一 对比
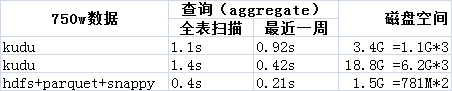
存储空间对比:

查询性能对比:
二 设计方案
将数据拆分为:历史数据(hdfs+parquet+snappy)+ 近期数据(kudu),可以兼具各种优点:
- 1)整体低于10%的磁盘占用;
- 2)更少的查询耗时;
- 3)近期数据实时更新;
- 4)近期数据可修改;
- 5)kudu集群重启时间降低90%;
- 6)impala并行scan:scan kudu + scan hdfs;
三 改造方案
利用视图
create view v_table as
select * from parquet_table where dt < 'seven days ago'
union all
select * from kudu_table where dt >= 'seven days ago';
client将kudu_table替换为v_table即可;
四 其他
kudu问题:
- flume kudu sink使用kudu client版本过低,有bug,不会自动刷新token,7天之后会因为token失效报错;升级kudu client后可以解决bug,但是kudu client和flume使用的guava库版本有冲突;
- 按dt分区后tablet数量过多,磁盘占用空间过大,内存占用过多;
- 因为tablet数量多,磁盘空间大,每次kudu集群重启需要10-20分钟做initialize;
- kudu内存占用过多时会拒绝写操作;
- 使用kudu作为单一数仓同时支持写入和查询,很容易相互影响,大量写入影响查询,大量查询影响写入,会导致数据丢失或者查询慢;
- kudu支持更新,一个delete或者drop就可以把所有数据全部删掉,作为单一数仓比较危险;