
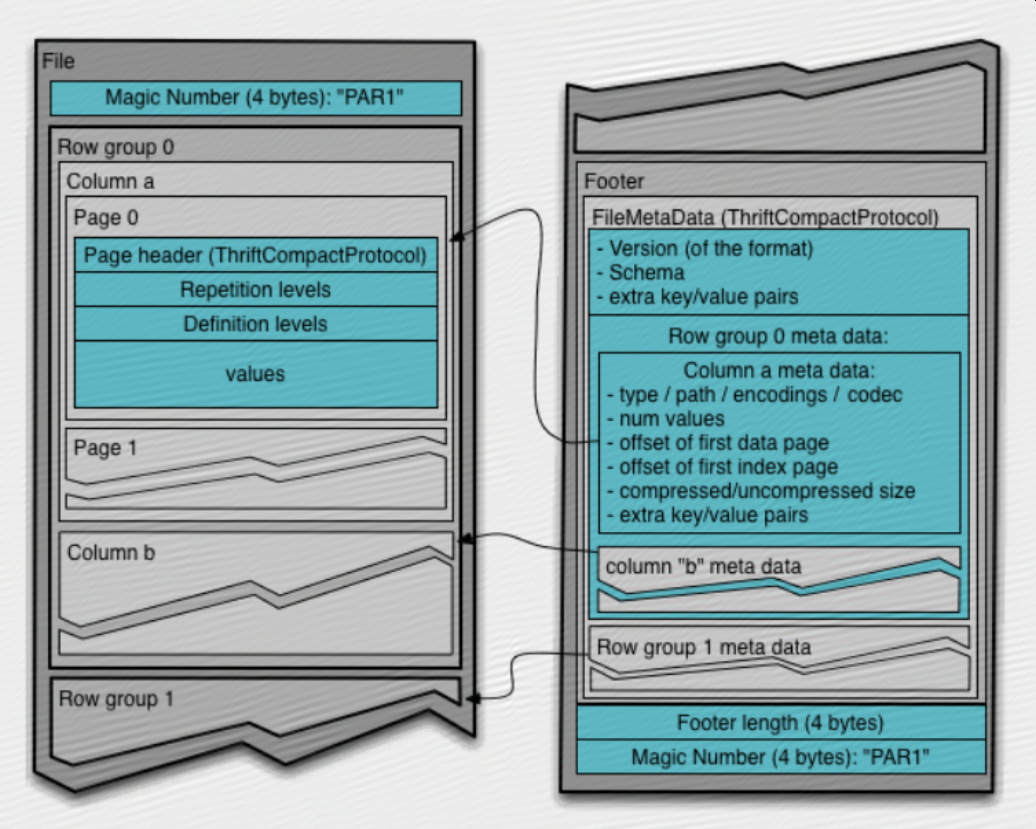
层次结构:
file -> row groups -> column chunks -> pages(data/index/dictionary)
Motivation
We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
Parquet is built from the ground up with complex nested data structures in mind, and uses the record shredding and assembly algorithm described in the Dremel paper. We believe this approach is superior to simple flattening of nested name spaces.
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
Parquet is built to be used by anyone. The Hadoop ecosystem is rich with data processing frameworks, and we are not interested in playing favorites. We believe that an efficient, well-implemented columnar storage substrate should be useful to all frameworks without the cost of extensive and difficult to set up dependencies.
Parquet是为了让Hadoop生态的任何项目都可以利用压缩和列式存储的优点;Parquet生来就支持复杂的嵌套数据结构,使用了Dremel论文里提到的记录分片和整合算法;Parquet支持高效的压缩和编码scheme,很多项目都证明了这会极大的提升查询性能;
Glossary
Block (hdfs block): This means a block in hdfs and the meaning is unchanged for describing this file format. The file format is designed to work well on top of hdfs.
File: A hdfs file that must include the metadata for the file. It does not need to actually contain the data.
Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file.
Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which is interleaved in a column chunk.
Hierarchically, a file consists of one or more row groups. A row group contains exactly one column chunk per column. Column chunks contain one or more pages.
一个file包含一个或多个row group,一个row group里每个column都包含唯一一个column chunk,一个column chunk包含一个或多个page;
Metadata
There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All thrift structures are serialized using the TCompactProtocol.
The file metadata contains the locations of all the column metadata start locations.
Metadata is written after the data to allow for single pass writing.
Readers are expected to first read the file metadata to find all the column chunks they are interested in. The columns chunks should then be read sequentially.
有3种元数据:file metadata,column metadata和page header metadata;file metadata包含了所有column metadata的起始位置;reader应该先读file metadata来找到它们感兴趣的column chunk;

The format is explicitly designed to separate the metadata from the data. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files.
这种格式的设计是为了将metadata和data分离,这样就可以将不同的列的数据拆分到不同的文件,同时有一个metadata文件可以引用多个data文件;