1) Java中什么是竞态条件? 举个例子说明。
竞态条件会导致程序在并发情况下出现一些bugs。多线程对一些资源的竞争的时候就会产生竞态条件,如果首先要执行的程序竞争失败排到后面执行了, 那么整个程序就会出现一些不确定的bugs。这种bugs很难发现而且会重复出现,因为线程间的随机竞争。一个例子就是无序处理
竞态条件(Race Condition):计算的正确性取决于多个线程的交替执行时序时,就会发生竞态条件。
最常见的竞态条件为:
一,先检测后执行。执行依赖于检测的结果,而检测结果依赖于多个线程的执行时序,而多个线程的执行时序通常情况下是不固定不可判断的,从而导致执行结果出现各种问题。

对于main线程,如果文件a不存在,则创建文件a,但是在判断文件a不存在之后,Task线程创建了文件a,这时候先前的判断结果已经失效,(main线程的执行依赖了一个错误的判断结果)此时文件a已经存在了,但是main线程还是会继续创建文件a,导致Task线程创建的文件a被覆盖、文件中的内容丢失等等问题。
多线程环境中对同一个文件的操作要加锁。
和大多数并发错误一样,竞态条件不总是会产生问题,还需要不恰当的执行时序
2)Java中有哪些实现并发编程的方法
1. synchronized关键字
2. 使用继承自Object类的wait、notify、notifyAll方法
3. 使用线程安全的API和集合类:
- 使用Vector、HashTable等线程安全的集合类
- 使用Concurrent包中提供的ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue等弱一致性的集合类
- 在Collections类中有多个静态方法,它们可以获取通过同步方法封装非同步集合而得到的集合,如List list = Collection.synchronizedList(new ArrayList())。
4. 使用原子变量、volatile变量等
5. 使用Concurrent包中提供的信号量Semaphore、闭锁Latch、栅栏Barrier、交换器Exchanger、Callable&Future、阻塞队列BlockingQueue等.
6. 手动使用Lock实现基于锁的并发控制
7. 手动使用Condition或AQS实现基于条件队列的并发控制
8. 使用CAS和SPIN等实现非阻塞的并发控制
3)进程间通信的几种方式
1. 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2. 有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
3. 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4. 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6. 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
7. 套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
4)ConcurrentHashMap
ConcurrentHashMap是线程安全的HashMap,内部采用分段锁来实现,默认初始容量为16,装载因子为0.75f,分段16,每个段的HashEntry<K,V>[]大小为2。键值都不能为null。每次扩容为原来容量的2倍,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。在获取size操作的时候,不是直接把所有segment的count相加就可以可到整个ConcurrentHashMap大小,也不是在统计size的时候把所有的segment的put, remove, clean方法全部锁住,这种方法太低效。在累加count操作过程中,之前累加过的count发生变化的几率非常小,所有ConcurrentHashMap的做法是先尝试2(RETRIES_BEFORE_LOCK)次通过不锁住Segment的方式统计各个Segment大小,如果统计的过程中,容器的count发生了变化,再采用加锁的方式来统计所有的Segment的大小。
5)ABA问题
ABA问题发生在类似这样的场景:线程1转变使用CAS将变量A的值替换为C,在此时,线程2将变量的值由A替换为C,又由C替换为A,然后线程1执行CAS时发现变量的值仍为A,所以CAS成功。但实际上这时的现场已经和最初的不同了。大多数情况下ABA问题不会产生什么影响。如果有特殊情况下由于ABA问题导致,可用采用AtomicStampedReference来解决,原理:乐观锁+version。可以参考下面的案例来了解其中的不同


1 public class ABAQuestion 2 { 3 private static AtomicInteger atomicInt = new AtomicInteger(100); 4 private static AtomicStampedReference<Integer> atomicStampedRef = new AtomicStampedReference<Integer>(100,0); 5 6 public static void main(String[] args) throws InterruptedException 7 { 8 Thread thread1 = new Thread(new Runnable(){ 9 @Override 10 public void run() 11 { 12 atomicInt.compareAndSet(100, 101); 13 atomicInt.compareAndSet(101, 100); 14 } 15 }); 16 17 Thread thread2 = new Thread(new Runnable(){ 18 @Override 19 public void run() 20 { 21 try 22 { 23 TimeUnit.SECONDS.sleep(1); 24 } 25 catch (InterruptedException e) 26 { 27 e.printStackTrace(); 28 } 29 boolean c3 = atomicInt.compareAndSet(100, 101); 30 System.out.println(c3); 31 } 32 }); 33 34 thread1.start(); 35 thread2.start(); 36 thread1.join(); 37 thread2.join(); 38 39 Thread thread3 = new Thread(new Runnable(){ 40 @Override 41 public void run() 42 { 43 try 44 { 45 TimeUnit.SECONDS.sleep(1); 46 } 47 catch (InterruptedException e) 48 { 49 e.printStackTrace(); 50 } 51 atomicStampedRef.compareAndSet(100, 101, atomicStampedRef.getStamp(), atomicStampedRef.getStamp()+1); 52 atomicStampedRef.compareAndSet(101, 100, atomicStampedRef.getStamp(), atomicStampedRef.getStamp()+1); 53 } 54 }); 55 56 Thread thread4 = new Thread(new Runnable(){ 57 @Override 58 public void run() 59 { 60 int stamp = atomicStampedRef.getStamp(); 61 try 62 { 63 TimeUnit.SECONDS.sleep(2); 64 } 65 catch (InterruptedException e) 66 { 67 e.printStackTrace(); 68 } 69 boolean c3 = atomicStampedRef.compareAndSet(100, 101, stamp, stamp+1); 70 System.out.println(c3); 71 } 72 }); 73 thread3.start(); 74 thread4.start(); 75 } 76 }
输出结果:
true false
6)servlet是线程安全的吗
Servlet不是线程安全的。要解释为什么Servlet为什么不是线程安全的,需要了解Servlet容器(即Tomcat)是如何响应HTTP请求的。
当Tomcat接收到Client的HTTP请求时,Tomcat从线程池中取出一个线程,之后找到该请求对应的Servlet对象并进行初始化,之后调用service()方法。要注意的是每一个Servlet对象在Tomcat容器中只有一个实例对象,即是单例模式。如果多个HTTP请求请求的是同一个Servlet,那么着两个HTTP请求对应的线程将并发调用Servlet的service()方法。
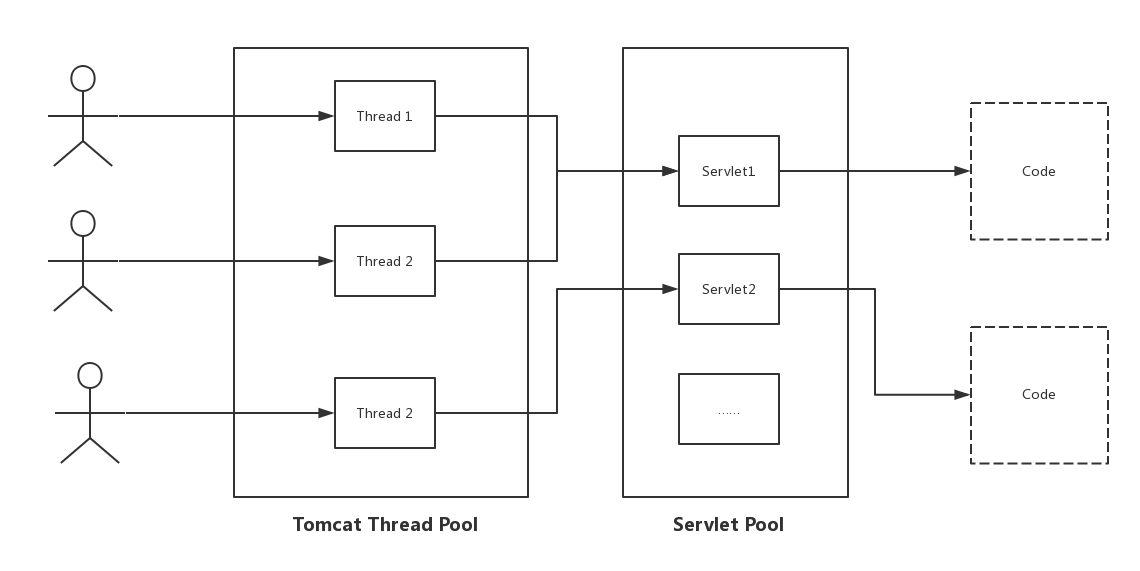
比如下面的Servlet中的 name 和 i变量就会引发线程安全问题。
import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Date; public class ThreadSafeServlet extends HttpServlet { public static String name = "Hello"; //静态变量,可能发生线程安全问题 int i; //实例变量,可能发生线程安全问题 SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); @Override public void init() throws ServletException { super.init(); System.out.println("Servlet初始化"); } @Override protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { System.out.printf("%s:%s[%s] ", Thread.currentThread().getName(), i, format.format(new Date())); i++; try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.printf("%s:%s[%s] ", Thread.currentThread().getName(), i, format.format(new Date())); resp.getWriter().println("<html><body><h1>" + i + "</h1></body></html>"); } }
9)linux/unix下统计一行字符串出现指定字符的次数

一种方案: 先把 | 替换成换行符,wc -l 统计时候的的数量就一定是result + 1 最后把1减掉
unix系统用 sed 's/|/ /g' 无法替换(linux 可以),所以考虑用tr替换
echo $(echo "10.1.4.90|15/Jan/2018:08:44:38|GET|pi.easyond/|" | tr '|' ' ' | wc -l)-1 | bc
10)快速失败(fail - fast)和安全失败(fail - safe)
一 快速失败 fail-fast
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加,删除,修改), 则会抛出 ConcurrentModificationException
原理: 迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值,每当迭代器使用hasNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedModCount值,是的话就返回遍历,否则抛出异常,终止遍历。
下面以AbstractList的实现举例,其他原理同,不再累述


注意:这里异常的抛出条件是检测到this.modCount != l.modCount, 如果集合发生变化时又恰好修改了modCount的值使上述条件语句满足,那么异常不会抛出。因此,不能依赖这个异常是否抛出的逻辑进行并发操作的编程,这个异常只建议用于检测并发修改的bug
场景 java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)
二 安全失败 fail-safe
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历
原理: 由于迭代时时对原集合的拷贝进行遍历,所以在遍历过程中对原集合所做的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException
缺点: 基于拷贝内容的优点是避免了ConcurrentModificationException,但相对地,迭代器并不能访问到修改后的内容。即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器无从得知。
场景: java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
11)mysql的undo和redo
12)cookie和session
13)网站短链接生成算法
https://www.zhihu.com/question/2927003414)linux下kill -9 pid强制不能杀掉进程原因
b、 该进程处于"kernel mode"(核心态)且在等待不可获得的资源。处于核心态的进程忽略所有信号处理,因此对于这些一直处于核心态的进程只能通过重启系统实现。进程在AIX 中会处于两种状态,即用户态和核心态。只有处于用户态的进程才可以用“kill”命令将其终止。
用top命令查看发现zombie进程数是0,看来这三个进程不属于僵尸进程,应该是b这中情况,就是这些进程进入核心态等待磁盘资源时出现磁盘空间不足的故障,这时我强制关闭了数据库,所以这几个进程就一直处于核心态无法被杀除,看来只能重启了。
15)给定a,b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如果找出a,b文件共同的url
思路:可以估计每个文件的大小为5G*64=300G,远大于4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。 遍历文件a,对每个url求取hash(url)%1000,然后根据所得值将url分别存储到1000个小文件(设为a0,a1,...a999)当中。这样每个小文件的大小约为300M。遍历文件b,采取和a相同的方法将url分别存储到1000个小文件(b0,b1....b999)中。这样处理后,所有可能相同的url都在对应的小文件(a0 vs b0, a1 vs b1....a999 vs b999)当中,不对应的小文件(比如a0 vs b99)不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 比如对于a0 vs b0,我们可以遍历a0,将其中的url存储到hash_map当中。然后遍历b0,如果url在hash_map中,则说明此url在a和b中同时存在,保存到文件中即可。 如果分成的小文件不均匀,导致有些小文件太大(比如大于2G),可以考虑将这些太大的小文件再按类似的方法分成小小文件即可
16)100亿个url中的重复url已经搜索词汇的topK问题
有一个包含100亿个URL的文件,假设每个URL占用64B,请找出其中所有重复的URL。
将文件通过哈希函数成多个小的文件,由于哈希函数所有重复的URL只可能在同一个文件中,在每个文件中利用一个哈希表做次数统计。就能找到重复的URL。这时候要注意的就是给了多少内存,我们要根据文件大小结合内存大小决定要分割多少文件
topK问题和重复URL其实是一样的,重复的多了才会变成topK。其实就是在上述方法后获得所有的重复URL排个序,但是有点没必要,因为我们要找topK时,最极端的情况也就是topK在用一个文件中,所以我们只需要每个文件的topK个URL,之后再进行排序,这样就比找出全部的URL再排序好。还有一个topK个URL到最后还是需要排序,所以我们在找每个文件的topK时,是否只需要找到topK个,其它顺序不用管,那么我们就可以用大小为K的小根堆遍历哈希表。这样又可以降低查找的时间。
17)如何判断服务器需要扩容
有很多指标,最基本的比如CPU利用率,内存占用率,网络带宽等。软件层面比如QPS等。
容量设计的时候需要考虑突发流量,一般要保留20%到30%的备用容量。
集群还要考虑灾备,比如部分机器发生故障的时候接负载均衡如何正确引流限流,避免雪崩式故障(cascading failure)。
至于工具的话,要看现有的技术框架。主要的目的就是做好实时监控和预警。
18)linux下如何查看进行占用CPU和内存的情况
1 ps
按内存大小排序(%MEM为第三列,%CPU为第二列,不在雷述)
ps -aux默认是按PID从小到大显示的,若想按占用内存大小排序则需要借助另外sort命令针对第4列(内存所在列)排序:
ps -aux | sort -k4rn
我们还可以借助awk来指定显示哪几列信息:
ps -aux |awk '{print $2, $4, $11}' | sort -k2rn | head -n 10
2 top
在命令行提示符执行top命令.输入大写P,则结果按CPU占用降序排序。输入大写M,结果按内存占用降序排序
20)Arrays.sort() 和Collections.sort() 底层是用什么排序
1 Arrays.sort()
public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); }
DualPivotQuicksort翻译过来就是双轴快速排序,再点进去发现有这样的判断
if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; }
可以发现如果数组的长度小于QUICKSORT_THRESHOLD的话就会使用这个双轴快速排序,而这个值是286。
那如果大于286,它会检测数组的连续上升/下降的特性好不好,好的话用归并排序,坏的话用快排
再回到上面的双轴快速排序,点进去
sort(int[] a, int left, int right, boolean leftmost)这个方法发现
如果数据长度小于INSERTION_SORT_THRESHOLD(值为47)的话,就会用插入排序
总结:
长度大于等于286且连续性好->归并
长度大于等于286且连续性不好->双轴快速排序
长度小于286且大于等于47->双轴快速排序
长度小于47->插入排序
2 Collections.sort()
一路点进去发现到了Arrays类中
public static <T> void sort(T[] a, Comparator<? super T> c) { if (c == null) { sort(a); } else { if (LegacyMergeSort.userRequested) legacyMergeSort(a, c); else TimSort.sort(a, 0, a.length, c, null, 0, 0); } }
会发现如果LegacyMergeSort.userRequested为true的话就会使用归并排序,可以通过下面代码设置为true
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");
不过方法legacyMergeSort的注释上有这么一句话,说明以后传统归并可能会被移除了。
/** To be removed in a future release. */
如果不为true的话就会用一个叫TimSort的排序算法。
21)Object中有哪些方法
public方法: getClass() hashCode() equals() toString() notify()系列 wait()系列
protected方法: clone() finalize()
private方法: registerNatives, 该方法作用是将不同平台c/c++实现的方法映射到java的native方法
private static native void registerNatives(); static { registerNatives(); }
22)jvm GC根节点的选择
java通过可达性分析来判断对象是否存活,基本思想是通过一系列称为"GC roots"的对象作为起始点,可以作为根节点的是:
(1) 虚拟机栈(栈帧中的本地变量表)中引用的对象
(2) 本地方法栈中JNI(即native方法)引用的对象
(3) 方法区中静态属性引用的对象
(4) 方法区中常量引用的对象
作为GC roots的节点主要在全局性的引用(例如常量或类静态属性)与执行上下文(例如栈帧中的本地变量表)中。
我个人理解: 想下java内存模型的5块,gc主要是收集堆和持久代,恰好对应栈分配的堆对象和静态&常量所申请的持久代
23)类加载主要步骤
- 加载 把 class 文件的二进制字节流加载到 jvm 里面
- 验证 确保 class 文件的字节流包含的信息符合当前 jvm 的要求 有文件格式验证, 元数据验证, 字节码验证, 符号引用验证等
- 准备 正式为类变量分配内存并设置类变量初始值的阶段, 初始化为各数据类型的零值
- 解析 把常量值内的符号引用替换为直接引用的过程
- 初始化 执行类构造器
()方法 - 使用 根据相应的业务逻辑代码使用该类
- 卸载 类从方法区移除
24)Class.forName和classloader的区别
java中class.forName()和classLoader都可用来对类进行加载。
class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
25)获取class类的四种方式
1.调用运行时类本身的.class属性
Class clazz = String.class;
2,通过运行时类的对象获取
Person p = new Person();
Class clazz = p.getClass();
3.通过Class的静态方法获取:体现反射的动态性
String className = “java.util.commons”;
Class clazz = Class.forName(className);
4.通过类的加载器
String className = “java.util.commons”;
ClassLoader classLoader = this.getClass().getClassLoader();
Class clazz = classLoader.loadClass(className);
26)String为什么是final的
final的出现是为了不想改变,而不想改变的理由有两点: 设计(安全)或者效率
1 设计安全
确保不会在子类中改变语义。如果有一个String的引用,它引用的一定是一个string对象,而不可能是其他类的对象
2 效率
设计成final,jvm不用对相关方法在虚函数表中查询,而直接定位到String类的相关方法,提高了执行效率
一旦创建是不能被修改的。字符串对象是不可改变的,那么它们可以共享
27)kafka等mq如何保证有序性
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
28)java对象引用方式 - 强引用,软引用,弱引用,虚引用
从jdk1.2版本开始,把对应的引用分为4种级别,由高到低分别为: 强引用 > 软引用 > 弱引用 > 虚引用.
(1) 强引用
这是最普遍的引用。当内存空间不足时,java虚拟机宁愿抛出OutOfMemoryError使程序异常终止,也不会随意回收具有强引用的对象来解决内存不足问题
(2) 软引用
软引用在内存空间足够时,垃圾回收器不会进行回收。但内存不足时就会进行回收这些对象的内存。软引用可用来实现内存敏感的高速缓存
(3) 弱引用
具有比软引用更短的生命周期,在垃圾回收器线程扫描它所管辖的内存区域时,一旦有弱引用,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器时一个优先级很低的线程,因此不一定会发现那些只具有弱引用的对象
(4)虚引用
顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速JVM对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
100)其他
(16)分类清晰的简单面试题 https://juejin.im/entry/5838f9f1128fe1006bdaa456
(17)tcp粘包 https://www.cnblogs.com/kex1n/p/6502002.html
(18)lru cache的算法实现 https://www.cnblogs.com/lzrabbit/p/3734850.html
(19)单点登录sso http://www.cnblogs.com/ywlaker/p/6113927.html