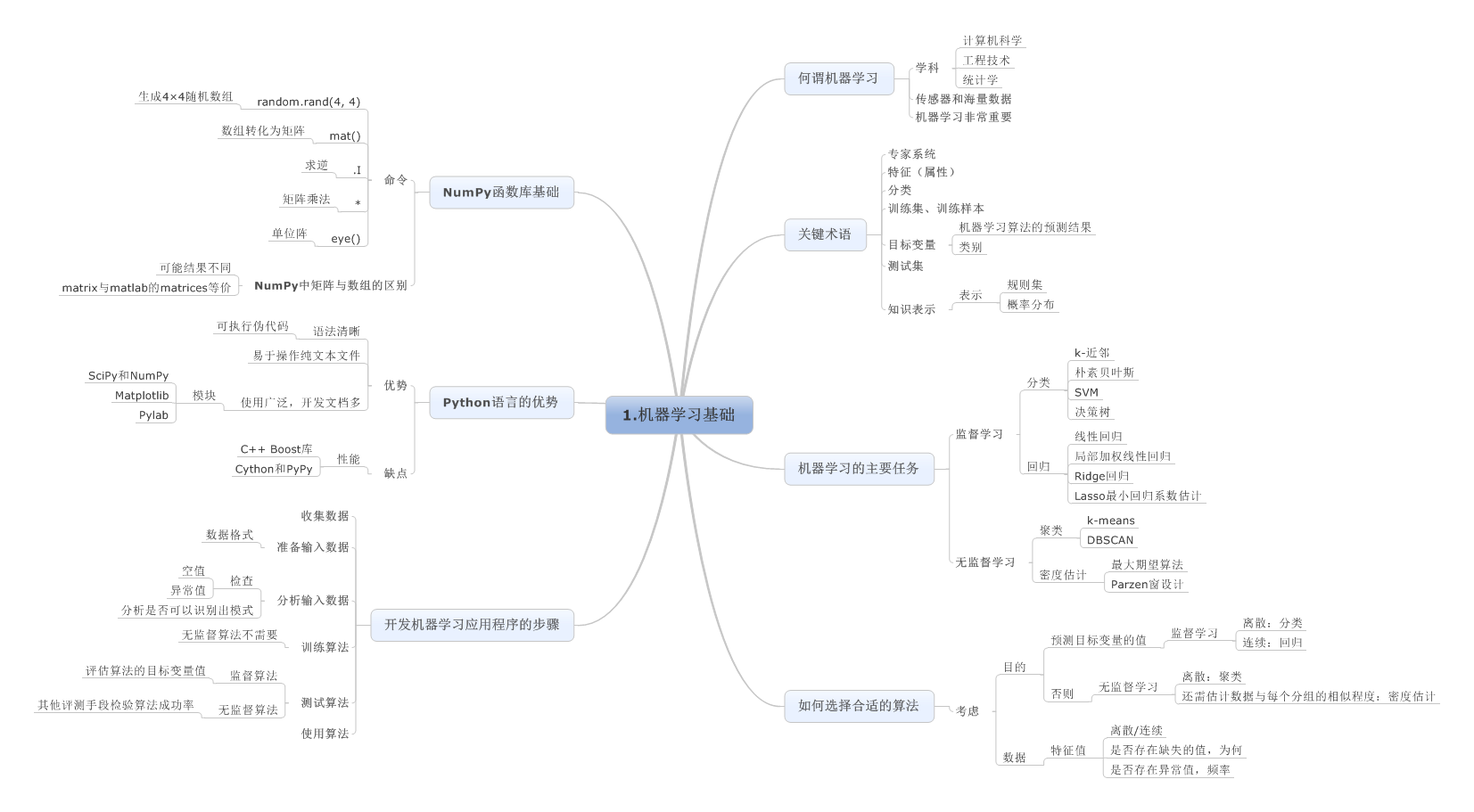
1.机器学习基础
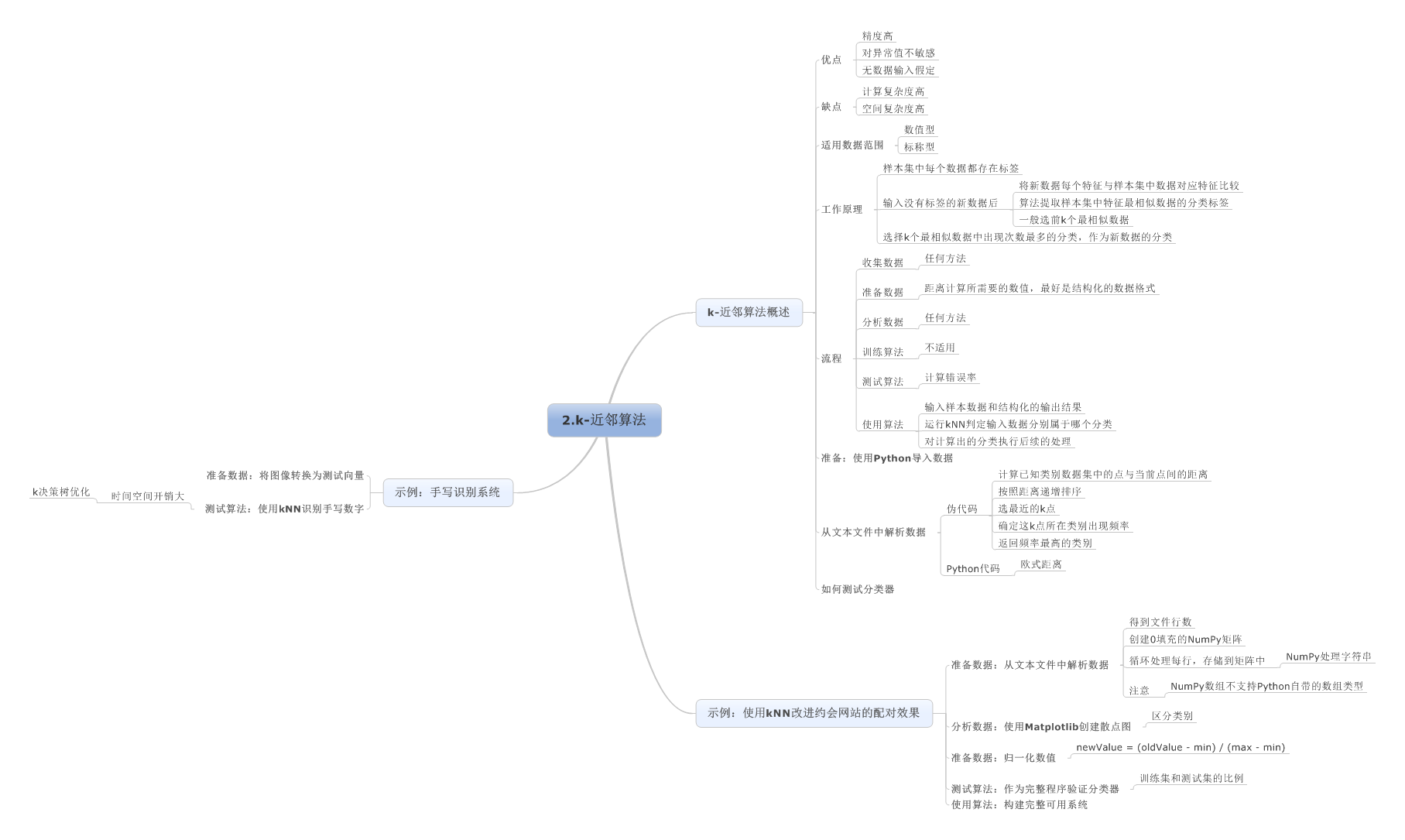
2.k-近邻算法
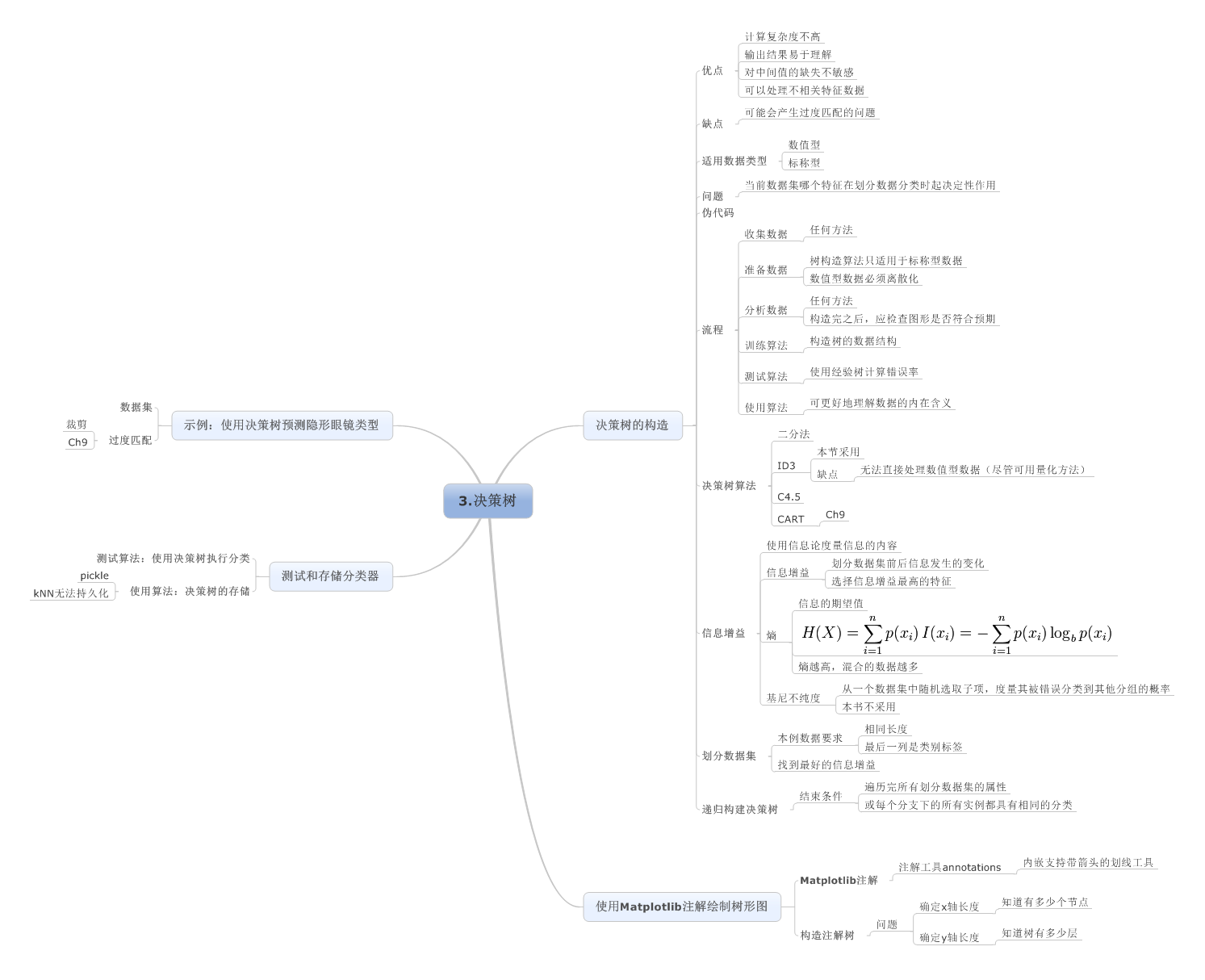
3.决策树
4.基于概率论的分类方法:朴素贝叶斯
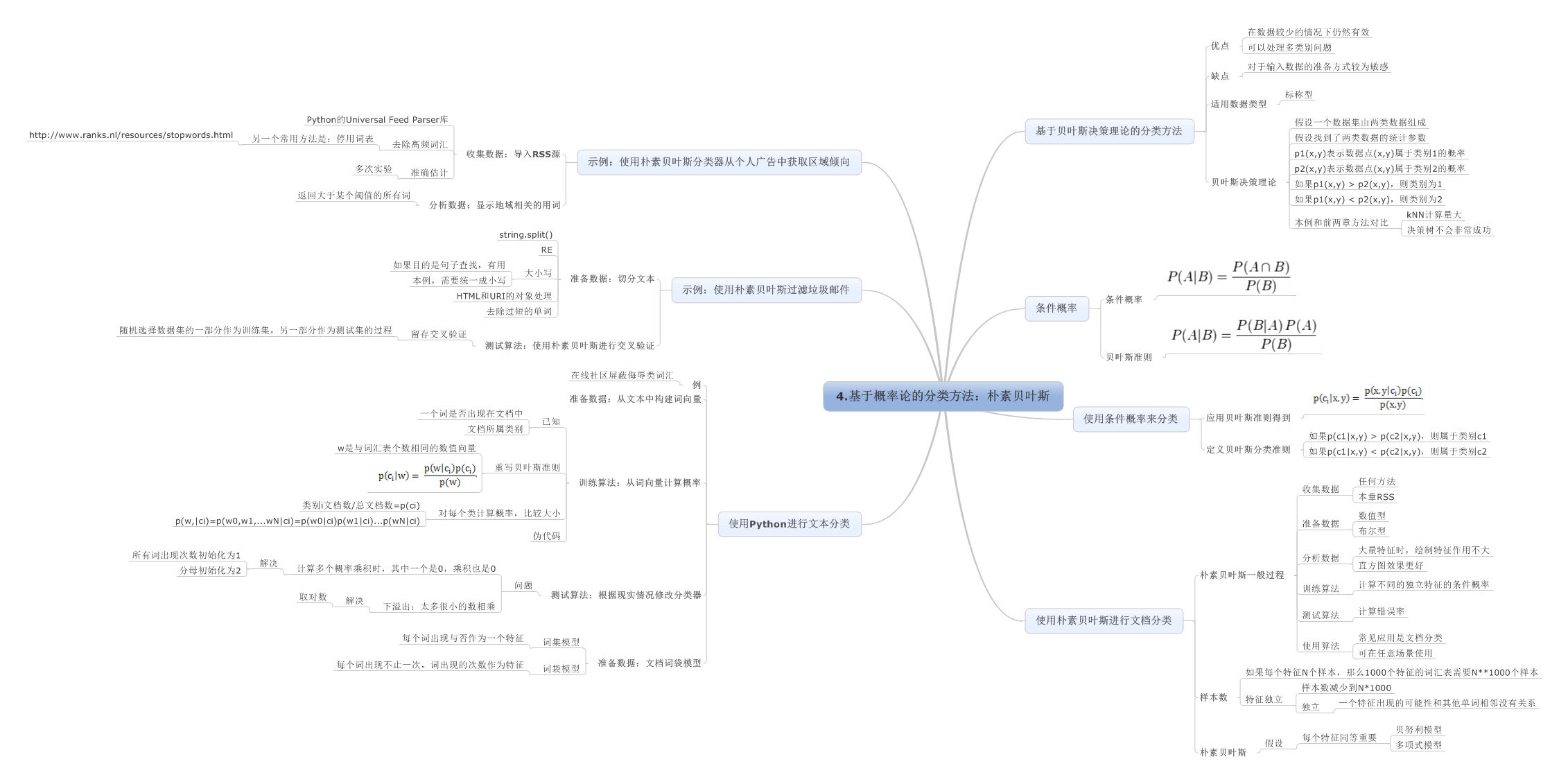
5.Logistic回归
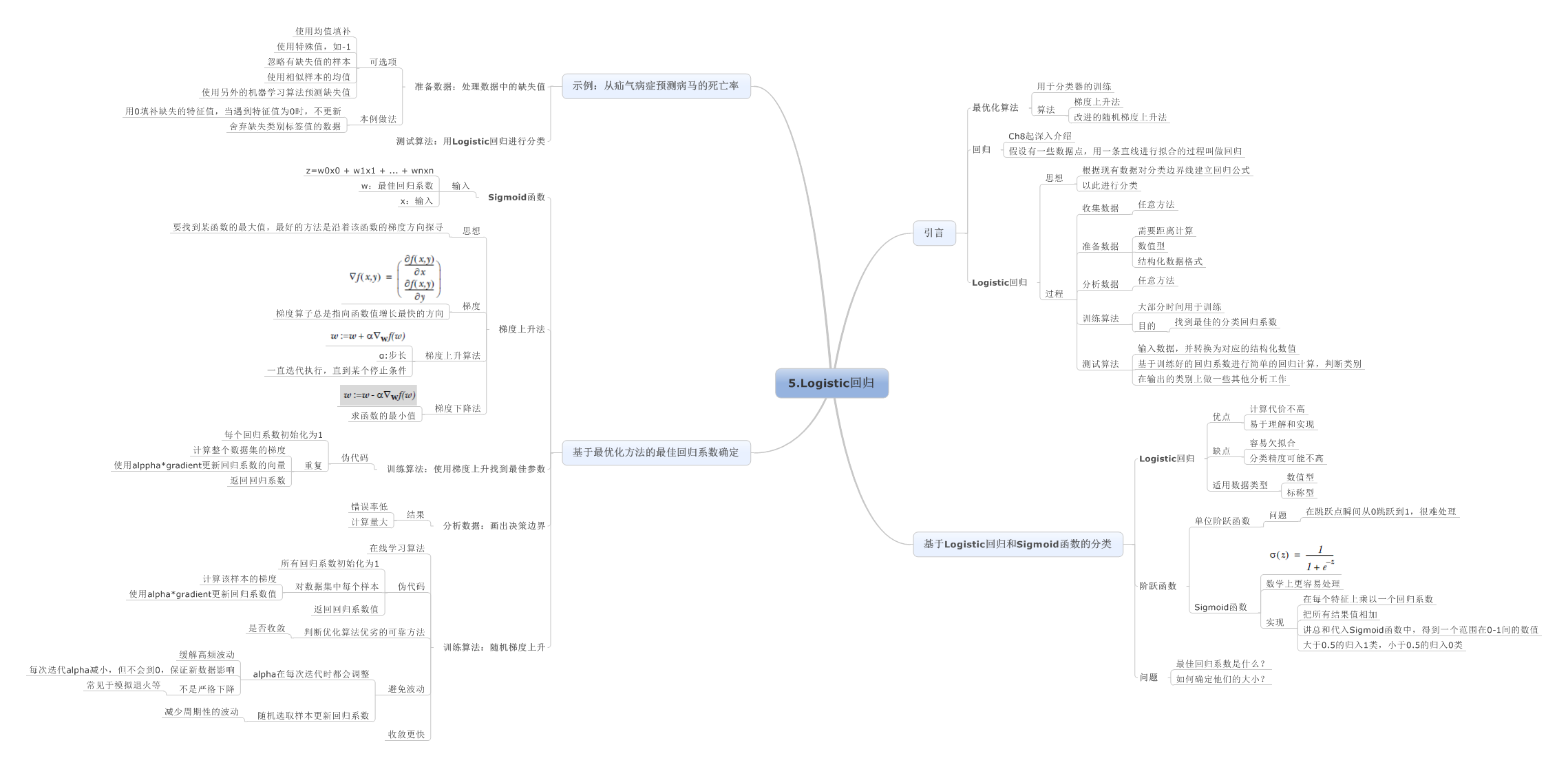
6.支持向量机
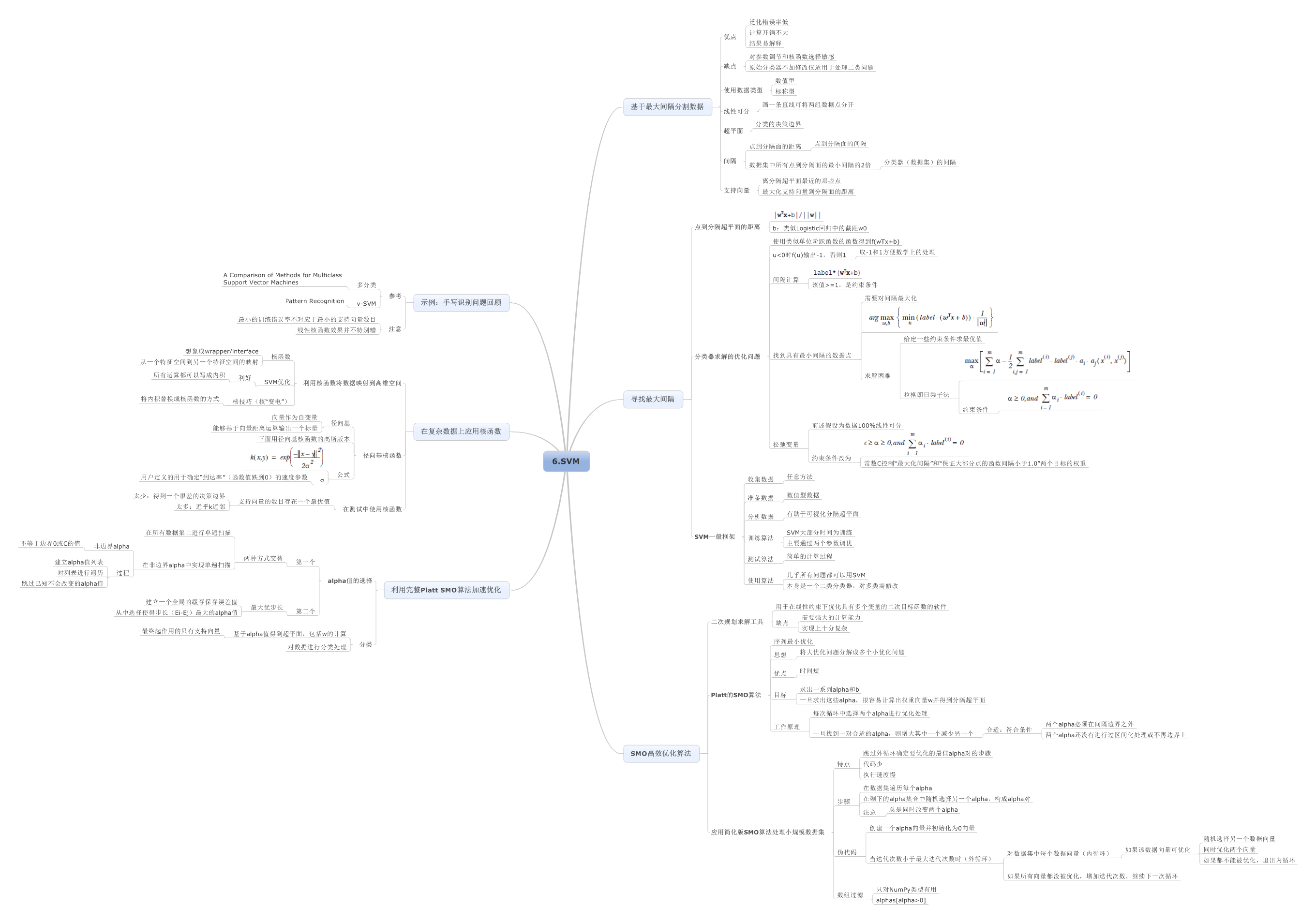
7.利用AdaBoost元算法提高分类性能
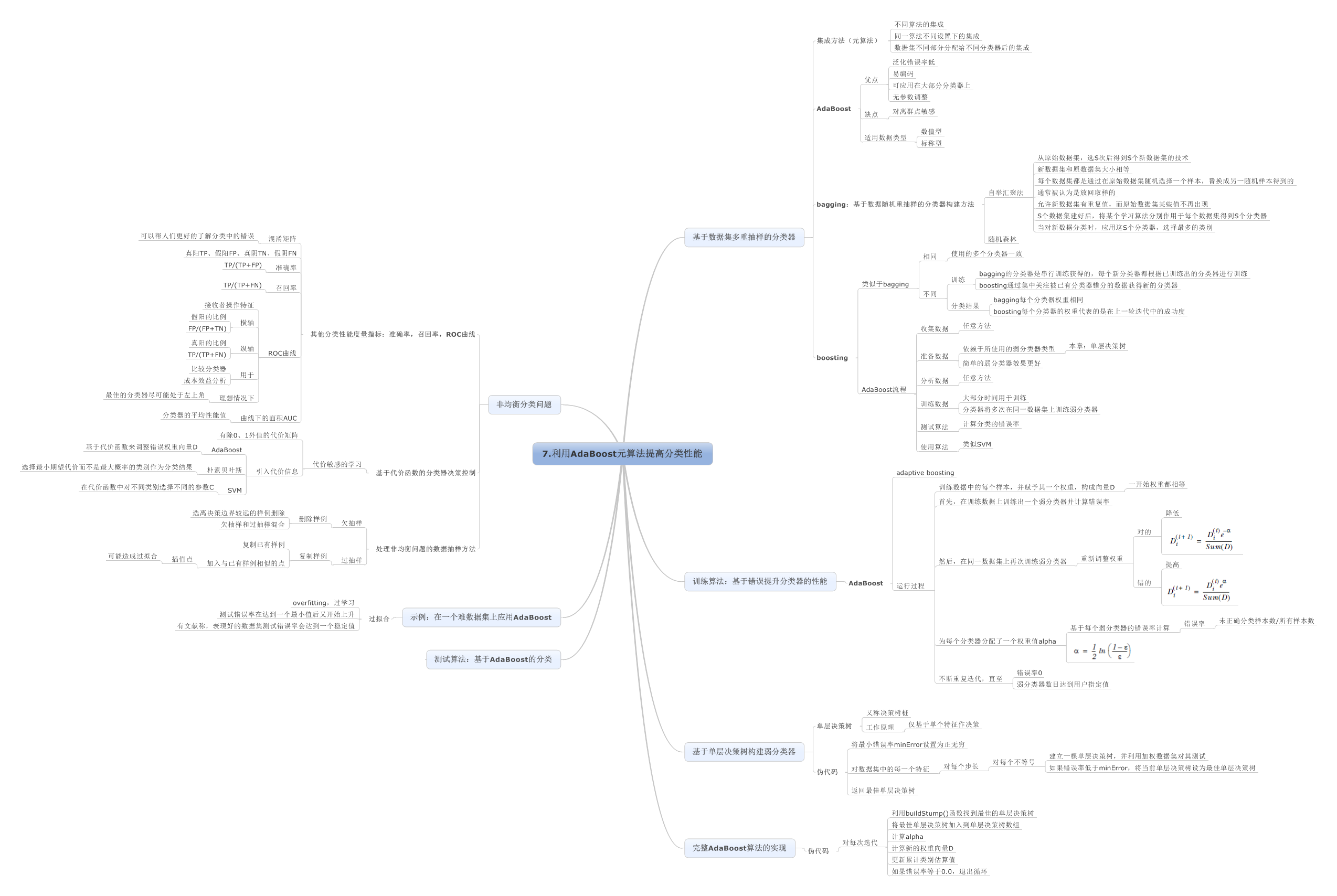
8.预测数值型数据:回归
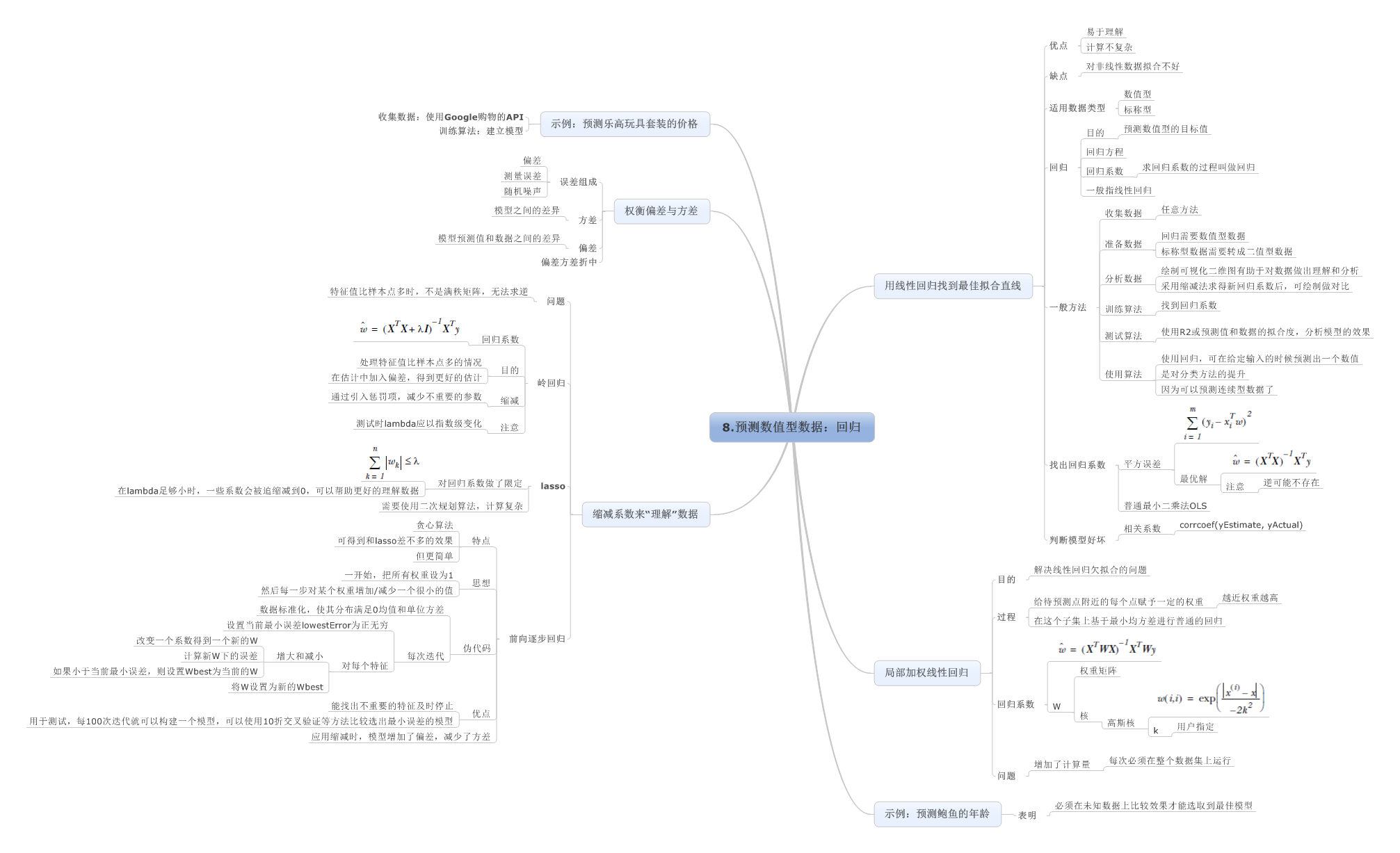
9.树回归
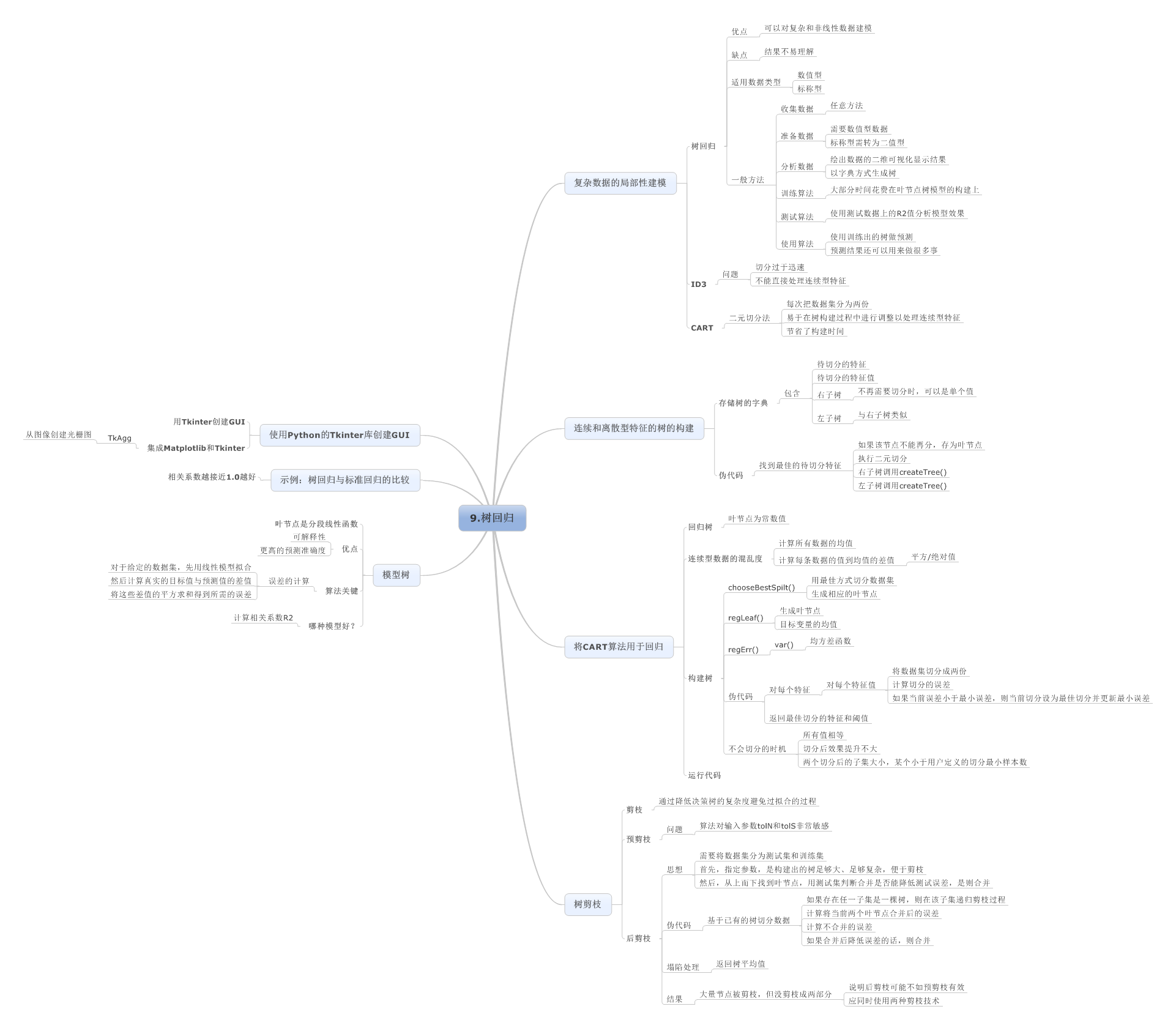
10.利用k-均值聚类算法对未标注数据分组
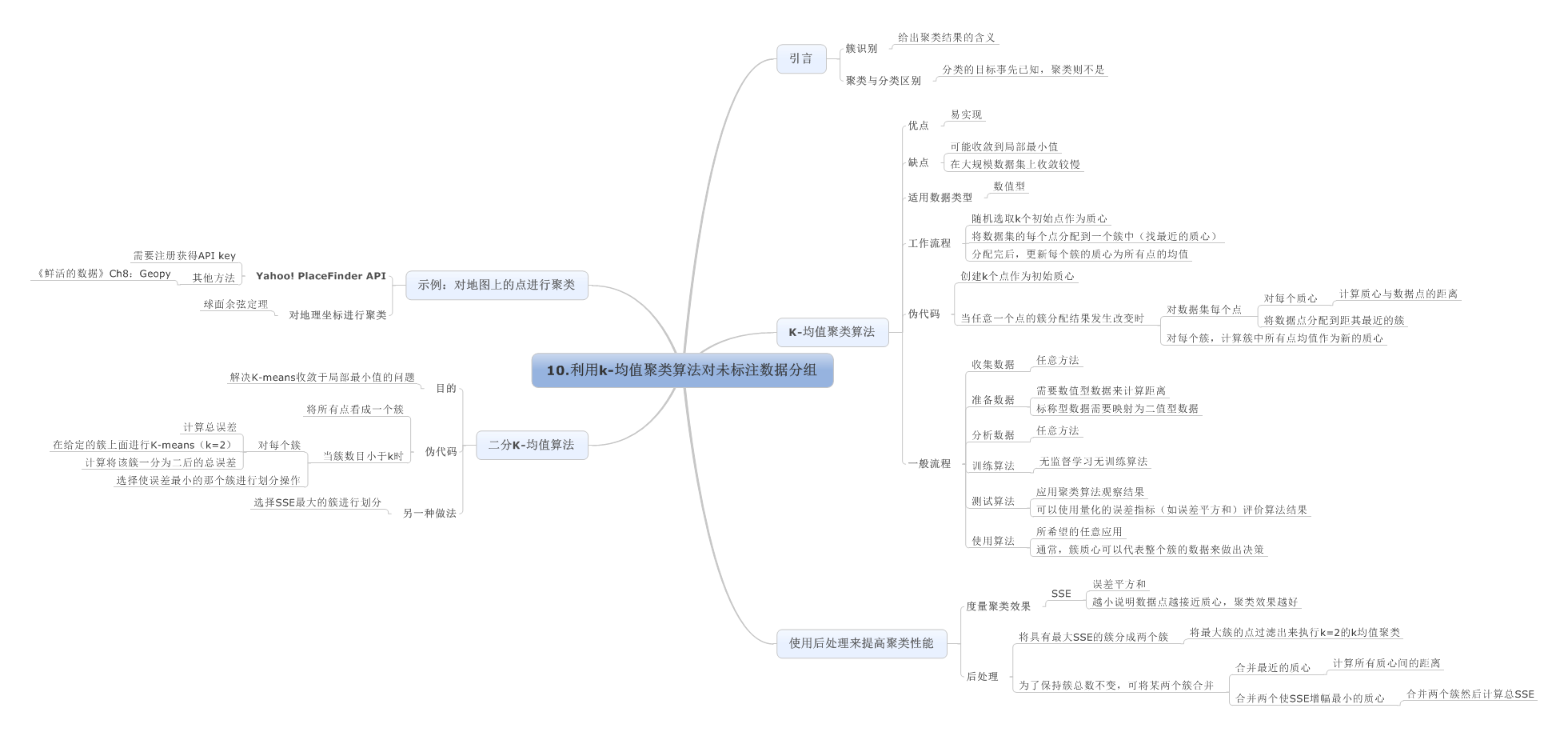
11.使用Apriori算法进行关联分析
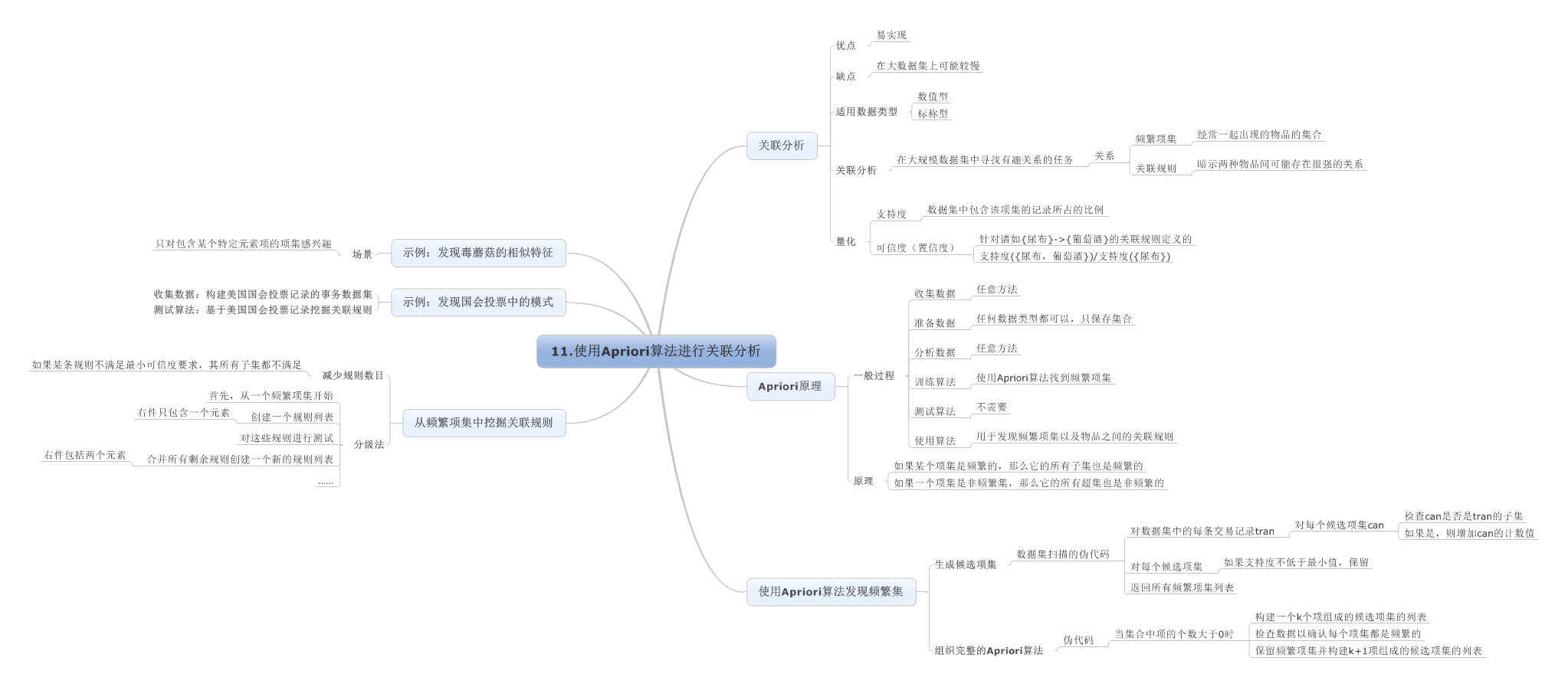
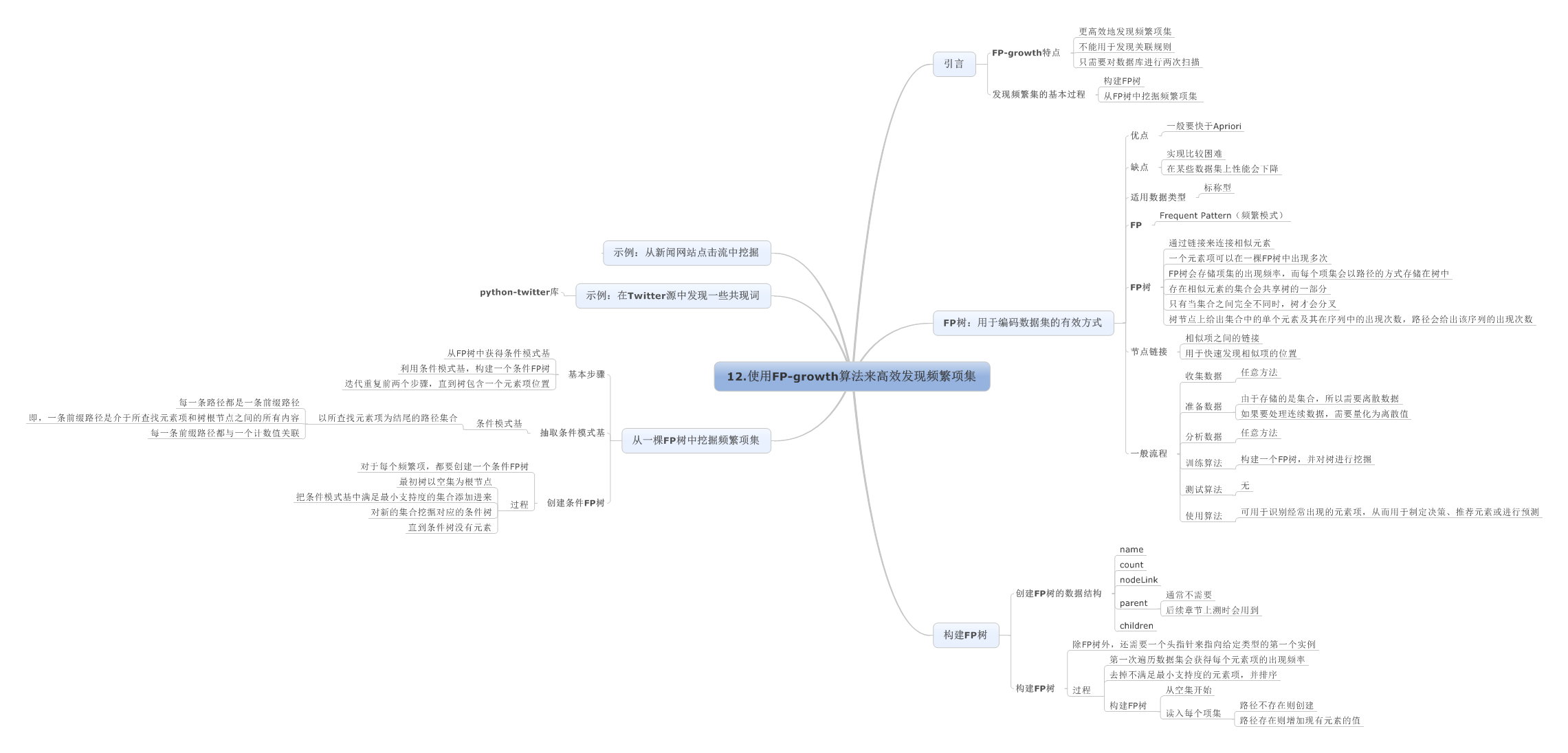
12.使用FP-growth算法来高效发现频繁项集
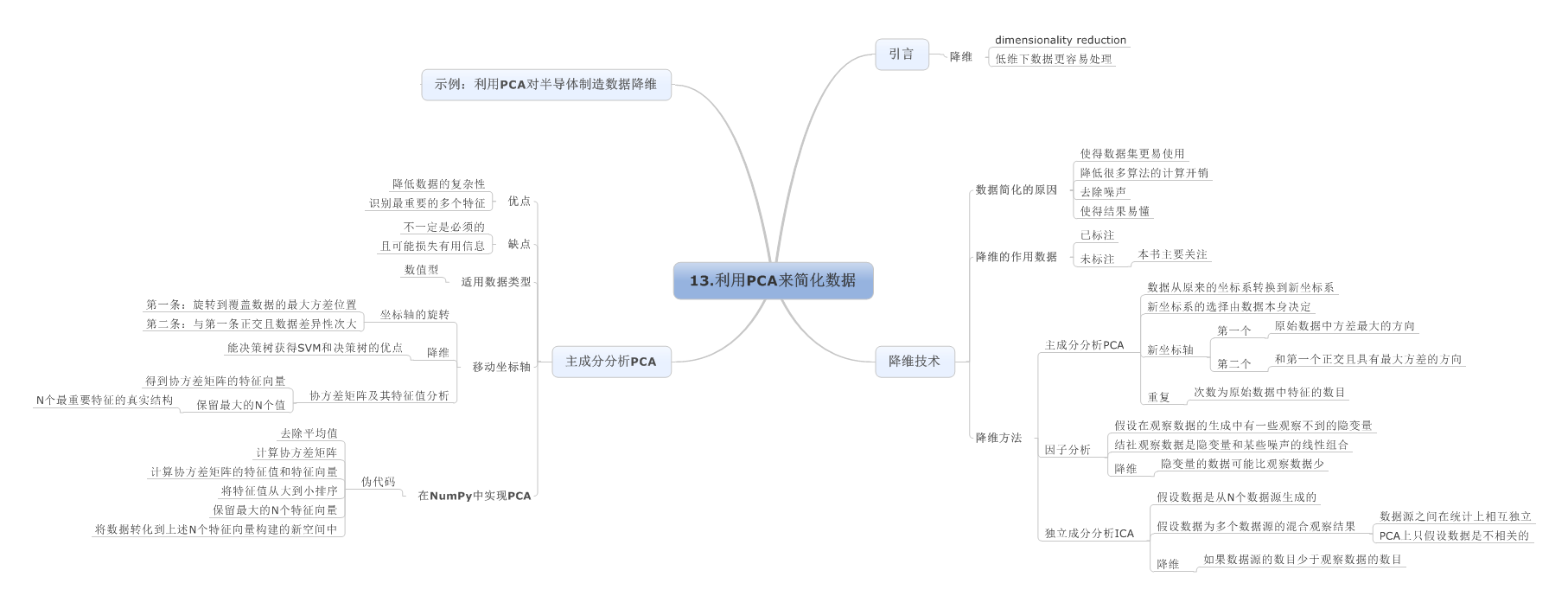
13.利用PCA来简化数据
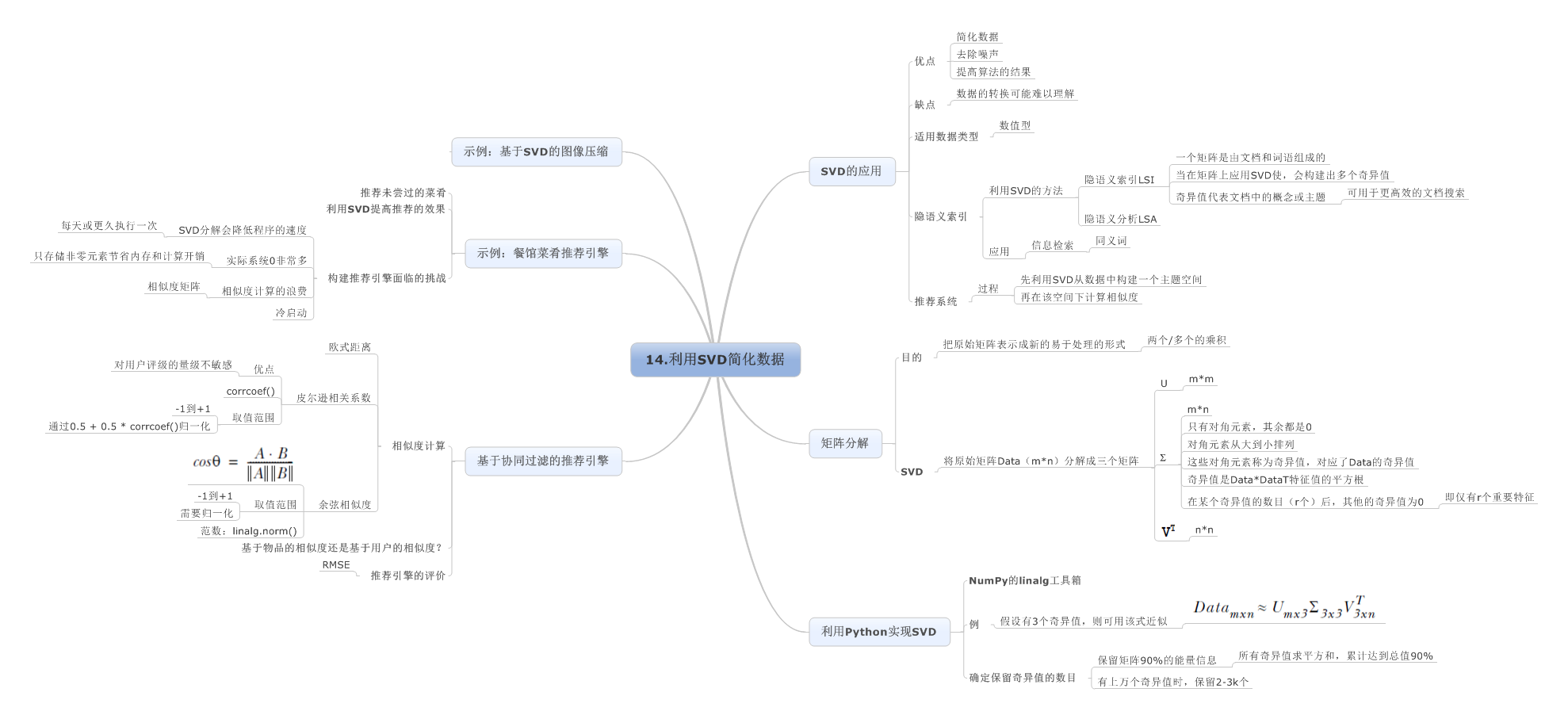
14.利用SVD简化数据
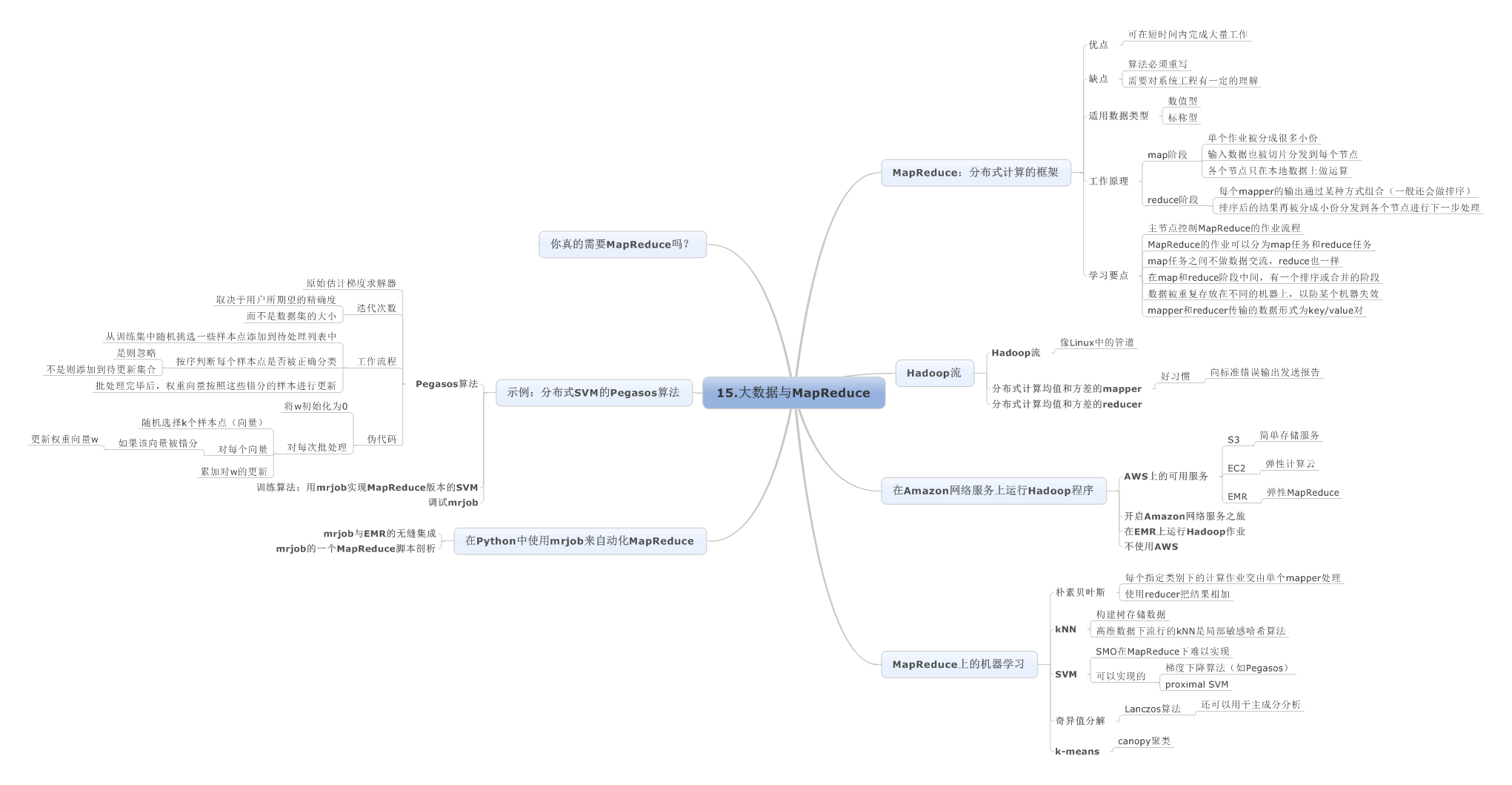
15.大数据与MapReduce