一、基本原理
AdaBoost是adaptive boosing的缩写,它是一种基于Boosting框架的算法。下图为该算法的迭代过程。
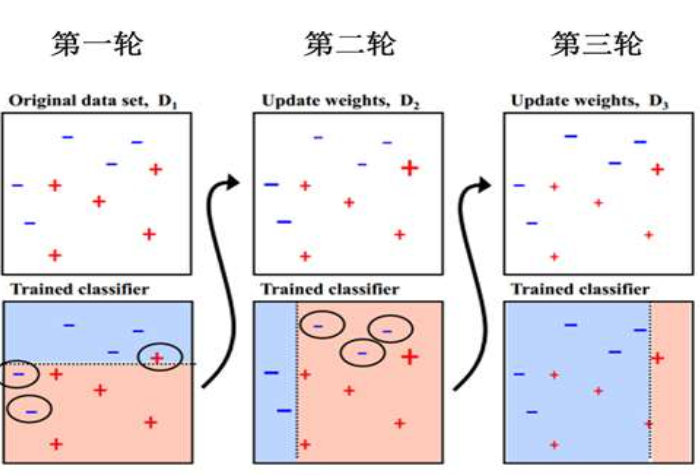
AdaBoost从原始数据集D1开始学习第个模型,经过三轮的迭代,得到三个弱分类器,每一轮的迭代都要评估下模型的分类误差,在一轮时把分错的样本进行加权,最后把三个分类器按照一定的权重组合起来得到一个强分类器。
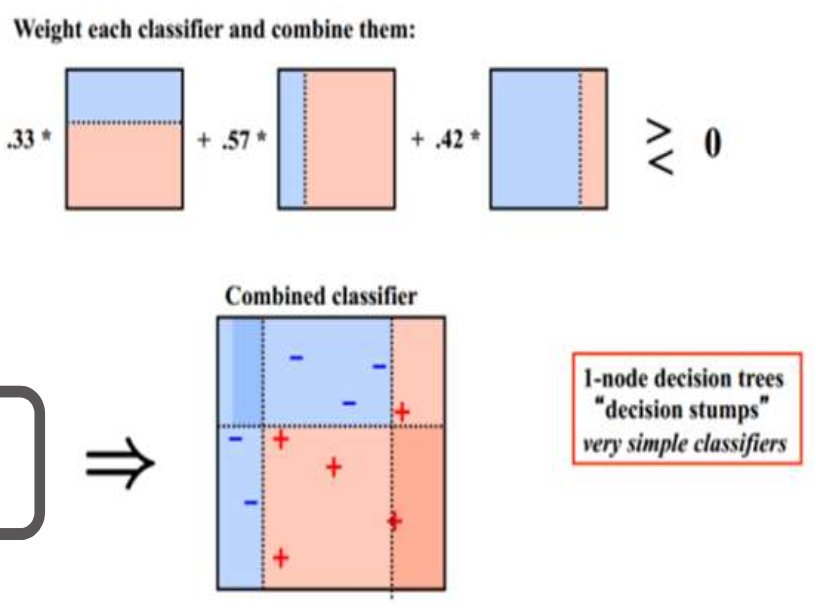
从上图可以看出,每一个弱分类器的模型都很简单,示例图中的它们只是一个一层的决策树,每一个弱分类器在融合的时候都有一个权重,三个弱分类器融合后,变成一个能力更强的复杂模型。
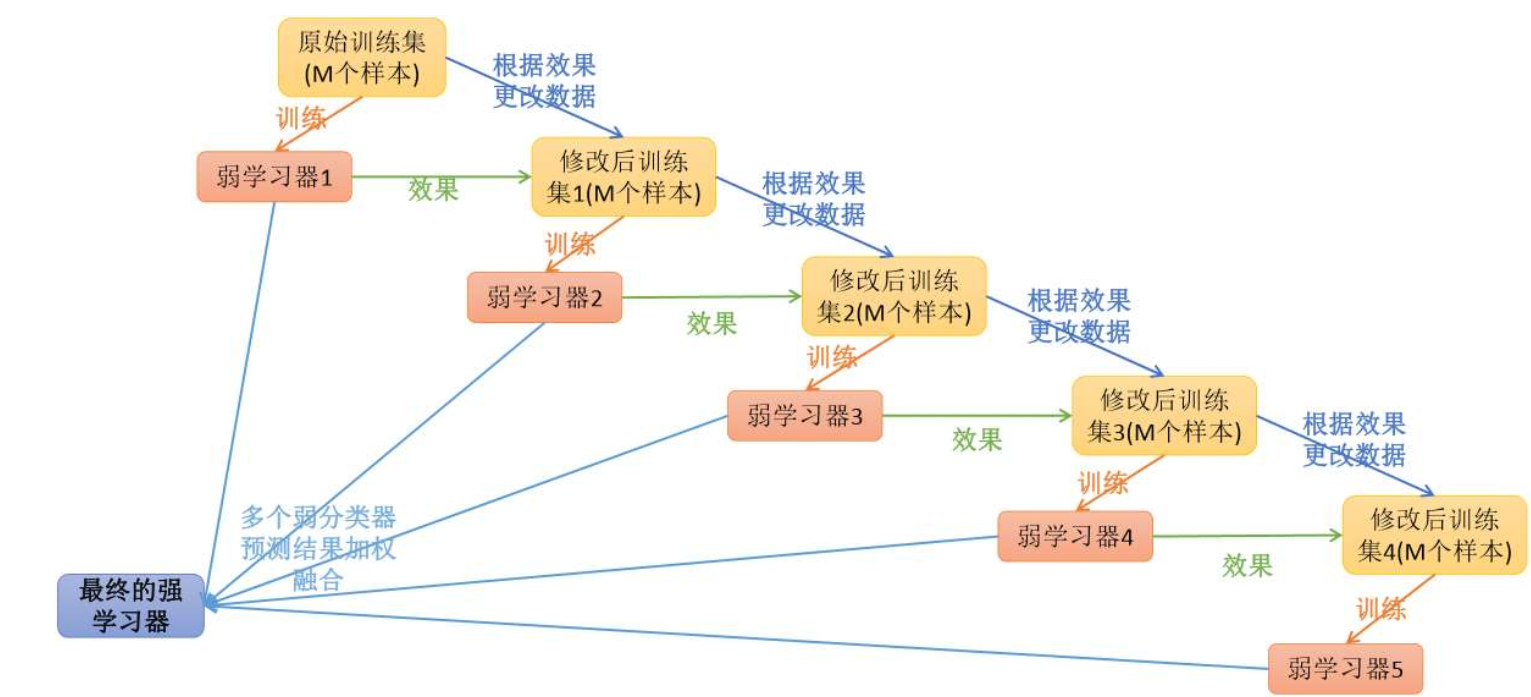
由上图可知,AdaBoost是由多个弱分类器组成,每次由一个弱分类器训练数据集,然后把这个训练器分错的数据集权重加大,没分错的减小权重,再由下一个弱学习器训练这个数据集,这样一直迭代下去,最后融合成一个最强的学习器。
AdaBoost算法构建过程,
1、假设训练集T = {(X1,Y1),(X2,Y2)……(Xn,Yn)}
2、初始化训练数据权重分布,
D1 = (Wl1,Wl2……Wln),Wli = 1/n,i=1,2……n
3、使用具有权值分布的Dm的训练集学习,得到基本分类器
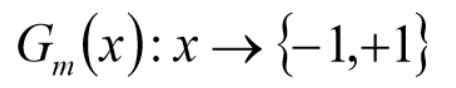
4、计算Gm(x)在训练集上的分类误差
5、计算Gm(x)模型的权重系数am
6、权重训练集的权值分布
7、这里Zm是规范化因子(规一化)
8、构建分类器的线性组合
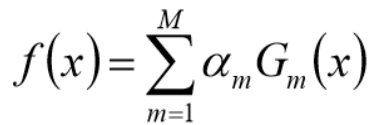
9、得到最终分类器
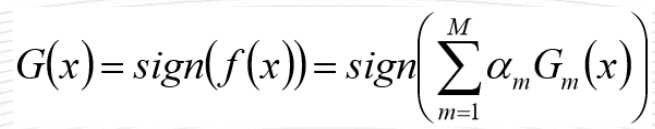
AdaBoost算法推导


算法的直观理解





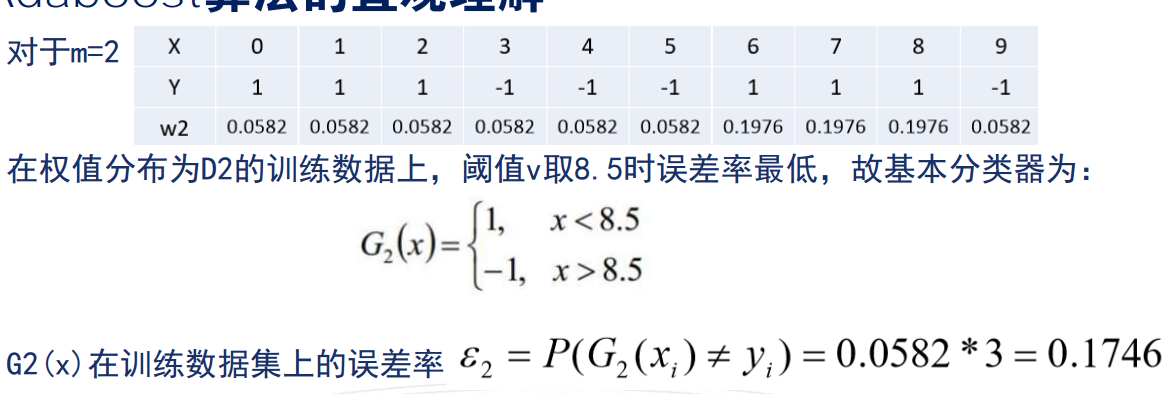



AdaBoost小结
1、AdaBoost是一种Boosting的融合算法,它通过级联的方式,把一系列的弱学习模型融合在一起变成一个强分类器。
2、AdaBoost既可以做分类,也可以做回归
3、AdaBoost做分类模型的时候,默认的基学习类型是决策树。
4、AdaBoost的多个子模型通过加权求和的方式融合,并不是简单的求平均,子模型的权重取决于子模型的误差率大小,误差率越小,权值越大