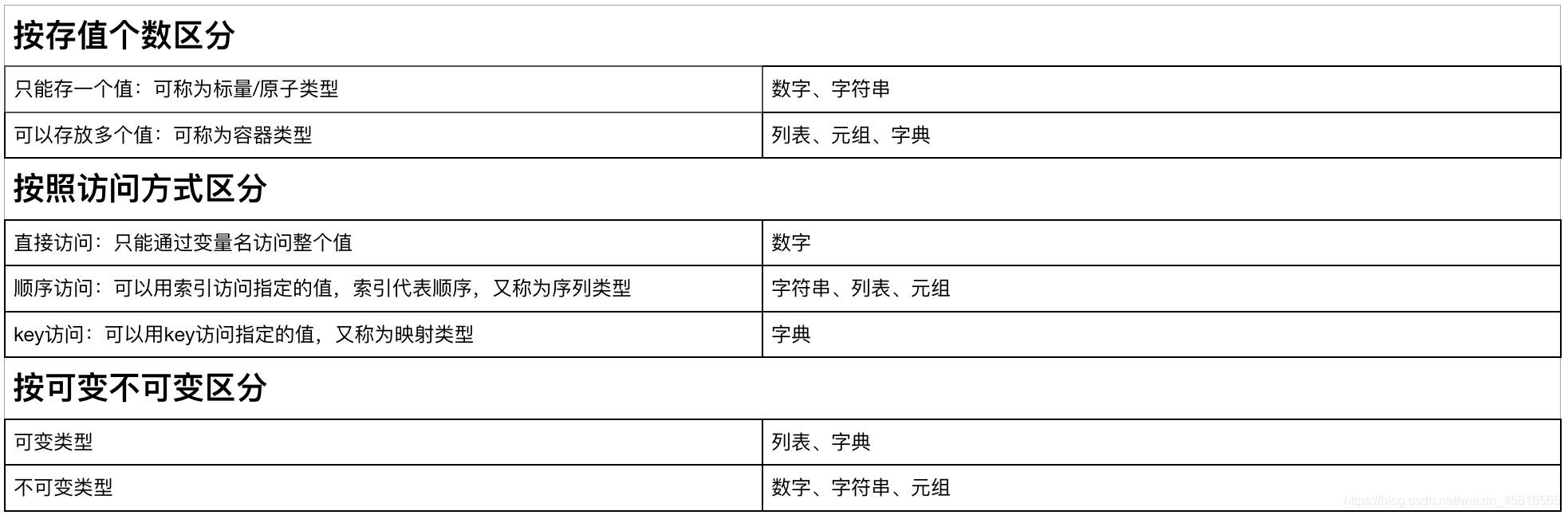
一、运行python程序的两种方式:
方式一:交互式模式
方式二:脚本文件
交互式模式下可以即时得到代码执行结果,调试程序十分方便。
若想将代码永久保存下来,则必须将代码写入文件中。
若将代码写入文件中,偶尔需要打开交互式模式调试某段代码、验证结果。
二、变量
1、什么是变量
变:变化
量:指的是事物的状态
变量:是一种可以反映出状态变化的一种机制,比如人的年龄,性别,等级,金钱等
2、为什么要有变量
为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的,程序执行的本质就是一系列状态的变化
3、如何定义变量
level = 0
level = 1
name = "Bob"
变量的命名规范?
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 关键字不能声明为变量名
- 变量名不能为中文
变量的三大特性:
值:value
内存地址:id
变量的类型:type
三、常量
常量是指在程序运行过程中不会改变的量,在python中没有一个专门的语法定义常量,约定俗成是用全部大写的变量名表示常量。如:PAI=3.14。所以单从语法层面去讲,常量的使用与变量完全一致。
四、与用户交互
与用户交互就是人往计算机中input/输入数据,计算机print/输出结果,为了让计算机能够像人一样与用户沟通交流
user_name = input('请输入您的用户名:')
print(user_name)
input():接受用户的输入,把用户输入的内容都转化成字符串
在python3中:
input() #把用户输入的内容全部都存为字符串类型
在python2中:
raw_input() #把用户输入的内容全部都存为字符串类型
input()#必须输入明确的数据类型,输入什么就存成什么类型
五、格式化输出
定义:就是把一段字符串里面的某些内容替换掉之后再输出。
%s 占位符:可以接受任意类型的值
%d 占位符:只能接受整数类型
# 按照顺序传值
name = input('your name:')
age = input('your age:')
print('my name is %s,my age is %s' %(name,age))
print('my name is %s,my age is %s' %('egon',18))
#format
name = input('your name:')
age = input('your age:')
print("my name is {},my age is {}".format(name,age))
print('my name is {name},my age is {age}'.format(name=name,age=age))
#f'{}'
print(f'my name is {name},my age is {age}')
六、基本数据类型
1.整型int
用途:年龄,等级,号码
#定义方式:
age = 10 #age = int(10)
2.浮点型float
用途:身高,体重,薪资
定义方式:
height =1.81 #height =float(1.81)
#十进制转其他进制
print(bin(3)) #ob11 十进制转二进制
print(oct(8)) #0o10 十进制转八进制
print(hex(16)) #0x10 十进制转十六进制
3.字符串类型str
用来表示名字、年龄等描述性的信息(数据)
定义方式:
str:包含在引号内的一串字符
# 字符串拼接(+,*)是开辟一个新的内存空间,将你拼接之后的值存进去
s1 = 'hello '
s2 = 'world'
print(s1 + s2) #hello world
print(s1*3) #hello hello hello
常用操作+内置方法:
优先掌握的操作:
1、按索引取值(正向取+反向取): **只能取不能改**
name = "baohan"
print(name[0]) #正向取
print(name[-1]) #反向取
print(type(name[-1])) #<class 'str'>
2、切片(顾头不顾尾,默认步长为1)
msg = "my name is Bob"
print(msg[0:6])
print(msg[0:6:2]) #m a
#了解:
#print(msg[0:5:1])
#print(msg[3:1,-1])
#print(msg[-1:-5:-1])
msg = 'alex is sb'
print(msg[0:]) #取全部
print(msg[::-1]) #顺序全部倒过来
3、长度len():获取当前数据中元素的个数
msg = 'my name is Bob'
print(len(msg)) #字符的个数
4、成员运算in 和 not in
msg = 'my name is Bob'
print("my"in msg) #True
print("name" not in msg) #False
5、循环 for循环适用于字符串,列表,字典,元组,集合
msg = 'alex is sb'
#for i in msg:
#print(i)
i = 0
while i < len(msg):
print(msg[i])
i+=1
6、strip():移除空白
name = input ('你的用户名:').strip()
print(name)
7、split():对字符串进行切分,可以指定切分的分隔符,返回的是一个列表
info = 'bob:123:admin'
res = info.split(':')
print(res,type(res)) #切完是列表类型
print(res[0]) #bob
需要掌握的操作:
1、 strip,lstrip,rstrip
print('**sss*****'.strip("*")) #移除两边的*
print('**sss*****'.lstrip("*")) #移除右边的*
2、lower,upper:转字符串里字符的大小写
name1 = "egon"
name2 = "ALEX"
print(name1.upper())
print(name2.lower())
3、startswith,endswith 判断字符串是否以括号内指定的字符开头、结尾,返回的是布尔值True或False
info = "my name is bob"
print(info.startswith('m'))
print(info.startswith('my'))
print(info.endswith('b'))
4、format的三种用法
1)类似于%s的用法,传入的值与{}一一对应
s1 = "my name is {},my age is {}".format("bob",18,19)
print(s1)
2)把format传入的多个值当作一个列表,然后用{索引}取值
s2 = "my name is {0},my age is {1}".format("bob",18)
print(s2)
3)format括号内传参数可以完全打乱顺序,但根据键值对传入指定参数
s3 = "my name is {name},my age is {age}".format(name="bob",age=18)
print(s3)
5、split,rsplit
info = "get|bob|hobby"
print(info.split("|")) #默认从左边开始切分
print(info.split("|",1)) #可以指定切分的次数
print(info.rsplit("|",1)) #从右边开始切分
6、join 将(列表)中每个元素按照""里的内容为分隔符号进行拼接(传入的列表内只能是字符串)
l1 = ['get', 'bob', 'hobby']
print("+".join(l1)) #get+bob+hobby
7、f-string:通过大括号接受变量,在字符串前面一定要加一个小写的f,在python3.6以后才有
8、replace 将字符串中的元素进行替换
info = "my name is egon,egon is handsome"
print(info.replace('egon','bob'))
print(info.replace('egon','bob',1)) #语法:replace('旧内容','新内容',修改的个数)
9、isdigit 判断字符串是否是整型,返回结果为布尔值
age = "18"
print(age.isdigit()) #True
age = "19.1"
print(age.isdigit()) #False
print('sdaw'.isdigit()) #False
inp = input(">>>:")
if inp.isdigit():
inp = int(inp)
if inp == 10:
print("right")
else:
print("输入格式错误")
了解的知识点:
# 1、find:查找当前字符串中某个元素的位置,返回索引,找不到返回-1
msg='tony say hello'
msg.find('o',1,3) # 在索引为1和2(顾头不顾尾)的字符中查找字符o的索引
# 2、index:同find,但在找不到时会报错
msg.index('e',2,4) # 报错ValueError
# 3、rfind与rindex:略
# 4、count:统计当前字符串中某一个元素出现的次数
msg = "hello everyone"
msg.count('e') # 统计 e 出现的次数
# 5、center居中对齐,ljust左对齐,rjust右对齐,zfill填充0
name='tony'
name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充
>>>-------------tony-------------
name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充
>>>tony**************************
name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充
>>>**************************tony
name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充
>>>0000000000000000000000000000000000000000000000tony
#6、expandtabs
msg='abc def' #制表符
print(msg.expandtabs(3))
#7、captalize():只有首字母是大写
#8、swapcase():大小写反转
#9、title():每个单词的首字母大写
#10、is数字系列
#在python3中
num1 = b'4' #bytes
num2 = u'4' #unicode,python3中无需加u就是unicode
num3 = '四' #中文数字
num4 = 'Ⅳ' #罗马数字
num1.isdigit() #True
num2.isdigit() #True
num3.isdigit() #False
num4.isdigit() #False
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字或unicode,则需要用到isnumeric
isdecimal:只能用来判断unicode
#11 is其他
name = 'tony123'
name.isalpha(): #字符全由字母组成
>>> True
name.isalnum(): #字符由字母或数字组成
>>> True
name.islower() # 字符串是否是纯小写
>>> True
name.isupper() # 字符串是否是纯大写
>>> False
name.isspace() # 字符串是否全是空格
>>> False
name.istitle() # 字符串中的单词首字母是否都是大写
>>> False
字符串中的转义字符:
字符串前面加一个小写的r,代表转义
print(r'hello
world')
输入一个 制表符,协助在输出文本时垂直方向保持对齐
print("1 2 3")
print("10 20 30")
换行符
" 可以输出一个"
\ 就表示一个
4.列表list:
列表:定义在[ ]中括号内,用逗号分隔开多个值,值可以是任意类型
用来存放多个值
类型转换:
但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
>>> list('wdad') # 结果:['w', 'd', 'a', 'd']
>>> list([1,2,3]) # 结果:[1, 2, 3]
>>> list({"name":"jason","age":18}) #结果:['name', 'age']
>>> list((1,2,3)) # 结果:[1, 2, 3]
>>> list({1,2,3,4}) # 结果:[1, 2, 3, 4]
常用操作:
1、索引取值:(正反都可以取,即可存也可取)
user_info = ['egon',18,['football','eat','sleep']]
print(user_info[2][0])
>>> football
2、索引切片 切出来的也是列表
my_friends = ['tony', 'jason', 'tom', 4]
print(my_friends[0:4:2]) #第三个参数2代表步长
>>>['tony', 'tom']
3、长度len(): 获取列表中元素的个数
my_friends = ['tony', 'jason', 'tom', 4]
len(my_friends)
>>>4
4、成员运算in和not in
my_friends = ['tony', 'jason', 'tom', 4]
'tony' in my_friends
>>>True
'egon' in my_friends
>>>False
5、循环 #循环遍历my_friends列表里面的值
#依赖索引
stus = ['bob','alex','egon']
i = 0
while i <len(stus):
print(stus[i])
i+=1
#不依赖于索引
for i in my_friends:
print(i)
内置方法:
1、添加
# append(): 列表尾部追加值,一次性只能添加一个值
l1 = ['a','b','c']
l1.append('d')
print(l1)
>>>['a', 'b', 'c', 'd']
# insert(): 插入值,通过索引指定插入的位置
l1 = ['a','b','c']
l1.insert(0,"first") # 0表示按索引位置插值
print(l1)
>>>['first', 'a', 'b', 'c']
# extend(): 一次性在列表尾部添加多个元素
l1 = ['a','b','c']
l1.extend(['a','b','c'])
print(l1)
>>>['a', 'b', 'c', 'a', 'b', 'c']
2、删除
2.1 remove():删除指定的值,只能删一个,没有返回值
l = [11,22,33,22,44]
res=l.remove(22) # 从左往右查找第一个括号内需要删除的元素
print(res)
>>>None
2.2 pop()默认从列表最后一个元素开始删,并将删除的值返回,括号内可以通过加索引值来指定删除元素
l = [11,22,33,22,44]
res=l.pop()
print(res)
>>>44
res=l.pop(1)
print(res)
>>>22
2.3 del 彻底删除
l = [11,22,33,44]
del l[2] # 删除索引为2的元素
print(l)
>>>[11,22,44]
3、reverse()颠倒列表内元素顺序
l = [11,22,33,44]
l.reverse()
print(l)
>>>[44,33,22,11]
4、sort()给列表内所有元素排序,排序时,列表元素之间必须是相同数据类型,不可混搭,否则报错
# 默认从小到大排序
# 大前提:只能同类型直接比较大小,对于有索引值的直接比较是按照位置一一对应进行比较的
l = [11,22,3,42,7,55]
l.sort()
print(l)
>>>[3, 7, 11, 22, 42, 55]
l = [11,22,3,42,7,55]
l.sort(reverse=True) # reverse用来指定是否跌倒排序,默认为False
print(l)
>>> [55, 42, 22, 11, 7, 3]
5、sorted():python的内置函数,在排序时生成一个新列表,原数据不变
6、count():统计当前列表内指定元素的个数
l = [11,22,3,42,7,55,11]
print(l.count(11))
>>>2
7、index():获取当前指定元素的索引值,还可以指定查找范围
l = [11,22,3,42,7,55,11]
print(l.index(11,1,7))
>>>6
8、clear():清空列表数据
l = [11,22,3,42,7,55,11]
l.clear()
print(l)
>>>[]
补充知识点:
#队列:先进先出
l1 =[]
l1.append(1)
l1.append(2)
l1.append(3)
print(l1)
l1.pop(0)
print(l1)
l1.pop(0)
l1.pop(0)
print(l1)
#堆栈:先进后出
l1 =[]
l1.append(1)
l1.append(2)
l1.append(3)
print(l1)
l1.pop()
print(l1)
l1.pop()
l1.pop()
print(l1)
5.字典dict:
定义:通过{ }来存储数据,通过key:value来定义键值对数据,每个键值对中间用逗号分隔开,其中value可以是任意类型,而key一定要是不可变类型(数字,字符串)。
字典的三种定义方式:
1、d1 = {'name':'bob','age':18}
2、d2 = dict({'name':'bob'})
3、#了解 zip:
l1 = ['name','bob']
l2 = ['age','18']
z1 = zip(l1,l2)
print(dict(z1))
常用方法:
1.1、按照key:value映射关系取值(可存可取)
user_info = {'name':'egon','age':18,'hobbies':['football','eat','sleep']}
print(user_info['age'])
>>>18
print(user_info['hobbies'][0])
>>>football
1.2、赋值:如果key原先不存在于字典,则会新增key:value
dic = {'name':'egon'}
dic['age'] = 18
print(dic)
>>>{'name': 'egon', 'age': 18}
1.3 赋值:如果key原先存在于字典,则会修改对应value的值
dic = {'name':'egon','age':18}
dic['name'] = 'tony'
print(dic)
>>>{'name': 'tony', 'age': 18}
2、成员运算:in , not in #默认判断某个值是否为字典的key
user_info = {'name':'egon','age':18}
print("name" in user_info)
>>>True
3、len():#获取当前字典中键值对的个数
user_info = {'name':'egon','age':18}
print(len(user_info))
>>>2
4、for循环
4.1 默认遍历的是字典的key
for key in user_info:
print(key)
>>>name
>>>age
4.2 只遍历key
for i in user_info.keys():
print(i)
>>>name
>>>age
4.3 只遍历value
user_info ={'name':'egon','age':18}
for i in user_info.values():
print(i)
>>>egon
>>>18
4.4 遍历key和value
for i in user_info.items():
print(i)
内置方法:
1、keys,values,items
dic= {'k1':'jason','k2':'Tony','k3':'JY'}
print(dic.keys()) #返回所有的key
print(dic.values()) #返回所有的value
print(dic.items()) #返回一个可迭代对象,是列表套元组的形式,每一个键值对都是一个元组
>>>dict_keys(['k1', 'k2', 'k3'])
>>>dict_values(['jason', 'Tony', 'JY'])
>>>dict_items([('k1', 'jason'), ('k2', 'Tony'), ('k3', 'JY')])
2、get():获取指定key的值,如果值不存在,默认返回None,可以通过第二个参数修改默认返回的值
dic= {'k1':'jason','k2':'Tony','k3':'JY'}
dic.get('k1')
>>> 'jason'
res=dic.get('xxx') # key不存在,不会报错而是默认返回None
print(res)
>>> None
res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
print(res)
>>> 666
# ps:字典取值建议使用get方法
3、pop():删除指定key对应的键值对,有返回值,返回为对应的value
dic= {'k1':'jason','k2':'Tony','k3':'JY'}
v =dic.pop('k2') # 删除指定的key对应的键值对,并返回值
print(dic)
>>> {'k1': 'jason', 'k3': 'JY'}
print(v)
>>> 'Tony'
4、popitem(): 随机删除一组键值对,并将删除的键值放到元组内返回
dic= {'k1':'jason','k2':'Tony','k3':'JY'}
item = dic.popitem()
print(dic)
>>> {'k3': 'JY', 'k2': 'Tony'}
print(item)
>>> ('k1', 'jason')
>
5、update():用新字典更新旧字典,有则修改,无则添加
dic= {'k1':'jason','k2':'Tony','k3':'JY'}
dic.update({'k1':'JN','k4':'xxx'})
print(dic)
>>>{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
6、fromkeys():生成一个新字典,第一个参数(列表),它会以第一个参数中的各个元素为key,以第二个参数为值,组成一个新字典
dic = dict.fromkeys(['k1','k2','k3'],'egon')
print(dic)
>>>{'k1':'egon', 'k2':'egon', 'k3':'egon'}
7、setdefault():
若key不存在,新增键值对,有返回值,返回新增value。
dic={'k1':111,'k2':222}
res=dic.setdefault('k3',333)
print(res)
>>>333
print(dic)
>>>{'k1': 111, 'k2': 222, 'k3': 333}
若key存在则不做任何修改,并返回已存在key对应的value值
dic={'k1':111,'k2':222}
res=dic.setdefault('k1',666)
res
>>> 111
dic # 字典不变
>>> {'k1': 111, 'k2': 222}
6.元组
元组就是一个不可变的列表
用途:存储多个不同类型的值,只有读的需求,没有改的需求
定义方式:用小括号存储数据,数据之间通过逗号分隔(值不能被改变)
t1 = ('a','b') # t1 = tuple(('a','b'))
强调:如果元组内只有一个值,则必须加一个逗号
常用方法:
1、按索引取值(正向取+反向取):只能取,不能改,否则报错!
tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
tuple1[0]
>>> 1
tuple1[-2]
>>> 22
tuple1[0] = 'hehe' # 报错:TypeError:
2、切片(顾头不顾尾,步长)
tuple1[0:6:2]
>>> (1, 15000.0, 22) #切出来的还是元组
3、长度
len(tuple1)
>>> 6
4、成员运算 in 和 not in
tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
print('hhaha' in tuple1)
print('hhaha' not in tuple1)
5、count()
tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
print(tuple1.count(11))
>>>1
# 6、index()
tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
print(tuple1.index('hhaha'))
>>>1
7.集合
用途:去重、关系运算
定义:在{ }内用逗号分隔开多个元素
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素是无序的
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
注意2:{ }既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
默认是空字典: d = {}
定义空集合: s = set()
关系运算:
friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
1.合集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
5.值是否相等(==)
>>> friends1 == friends2
False
6.父集:一个集合是否包含另外一个集合
6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
去重:
集合去重复有局限性:
1. 只能针对不可变类型
2. 集合本身是无序的,去重之后无法保留原来的顺序
例如:
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for i in l:
if i not in new_l:
new_l.append(i)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
#打印结果:
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
8.布尔类型(True,False)
用途:判断
重点:所有数据类型自带布尔值,等号比较的是值,is比较的是地址
0,
None,
空:"",[],{}的值为False
其余全部为真
七、可变类型与不可变类型
可变:值改变的情况下,id不变
不可变:值一变,id就变
不可变类型:数字,字符串,元组
可变类型:列表,字典,集合
x =1
print(id(x),x)
x =2
print(id(x),x)
# >>>140736221442320 1
# >>>140736221442352 2
#
x="abc"
print(id(x),x)
x="bcd"
print(id(x),x)
# >>>2291351178288 abc
# >>>2291351217840 bcd
x=['a','b','c']
print(id(x),type(x),x)
x[2]=10
print(x)
print(id(x),type(x),x)
# >>>1887760765512 <class 'list'> ['a', 'b', 'c']
# >>>['a', 'b', 10]
# >>>1887760765512 <class 'list'> ['a', 'b', 10]
dic={'x':1,'y':2}
print(id(dic),type(dic),dic)
dic['x']=111111111
print(dic)
print(id(dic),type(dic),dic)
# >>>1571299274008 <class 'dict'> {'x': 1, 'y': 2}
# >>>{'x': 111111111, 'y': 2}
# >>>1571299274008 <class 'dict'> {'x': 111111111, 'y': 2}
八、基本运算符
1.算数运算符
//:取整
%:取余数
**:次幂
2.比较运算符
!= 不等于
3.赋值运算符
1)增量赋值: += //= %= 等等
2)链式赋值: x = y = z = 1
3)交叉赋值:m = 10 ,n = 20
m,n=n,m
4)解压赋值:
l1=[1,2,3,4]
a,b,c,d=l1
print(a,b,c,d)
>>>(1,2,3,4)
l1 =[1,2,3,4]
a,b,*_=l1
print(a,b)
>>>(1,2)
4.逻辑运算
与 或 非
and or not
逻辑运算符的优先级顺序:not,and,or
a = 1
b = 2
c = 3
print(a < b and b > c) # and:如果有一个式子不符合条件,整条式子都为False
print(a > b and b < c)
print(a < b or b < c) # or:只要有一个式子符合条件,整条式子都为True
print(a > b or b < c)
print(not a < b) # 取反
print(a < b and b < c or a > c) # True
print(a > b or b < c and a > c) # False
九:进制转换
十进制转成其他进制
bin(3): ob11 #十进制转二进制
oct(8): oc10 #十进制转八进制
hex(16) ox10 #十进制转十六进制
其他进制转换成十进制
二进制转成十进制
print(int('110',2)) #第二个参数是第一个参数的进制
八进制转成十进制
print(int('110',8))
十、什么是垃圾回收机制?
垃圾回收机制(简称GC)是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间
引用计数:当内存中的值引用计数为0,垃圾回收机制就会自动清除变量值