1.并发和并行的区别:
并发:宏观上是在同时运行的,微观上是一个一个顺序执行的,同一时刻不止有一个cpu在工作
并行:微观上就是同时执行的,同一时刻不止有一个cpu在工作
2.什么是进程:
一个运行中的程序就是一个进程,是计算机中最小的资源分配单位
3.什么是同步:
程序顺序执行,多个任务之间串行执行
4.什么是异步:
多个任务同时运行
5.IO操作:
input 输入到内存 read load recv accept recvfrom input
output 从内存输出 write dump send connect sendto print
6.什么是阻塞:
recv recvfrom accept
程序由于不符合某个条件或者要等待某个条件满足在某一个地方进入等待状态
7.什么是非阻塞:
sk.setblocking(Fasle)就让这个socket模型不阻塞了
8.通过id获取进程号:
import os,time print(os.getpid(),os.getppid()) #get pid process id 获取当前进程号 #get ppid parent process id 获取当前父进程号 time.sleep(20) print(os.getpid())
9.子进程和父进程之间的关系:
pycharm启动了py文件,py文件就是子进程,pycharm就是父进程
10.如何在python开启进程:
multiprocess模块
multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块
process模块*****
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'egon',)
4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
5 name为子进程的名称
11.开启子进程的第一种方式:
import time from multiprocessing import Process #进程模块 def son_process(): print('son start') time.sleep(1) print('son end') if __name__ == '__main__': p = Process(target=son_process) #先执行子进程要执行的代码 p.start() #通知操作系统开启一个子进程 print('主进程') #操作系统相应需求 分配给这个进程一些资源 执行进程中的代码
开启了一个子进程就已经实现了并发: 父进程(主进程)和子进程并发(同时执行)
12.开启子进程的另一种方式:
import os
from multiprocessing import Process
class MyProcess(Process):
def __init__(self,参数):
super().__init__()
self.一个属性 = 参数
def run(self):
print('子进程中要执行的代码')
if __name__ == '__main__':
conn = '一个链接'
mp = MyProcess(conn)
mp.start()
可以开启多个子进程么:
import time
from multiprocessing import Process
def son_process():
print('son start')
time.sleep(1)
print('son end')
if __name__ == '__main__':
for i in range(3):
p = Process(target=son_process)
p.start()
可以给子进程中传参数么
from multiprocessing import Process
print('son start',i)
time.sleep(1)
print('son end',i)
if __name__ == '__main__':
for i in range(10):
p = Process(target=son_process,args=(i,)) # i,必须是一个元祖
p.start() # 通知操作系统 start并不意味着子进程已经开始了
通过并发实现一个有并发效果的socket server
server端
import socket,time
from multiprocessing import Process
def talk(conn):
conn, addr = sk.accept()
print(conn)
while True:
msg = conn.recv(1024).decode()
time.sleep(10)
conn.send(msg.upper().encode())
if __name__ == '__main__':
# 这句话下面的所有代码都只在主进程中执行
sk = socket.socket()
sk.bind(('127.0.0.1',9000))
sk.listen()
while True:
conn,addr = sk.accept()
Process(target=talk,args=(sk,)).start()
卡 大量的while True 并且代码中并没有太多的其他操作
如果我们使用socketserver,不会这么卡
多进程确实可以帮助我们实现并发效果,但是还不够完美
操作系统没开启一个进程要消耗大量的资源
操作系统要负责调度进程 进程越多 调度起来就越吃力
client端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
while True:
sk.send(b'hello')
print(sk.recv(1024))
主进程和子进程之间的关系
import time
from multiprocessing import Process
def son_process(i):
print('son start',i)
time.sleep(1)
print('son end',i)
if __name__ == '__main__':
for i in range(10):
p = Process(target=son_process,args=(i,))
p.start()
print('主进程的代码执行完毕')
主进程会等待子进程结束之后才结束
为什么?
父进程负责创建子进程,也负责回收子进程的资源
主进程可不可以直接结束一个子进程?
import time
from multiprocessing import Process
def son_process(i):
while True:
print('son start',i)
time.sleep(0.5)
print('son end',i)
if __name__ == '__main__':
p = Process(target=son_process, args=(1,))
p.start() # 开启一个子进程,异步的
print('主进程的代码执行完毕')
print(p.is_alive()) # 子进程还活着
p.terminate() # 结束一个子进程,异步的
print(p.is_alive()) # 子进程还在活着
time.sleep(0.1)
print(p.is_alive())
进程之间数据隔离的概念
import time
from multiprocessing import Process
n = [100] def sub_n(): global n # 子进程对于主进程中的全局变量的修改是不生效的 n.append(1) print('子进程n : ',n) if __name__ == '__main__': p = Process(target = sub_n) p.start() p.join() # 阻塞 直到子进程p结束 print('主进程n : ',n)
开启十个进程执行subn
主进程里的print('主进程n : ',n)这句话在十个子进程执行完毕之后才执行
n = [100]
import random
def sub_n():
global n # 子进程对于主进程中的全局变量的修改是不生效的
time.sleep(random.random())
n.append(1)
print('子进程n : ',n)
if __name__ == '__main__':
p_lst = []
for i in range(10):
p = Process(target = sub_n)
p.start()
p_lst.append(p)
for p in p_lst:p.join() # 阻塞 只有一个条件是能够让我继续执行 这个条件就是子进程结束
print('主进程n : ',n)
join的扩展
n = [100]
def sub_n():
global n # 子进程对于主进程中的全局变量的修改是不生效的
n.append(1)
print('子进程n : ',n)
time.sleep(10)
print('子进程结束')
if __name__ == '__main__':
p = Process(target = sub_n)
p.start()
p.join(timeout = 5) # 如果不设置超时时间 join会阻塞直到子进程p结束
# timeout超时
# 如果设置的超时时间,那么意味着如果不足5s子进程结束了,程序结束阻塞
# 如果超过5s还没有结束,那么也结束阻塞
print('主进程n : ',n)
p.terminate() # 也可以强制结束一个子进程
守护进程
什么是守护进程
监控系统
每隔1min中主动汇报当前程序的状态
import time
from multiprocessing import Process
def alive():
while True:
print('连接监控程序,并且发送报活信息')
time.sleep(0.6)
def func():
'主进程中的核心代码'
while True:
print('选择的项目')
time.sleep(1)
print('根据用户的选择做一些事儿')
if __name__ == '__main__':
p = Process(target=alive)
p.daemon = True # 设置子进程为守护进程,守护进程会随着主进程代码的结束而结束
p.start()
p = Process(target=func)
p.start()
设置子进程为守护进程,守护进程会随着主进程代码的结束而结束
由于主进程要负责给所有的子进程收尸,所以主进程必须是最后结束,守护进程只能在主进程的代码结束之后就认为主进程结束了
守护进程在主进程的代码结束之后就结束了,不会等待其他子进程结束
希望守护进程必须等待所有的子进程结束之后才结束
import time
from multiprocessing import Process
def alive():
while True:
print('连接监控程序,并且发送报活信息')
time.sleep(0.6)
def func():
'主进程中的核心代码'
while True:
print('选择的项目')
time.sleep(1)
print('根据用户的选择做一些事儿')
if __name__ == '__main__':
p = Process(target=alive)
p.daemon = True # 设置子进程为守护进程,守护进程会随着主进程代码的结束而结束
p.start()
p = Process(target=func)
p.start()
p.join() # 在主进程中等待子进程结束,守护进程就可以帮助守护其他子进程了
守护进程
1.守护进程会等待主进程的代码结束而结束,不会等待其他子进程的结束
2.要想守护进程等待其他子进程,只需要在主进程中加上join
操作多个子进程的结束和join阻塞
for i in range(5):
pass
print(i) # i=4
lst = []
for i in range(5):
p = Process()
lst.append(p)
p.start()
for p in lst:
p.join()
p.terminate()
锁的概念*****
import json
import time
from multiprocessing import Process,Lock Lock#模块
def search(name):
'''查询余票的功能'''
with open('ticket') as f:
dic = json.load(f)
print(name , dic['count'])
def buy(name):
with open('ticket') as f:
dic = json.load(f)
time.sleep(0.1)
if dic['count'] > 0:
print(name,'买到票了')
dic['count'] -=1
time.sleep(0.1)
with open('ticket','w') as f:
json.dump(dic,f)
def get_ticket(name,lock):
search(name)
lock.acquire() # 只有第一个到达的进程才能获取锁,剩下的其他人都需要在这里阻塞
buy(name)
lock.release() # 有一个人还锁,会有一个人再结束阻塞拿到钥匙
if __name__ == '__main__':
lock = Lock()
for i in range(10):
p = Process(target=get_ticket,args=('name%s'%i,lock))
p.start()
信号量
对于锁 保证一段代码同一时刻只能有一个进程执行
对于信号量 保证一段代码同一时刻只能有n个进程执行
from multiprocessing import Semaphore semaphore信号量
sem = Semaphore(4) #实例化传一个参数 表示同时可以有四个进程可以来执行这段代码
sem.acquire()
print('拿走一把钥匙1')
sem.acquire()
print('拿走一把钥匙2')
sem.acquire()
print('拿走一把钥匙3')
sem.acquire()
print('拿走一把钥匙4')
sem.release() #拿走一把在还一把
sem.acquire()
print('拿走一把钥匙5') #等待有归还的钥匙才能拿到
信号量:
import time import random
from multiprocessing import Process,Semaphore
def ktv(name,sem): sem.acquire() #先抢钥匙 print("%s走进了ktv"%name) time.sleep(random.randint(5,10)) print("%s走出了ktv" % name) sem.release #出来还钥匙 还完钥匙剩下的接着拿 if __name__ == '__main__': sem = Semaphore(4) 100个人每四个人同时开一个进程 for i in range(100): p = Process(target=ktv,args = ('name%s'%i,sem)) p.start()
信号量:就是 锁+计数器实现的
普通的锁 acquire 1次 信号量 acquire 多次
count计数
count = 4
acquire count -= 1
当count减到0的时候 就阻塞
release count + = 1
只要count不为0,你就可以继续acquire
事件
from multiprocessing import Event
Event 事件类
e = Event()
e 事件对象
事件本身就带着标识 : False
wait 阻塞
它的阻塞条件是 对象标识为False
结束阻塞条件是 对象标识为True
对象的标识相关的:
set 将对象的标识设置为True
clear 将对象的标识设置为False
is_set 查看对象的标识是否为True
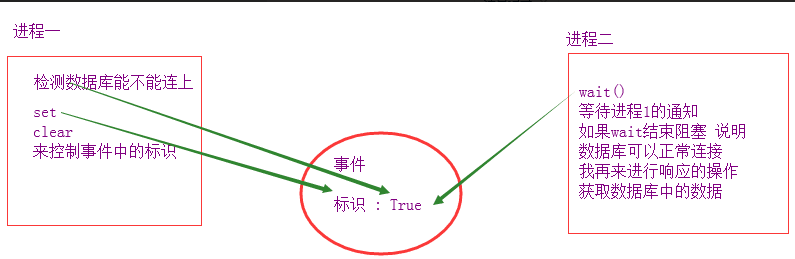
交通灯事件模型:

import time import random from multiprocessing import Event,Process
def traffic_light(e): print('�33[1;31m红灯亮�33[0m') while True: time.sleep(2) if e.is_set(): # 如果当前是绿灯 print('�33[1;31m红灯亮�33[0m') # 先打印红灯亮 e.clear() # 再把灯改成红色 else : # 当前是红灯 print('�33[1;32m绿灯亮�33[0m') # 先打印绿灯亮 e.set() # 再把灯变绿色
def car(e,carname): if not e.is_set(): print('%s正在等待通过'%carname) e.wait() print('%s正在通过'%carname)
if __name__ == '__main__': e = Event() p = Process(target=traffic_light,args = (e,)) p.start() for i in range(100): time.sleep(random.randrange(0,3)) p = Process(target=car, args=(e,'car%s'%i)) p.start()
这两个操作之间 存在同步关系
一个操作去确认另一个操作的执行条件是否打成
如何查看这个标识 : is_set
进程之间的通信(管道)
进程间通信: TPC
IPC Inter-Process Communication
实现进程之间通信的俩种机制:
管道 pipe
队列 Queue ******
进程之间的通信 队列:
from multiprocessing import Queue,Process
def consumer(q):
print(
'子进程 :', q.get()
)
if __name__ == '__main__':
q = Queue()
p = Process(target=consumer,args=(q,))
p.start()
q.put('hello,world')
生产者消费者模型 *****
为什么会有这个模型
单条生产线会导致效率下降,客户体验差等问题将一个解决数据的方案分成俩部分 生产和消费就可以通过调整生产者 和消费者的个数,来控制最佳的效果

import time
from multiprocessing import Queue,Process
def producer(name,food,num,q):
'''生产者'''
for i in range(num):
time.sleep(0.3) #每0.3秒生产一个
foodi = food + str(i)
print('%s生产了%s'%(name,foodi))
q.put(foodi)
def consumer(name,q): #consumer 消费者
while True:
food = q.get() # 等待接收数据
if food == None:break
print('%s吃了%s'%(name,food))
time.sleep(1)
if __name__ == '__main__':
q = Queue(maxsize=10) #实例化的结果 队列的大小为10
p1 = Process(target=producer,args = ('宝元','泔水',20,q))
p2 = Process(target=producer,args = ('战山','鱼刺',10,q))
c1 = Process(target=consumer, args=('alex', q))
c2 = Process(target=consumer, args=('wusir', q))
p1.start() # 开始生产
p2.start() # 开始生产
c1.start()
c2.start()
p1.join() # 生产者结束生产了
p2.join() # 生产者结束生产了
q.put(None) # put None 操作永远放在所有的生产者结束生产之后
q.put(None) # 有几个消费者 就put多少个None
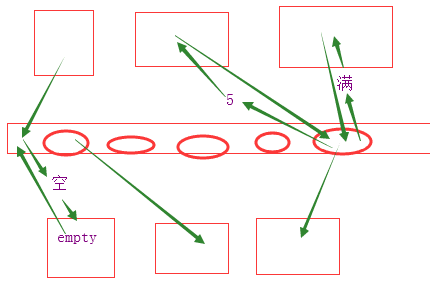
为什么队列为空 为满 这件事情不够准确
q.qsize() 队列的大小
q.full() 是否满了 满返回True
q.empty() 是否空了 空返回True

joinablequeue实现的生产者消费者模型

import time
from multiprocessing import JoinableQueue,Process
def consumer(name,q):
while True:
food = q.get()
time.sleep(1)
print('%s消费了%s'%(name,food))
q.task_done()
def producer(name,food,num,q):
'''生产者'''
for i in range(num):
time.sleep(0.3)
foodi = food + str(i)
print('%s生产了%s'%(name,foodi))
q.put(foodi)
q.join() # 消费者消费完毕之后会结束阻塞
if __name__ == '__main__':
q = JoinableQueue()
p1 = Process(target=producer, args=('宝元', '泔水', 20, q))
c1 = Process(target=consumer, args=('alex', q))
c2 = Process(target=consumer, args=('wusir', q))
c1.daemon = True
c2.daemon = True
p1.start()
c1.start()
c2.start()
p1.join()
消费者每消费一个数据会给队列发送一条信息
当每一个数据都被消费掉之后 joinablequeue的join阻塞行为就会结束
以上就是为什么我们要在生产完所有数据的时候发起一个q.join()
随着生产者子进程的执行完毕,说明消费者的数据都消费完毕了
这个时候主进程中的p1.join结束
主进程的代码结束
守护进程也结束了
进程池*****
pool 池
什么是池?
固定的几个进程 执行无限的任务
务,只有5个任务能同时执行
100个任务需要交替执行20次才能被5个进程执行
什么是进程池:
有限的进程的池子
为什么要有进程池:
任务很多 cpu个数*5个任务以上
为了节省创建和销毁进程的时间 和 操作系统的资源# cpu的1-2倍
一般进程池中进程的个数:
cpu的1-2倍
如果是高计算,完全没有io,那么就用cpu的个数
随着IO操作越多,可能池中的进程个数也可以相应增加
向进程池中提交任务的三种方式
map 异步提交任务 简便算法 接收的参数必须是 子进程要执行的func,可迭代的(可迭代中的每一项都会作为参数被传递给子进程)
能够传递的参数是有限的,所以比起apply_async限制性比较强
apply 同步提交任务(你删了吧)
apply_async 异步提交任务
能够传递比map更丰富的参数,但是比较麻烦
首先 apply_async提交的任务和主进程完全异步
可以通过先close进程池,再join进程池的方式,强制主进程等待进程池中任务的完成
也可以通过get获取返回值的方式,来等待任务的返回值
我们不能在apply_async提交任务之后直接get获取返回值
for i in range(100):
ret = p.apply_async(func,args=(i,)) # 自动带join 异步的 apply_async异步提交任务
l.append(ret)
for ret in l:
print(ret.get())
进程池和进程的区别:
一个进程,一个任务,每一个任务都需要操作系统分配资源创造进程,然后才能开始工作,任务结束之后,还要回收资源
多进程的时间开销
多进程的时间开销 100
创建0.1/销毁进程0.1所需要的时间 0.1*100=10 + 0.1*100+10 = 20s
在多个进程之间切换 也需要时间开销
进程占不占用资源
进程在计算机中占用的资源是相对多的
import tim
from multiprocessing import Process
def func(i):
i -= 1
if __name__ == '__main__':
start = time.time()
l = []
for i in range(100):
p = Process(target=func,args=(i,))
p.start()
l.append(p)
for p in l:
p.join()
print(time.time() - start)
池
import os import time from multiprocessing import Pool # 池
def func(i): i -= 1 if __name__ == '__main__':
start = time.time() p = Pool(5) #你的池中打算放多少个进程,个数cpu的个数 * 1|2 p.map(func,range(100)) # 自动带join print(time.time() - start)
有了进程池,不仅可以只开有限的进程来完成无限的任务
还可以获取程序执行的返回值
import os
import time
from multiprocessing import Pool # 池
def func(i):
i -= 1
return i**2
你的池中打算放多少个进程,个数cpu的个数 * 1|2
if __name__ == '__main__':
p = Pool(5)
ret = p.map(func,range(100)) # 自动带join
print(ret)
同步方式向进程池提交任务
import time
from multiprocessing import Pool # 池
def func(i):
i -= 1
time.sleep(0.5)
return i**2
你的池中打算放多少个进程,个数cpu的个数 * 1|2
if __name__ == '__main__':
p = Pool(5)
for i in range(100):
ret = p.apply(func,args=(i,)) # 自动带join 串行 同步 apply就是同步提交任务
print(ret)
异步方式向进程池提交任务
import time
from multiprocessing import Pool # 池
def func(i):
i -= 1
time.sleep(0.1)
print(i)
return i**2
你的池中打算放多少个进程,个数cpu的个数 * 1|2
if __name__ == '__main__':
p = Pool(5)
for i in range(100):
ret = p.apply_async(func,args=(i,)) # 自动带join 异步的 apply_async异步提交任务
p.close() # 关闭进程池的任务提交 从此之后不能再向p这个池提交新的任务
p.join() # 阻塞 一直到所有的任务都执行完
异步方式向进程池提交任务并且获取返回值
import time
from multiprocessing import Pool # 池
def func(i):
i -= 1
time.sleep(1)
return i**2
你的池中打算放多少个进程,个数cpu的个数 * 1|2
if __name__ == '__main__':
p = Pool(5)
l = []
for i in range(100):
ret = p.apply_async(func,args=(i,)) # 自动带join 异步的 apply_async异步提交任务
l.append(ret)
for ret in l:
print(ret.get())
回调函数:
import os
import time
import random
from multiprocessing import Pool # 池
def func(i): # [2,1,1,5,0,0.2]
i -= 1
time.sleep(random.uniform(0,2))
return i**2
def back_func(args):
print(args,os.getpid())
if __name__ == '__main__':
print(os.getpid())
p = Pool(5)
l = []
for i in range(100):
ret = p.apply_async(func,args=(i,),callback=back_func) # 5个任务
p.close()
p.join()
callback回调函数
主动执行func,然后在func执行完毕之后的返回值,直接传递给back_func作为参数,调用back_func
处理池中任务的返回值
回调函数是由谁执行的? 主进程
爬虫练习
import re
import json
from urllib.request import urlopen
from multiprocessing import Pool
def get_page(i):
ret = urlopen('https://movie.douban.com/top250?start=%s&filter='%i).read()
ret = ret.decode('utf-8')
return ret
def parser_page(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)
ret = com.finditer(s)
with open('file','a',encoding='utf-8') as f:
for i in ret:
dic = {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
}
f.write(json.dumps(dic,ensure_ascii=False)+'
')
if __name__ == '__main__':
p = Pool(5)
count = 0
for i in range(10):
p.apply_async(get_page,args=(count,),callback=parser_page)
count += 25
p.close()
p.join()
import json
with open('file2','w',encoding='utf-8') as f:
json.dump({'你好':'alex'},f,ensure_ascii=False)