zookeeper3.4.11

一 简介
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them ,which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
zookeeper是一个中心化的服务,可以用来:1 维护配置信息;2 命名服务;3 提供分布式同步;4 提供分组服务;
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchal namespace which is organized similarly to a standard file system.The name space consists of data registers - called znodes, in ZooKeeper parlance - and these are similar to files and directories. Unlike a typical file system, which is designed for storage, ZooKeeper data is kept in-memory, which means ZooKeeper can acheive high throughput and low latency numbers.
zookeeper提供一个共享的命名空间,这个命名空间非常像一个文件系统(由文件和目录组成),命名空间由znode组成;与文件系统不同的是,zookeeper的数据是放在内存的,而且zookeeper的“目录”(znode)也可以写数据;
1 部署视图
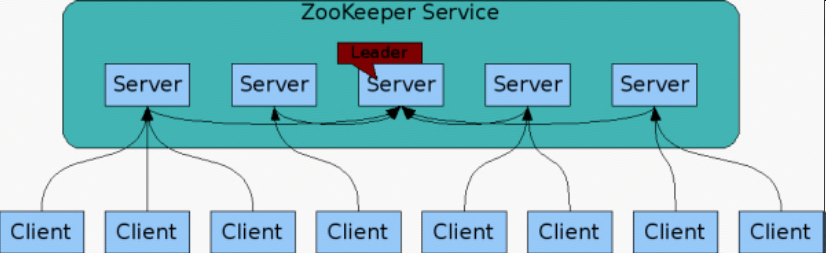
- The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with a transaction logs and snapshots in a persistent store. As long as a majority of the servers are available, the ZooKeeper service will be available.
- Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
zookeeper服务中的每台服务器都知道其他服务器的地址,并且任意两台服务器之间都互相连接;zookeeper服务器除了内存数据之外,还会在外部存储存放transaction logs和sampshots;只要zookeeper集群中的大多数服务器存活,即 (n+1)/2,zookeeper集群就可以提供服务;
zookeeper客户端只连接到其中一台zookeeper服务器,客户端会维护一个到服务器端的TCP长连接,通过这个连接来发送请求,接收响应,获取watch事件,发送心跳等;如果当前连接断掉,客户端会尝试连接到另外一台zookeeper服务器;
2 数据视图
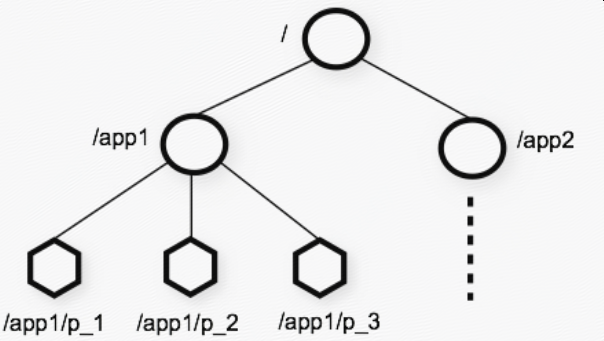
- The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper's name space is identified by a path.
- Unlike is standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory.
- ZooKeeper also has the notion of ephemeral nodes. These znodes exists as long as the session that created the znode is active. When the session ends the znode is deleted.
- ZooKeeper supports the concept of watches. Clients can set a watch on a znodes. A watch will be triggered and removed when the znode changes. When a watch is triggered the client receives a packet saying that the znode has changed. And if the connection between the client and one of the Zoo Keeper servers is broken, the client will receive a local notification.
zookeeper提供的命名空间非常像文件系统,有几点区别:1 “目录”也可以存放数据(zookeeper中没有目录和文件的概念,所有的节点都是znode,即可以存放数据又可以有子节点);2 支持Ephemeral节点即临时节点 ,临时节点的生命周期与客户端的session保持一致;3 支持watch,即订阅,当znode变化时对应的watch事件会被触发;
3 数据更新过程
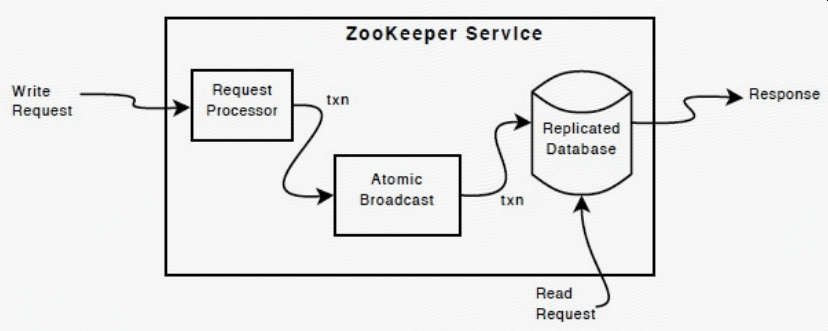
- Every ZooKeeper server services clients. Clients connect to exactly one server to submit irequests. Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol.
- As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
每一个zookeeper服务器都会响应客户端连接,每个客户端只连接到一台服务器,客户端的读请求直接由当前连接的服务器查询本地数据来响应,客户端的写请求都会被重定向到作为leader的服务器处理,除了leader之外的服务器称为follower(另外还有一种observer后边会讲到);
4 Session状态机
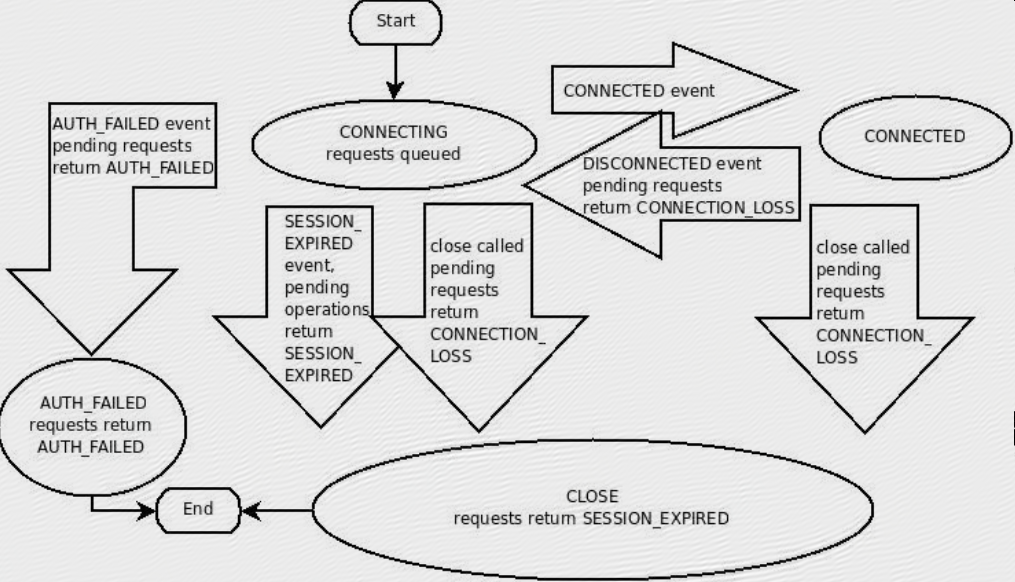
- A ZooKeeper client establishes a session with the ZooKeeper service by creating a handle to the service using a language binding. Once created, the handle starts of in the CONNECTING state and the client library tries to connect to one of the servers that make up the ZooKeeper service at which point it switches to the CONNECTED state. During normal operation will be in one of these two states. If an unrecoverable error occurs, such as session expiration or authentication failure, or if the application explicitly closes the handle, the handle will move to the CLOSED state.
客户端建立连接时首先会进入CONNECTING 状态,连接成功之后进入CONNECTED状态,当连接关闭之后会进入CLOSED状态;
5 Guarantees
-
Sequential Consistency - Updates from a client will be applied in the order that they were sent.
-
Atomicity - Updates either succeed or fail. No partial results.
-
Single System Image - A client will see the same view of the service regardless of the server that it connects to.
-
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
-
Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
保证:串行一致性;原子性;持久性;实时性;
二 安装
1 配置
$ZOOKEEPER_HOME/conf/zoo.cfg
tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
tickTime the basic time unit in milliseconds used by ZooKeeper. It is used to do heartbeats and the minimum session timeout will be twice the tickTime.
dataDir the location to store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
clientPort the port to listen for client connections
initLimit is timeouts ZooKeeper uses to limit the length of time the ZooKeeper servers in quorum have to connect to a leader.
syncLimit limits how far out of date a server can be from a leader.
zookeeper核心的几个配置就是以上5个;
The entries of the form server.X list the servers that make up the ZooKeeper service. When the server starts up, it knows which server it is by looking for the file myid in the data directory. That file has the contains the server number, in ASCII.
Peers use the former port to connect to other peers. Such a connection is necessary so that peers can communicate, for example, to agree upon the order of updates. More specifically, a ZooKeeper server uses this port to connect followers to the leader. When a new leader arises, a follower opens a TCP connection to the leader using this port. Because the default leader election also uses TCP, we currently require another port for leader election. This is the second port in the server entry.
zookeeper集群中所有服务器都配置在server.X中,当一台服务器启动时,他首先会到数据目录中找到myid文件,找到自己的id,然后会同集群中的其他服务器建立连接,这里的连接有两个,一个用于选举,一个用于通讯;
文件细节:
The snapshot files stored in the data directory are fuzzy snapshots in the sense that during the time the ZooKeeper server is taking the snapshot, updates are occurring to the data tree. The suffix of the snapshot file names is the zxid, the ZooKeeper transaction id, of the last committed transaction at the start of the snapshot. Thus, the snapshot includes a subset of the updates to the data tree that occurred while the snapshot was in process. The snapshot, then, may not correspond to any data tree that actually existed, and for this reason we refer to it as a fuzzy snapshot. Still, ZooKeeper can recover using this snapshot because it takes advantage of the idempotent nature of its updates. By replaying the transaction log against fuzzy snapshots ZooKeeper gets the state of the system at the end of the log.
The Log Directory contains the ZooKeeper transaction logs. Before any update takes place, ZooKeeper ensures that the transaction that represents the update is written to non-volatile storage. A new log file is started when the number of transactions written to the current log file reaches a (variable) threshold. The threshold is computed using the same parameter which influences the frequency of snapshotting (see snapCount above). The log file's suffix is the first zxid written to that log.
zookeeper数据目录中有两个文件,一个是snapshot,即快照文件,一个是transaction log,即日志文件,zookeeper会将所有的写操作全部记录到日志文件中,同时会定期将内存中的数据写到快照文件中,通过这两个文件,zookeeper可以保证数据不丢失同时重启后可以快速恢复数据;
snapshot文件命名为snapshot.$last_zxid,后缀为快照文件中最后一条日志的id,比如snapshot.3e0d57d547
transaction log文件命名为:log.$first_zxid,后缀为日志文件中第一条日志的id,比如log.3e0d4bffd7
2 启动
bin/zkServer.sh start
进程
hadoop 150952 4.9 1.6 22934232 1103420 ? Sl Mar14 11954:12 /$JAVA_HOME/bin/java -Dzookeeper.log.dir=/$ZOOKEEPER_HOME -Dzookeeper.root.logger=INFO,CONSOLE -cp /$ZOOKEEPER_HOME/bin/../build/classes:/$ZOOKEEPER_HOME/bin/../build/lib/*.jar:/$ZOOKEEPER_HOME/bin/../lib/slf4j-log4j12-1.6.1.jar:/$ZOOKEEPER_HOME/bin/../lib/slf4j-api-1.6.1.jar:/$ZOOKEEPER_HOME/bin/../lib/netty-3.7.0.Final.jar:/$ZOOKEEPER_HOME/bin/../lib/log4j-1.2.16.jar:/$ZOOKEEPER_HOME/bin/../lib/jline-0.9.94.jar:/$ZOOKEEPER_HOME/bin/../zookeeper-3.4.6.jar:/$ZOOKEEPER_HOME/bin/../src/java/lib/*.jar:/$ZOOKEEPER_HOME/bin/../conf: -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /$ZOOKEEPER_HOME/bin/../conf/zoo.cfg
数据目录结构
[user@zk_server_1 version-2]$ ls /$ZOOKEEPER_DATA_DIR/
myid version-2 zookeeper_server.pid
[user@zk_server_1 version-2]$ ls /$ZOOKEEPER_DATA_DIR/version-2/
acceptedEpoch log.3e0d4bffd7 log.3e0d57d549 log.3e0d6255f7 log.3e0d6df7e9 log.3e0d790349 snapshot.3e0d4bffd5 snapshot.3e0d57d547 snapshot.3e0d6255f2 snapshot.3e0d6df7e7 snapshot.3e0d790347
currentEpoch log.3e0d4d1a04 log.3e0d58a803 log.3e0d63629b log.3e0d6f0d5c log.3e0d7a4523 snapshot.3e0d4d1a02 snapshot.3e0d58a801 snapshot.3e0d636299 snapshot.3e0d6f0d5a snapshot.3e0d7a4521
log.3e0d430aed log.3e0d4e724a log.3e0d59a04c log.3e0d64cc1f log.3e0d6ff7ba log.3e0d7bc17d snapshot.3e0d4e7248 snapshot.3e0d59a04a snapshot.3e0d64cc1d snapshot.3e0d6ff7b8 snapshot.3e0d7bc17b
log.3e0d43dadd log.3e0d4ff8ce log.3e0d5ad0a0 log.3e0d65fd11 log.3e0d714d93 snapshot.3e0d43dadb snapshot.3e0d4ff8cc snapshot.3e0d5ad09d snapshot.3e0d65fd0f snapshot.3e0d714d91
log.3e0d454827 log.3e0d5150a7 log.3e0d5bb95f log.3e0d67015a log.3e0d724f8d snapshot.3e0d454825 snapshot.3e0d5150a5 snapshot.3e0d5bb95b snapshot.3e0d670158 snapshot.3e0d724f8b
log.3e0d465a2e log.3e0d52156c log.3e0d5ce712 log.3e0d67fa44 log.3e0d731ca5 snapshot.3e0d465a2c snapshot.3e0d52156a snapshot.3e0d5ce710 snapshot.3e0d67fa42 snapshot.3e0d731ca3
log.3e0d47ac00 log.3e0d531018 log.3e0d5dae9f log.3e0d6932ab log.3e0d748b2d snapshot.3e0d47abfe snapshot.3e0d531016 snapshot.3e0d5dae9d snapshot.3e0d6932ad snapshot.3e0d748b2b
log.3e0d48746a log.3e0d548417 log.3e0d5f18d5 log.3e0d6a0150 log.3e0d75de64 snapshot.3e0d487468 snapshot.3e0d548415 snapshot.3e0d5f18d8 snapshot.3e0d6a014e snapshot.3e0d75de62
log.3e0d49eff7 log.3e0d55620a log.3e0d5fdcc3 log.3e0d6b5212 log.3e0d76e90e snapshot.3e0d49eff5 snapshot.3e0d556208 snapshot.3e0d5fdcc1 snapshot.3e0d6b5210 snapshot.3e0d76e90c
log.3e0d4af170 log.3e0d56bd2c log.3e0d60d48a log.3e0d6cc57c log.3e0d780e44 snapshot.3e0d4af16e snapshot.3e0d56bd2a snapshot.3e0d60d485 snapshot.3e0d6cc57a snapshot.3e0d780e42
三 使用
1 ZooKeeper Commands: The Four Letter Words
$ echo mntr | nc localhost 2185
- conf
- Print details about serving configuration.
- cons
- List full connection/session details for all clients connected to this server. Includes information on numbers of packets received/sent, session id, operation latencies, last operation performed, etc...
- crst
- Reset connection/session statistics for all connections.
- dump
- Lists the outstanding sessions and ephemeral nodes. This only works on the leader.
- envi
- Print details about serving environment
- ruok
- Tests if server is running in a non-error state. The server will respond with imok if it is running. Otherwise it will not respond at all.
- srst
- Reset server statistics.
- srvr
- Lists full details for the server.
- stat
- Lists brief details for the server and connected clients.
- wchs
- Lists brief information on watches for the server.
- wchc
- Lists detailed information on watches for the server, by session. This outputs a list of sessions(connections) with associated watches (paths). Note, depending on the number of watches this operation may be expensive (ie impact server performance), use it carefully.
- wchp
- Lists detailed information on watches for the server, by path. This outputs a list of paths (znodes) with associated sessions. Note, depending on the number of watches this operation may be expensive (ie impact server performance), use it carefully.
- mntr
- Outputs a list of variables that could be used for monitoring the health of the cluster.
示例:
-bash-4.1$ echo stat|nc $zk_server_1 2181
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Clients:
/zk_client_1:59407[1](queued=0,recved=55,sent=55)
/zk_client_2:40094[0](queued=0,recved=1,sent=0)
/zk_client_3:60926[1](queued=0,recved=115,sent=115)
/zk_client_4:59288[1](queued=0,recved=56,sent=56)
/zk_client_5:14155[1](queued=0,recved=115,sent=115)
/zk_client_6:18602[1](queued=0,recved=115,sent=115)Latency min/avg/max: 0/0/146
Received: 6294
Sent: 6376
Connections: 6
Outstanding: 0
Zxid: 0x3e0d1cccd4
Mode: follower
Node count: 26394
Zxid Every change to the ZooKeeper state receives a stamp in the form of a zxid (ZooKeeper Transaction Id). This exposes the total ordering of all changes to ZooKeeper. Each change will have a unique zxid and if zxid1 is smaller than zxid2 then zxid1 happened before zxid2.
The ZooKeeper service can be monitored in one of two primary ways; 1) the command port through the use of 4 letter words and 2) JMX.
zookeeper中数据的任何变化都有一个唯一的zxid,并且是有序的,即先发生的变化的zxid一定小于后发生的变化的zxid;
zookeeper可以通过两种方式监控:4字命令 和 jmx;
2 命令行客户端
$ bin/zkCli.sh -server 127.0.0.1:2181[zkshell: 0] help ZooKeeper host:port cmd args get path [watch] ls path [watch] set path data [version] delquota [-n|-b] path quit printwatches on|off createpath data acl stat path [watch] listquota path history setAcl path acl getAcl path sync path redo cmdno addauth scheme auth delete path [version] setquota -n|-b val path
示例:
[zkshell: 12] get /zk_test my_data cZxid = 5 ctime = Fri Jun 05 13:57:06 PDT 2009 mZxid = 5 mtime = Fri Jun 05 13:57:06 PDT 2009 pZxid = 5 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0 dataLength = 7 numChildren = 0
-
czxid
The zxid of the change that caused this znode to be created.
-
mzxid
The zxid of the change that last modified this znode.
-
pzxid
The zxid of the change that last modified children of this znode.
-
ctime
The time in milliseconds from epoch when this znode was created.
-
mtime
The time in milliseconds from epoch when this znode was last modified.
-
version
The number of changes to the data of this znode.
-
cversion
The number of changes to the children of this znode.
-
aversion
The number of changes to the ACL of this znode.
-
ephemeralOwner
The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero.
-
dataLength
The length of the data field of this znode.
-
numChildren
The number of children of this znode.
znode节点的各个属性如上;
3 java客户端
org.apache.zookeeper.ZooKeeper
- This is the main class of ZooKeeper client library. To use a ZooKeeper service, an application must first instantiate an object of ZooKeeper class. All the iterations will be done by calling the methods of ZooKeeper class. The methods of this class are thread-safe unless otherwise noted.
- Once a connection to a server is established, a session ID is assigned to the client. The client will send heart beats to the server periodically to keep the session valid.
- The application can call ZooKeeper APIs through a client as long as the session ID of the client remains valid.
- If for some reason, the client fails to send heart beats to the server for a prolonged period of time (exceeding the sessionTimeout value, for instance), the server will expire the session, and the session ID will become invalid. The client object will no longer be usable. To make ZooKeeper API calls, the application must create a new client object.
- If the ZooKeeper server the client currently connects to fails or otherwise does not respond, the client will automatically try to connect to another server before its session ID expires. If successful, the application can continue to use the client.
- The ZooKeeper API methods are either synchronous or asynchronous. Synchronous methods blocks until the server has responded. Asynchronous methods just queue the request for sending and return immediately. They take a callback object that will be executed either on successful execution of the request or on error with an appropriate return code (rc) indicating the error.
- Some successful ZooKeeper API calls can leave watches on the "data nodes" in the ZooKeeper server. Other successful ZooKeeper API calls can trigger those watches. Once a watch is triggered, an event will be delivered to the client which left the watch at the first place. Each watch can be triggered only once. Thus, up to one event will be delivered to a client for every watch it leaves.
- A client needs an object of a class implementing Watcher interface for processing the events delivered to the client. When a client drops the current connection and re-connects to a server, all the existing watches are considered as being triggered but the undelivered events are lost. To emulate this, the client will generate a special event to tell the event handler a connection has been dropped. This special event has EventType None and KeeperState Disconnected.
四 其他
The format of snapshot and log files does not change between standalone ZooKeeper servers and different configurations of replicated ZooKeeper servers. Therefore, you can pull these files from a running replicated ZooKeeper server to a development machine with a stand-alone ZooKeeper server for trouble shooting.
Using older log and snapshot files, you can look at the previous state of ZooKeeper servers and even restore that state. The LogFormatter class allows an administrator to look at the transactions in a log.
snapshot和log文件的格式是一致的,所以可以很容易的将线上集群的数据文件拷贝到本地来查找问题或重现错误;
A server might not be able to read its database and fail to come up because of some file corruption in the transaction logs of the ZooKeeper server. You will see some IOException on loading ZooKeeper database. In such a case, make sure all the other servers in your ensemble are up and working. Use "stat" command on the command port to see if they are in good health. After you have verified that all the other servers of the ensemble are up, you can go ahead and clean the database of the corrupt server. Delete all the files in datadir/version-2 and datalogdir/version-2/. Restart the server.
一旦zookeeper数据目录中的某些文件有损坏,zookeeper可能由于无法读取数据导致启动失败,这时可以先检查一下其他服务器(集群中的大多数)是否正常,如果正常的话,可以将有文件损坏的数据目录文件清空后重启zookeeper,重启后zookeeper会自动同步最新的数据;
Although ZooKeeper performs very well by having clients connect directly to voting members of the ensemble, this architecture makes it hard to scale out to huge numbers of clients. The problem is that as we add more voting members, the write performance drops. This is due to the fact that a write operation requires the agreement of (in general) at least half the nodes in an ensemble and therefore the cost of a vote can increase significantly as more voters are added.
We have introduced a new type of ZooKeeper node called an Observer which helps address this problem and further improves ZooKeeper's scalability. Observers are non-voting members of an ensemble which only hear the results of votes, not the agreement protocol that leads up to them. Other than this simple distinction, Observers function exactly the same as Followers - clients may connect to them and send read and write requests to them. Observers forward these requests to the Leader like Followers do, but they then simply wait to hear the result of the vote. Because of this, we can increase the number of Observers as much as we like without harming the performance of votes.
由于zookeeper的对写操作的投票机制,所以集群规模持续扩大会伴随着投票成本的上升,这时zookeeper引入了一种新的节点类型即observer,observer不参与投票,只负责同步数据和相应客户端需求;
五 更多
1 为什么zookeeper集群由奇数(2n+1)个节点组成?
这里有两个原因,一个是为了防止脑裂,只有n+1个节点存活集群才能正常工作,即2n+1个节点只能有1个集群正常工作;一个是为了数据可靠性,每一份数据只要有n+1个节点保存成功,则数据不会丢失,这一点可以严格的通过数据方法来证明,最简单的是反证法,假设有一个数据在n+1个节点上保存成功,但是丢失,说明保存成功的n+1个节点目前都不可用,但是如果只有n个节点存活则集群无法正常工作,可以推断假设错误;