一 Zookeeper是什么?
服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,那么这些信息如何推送到各个节点?并且保证信息的一致性和可靠性?我们知道分布式协调服务很难正确无误地实现, 因为他们很容易在竞争条件和死锁上犯错误。
引用官方的说法:“Zookeeper是一个高性能的开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如同步,配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型
二 Zookeeper总体结构
1 结构图
Zookeeper服务自身组成一个集群(2n+1个服务允许n个失效)。Zookeeper服务有两个角色,一个是leader,负责写服务和数据同步,剩下的是follower,提供读服务,leader失效后会在follower中重新选举新的leader。
Zookeeper逻辑图如下,
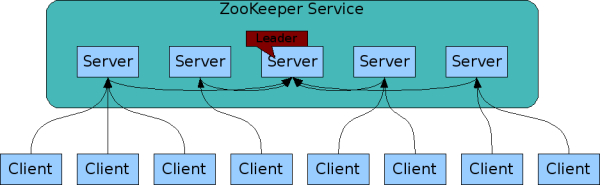

- 客户端可以连接到每个server,每个server的数据完全相同。
- 每个follower都和leader有连接,接受leader的数据更新操作。
- Server记录事务日志和快照到持久存储。
- 大多数server可用,整体服务就可用。
2 Zookpeeper Server 节点的数目
3 Observer节点
3.3.0 以后 版本新增角色Observer
增加原因:
Zookeeper需保证高可用和强一致性;
当集群节点数目逐渐增大为了支持更多的客户端,需要增加更多Server,然而Server增多,投票阶段延迟增大,影响性能。为了权衡伸缩性和高吞吐率,引入Observer:
Observer不参与投票;
Observers接受客户端的连接,并将写请求转发给leader节点;
加入更多Observer节点,提高伸缩性,同时不影响吞吐率。
4 Zookeeper写流程
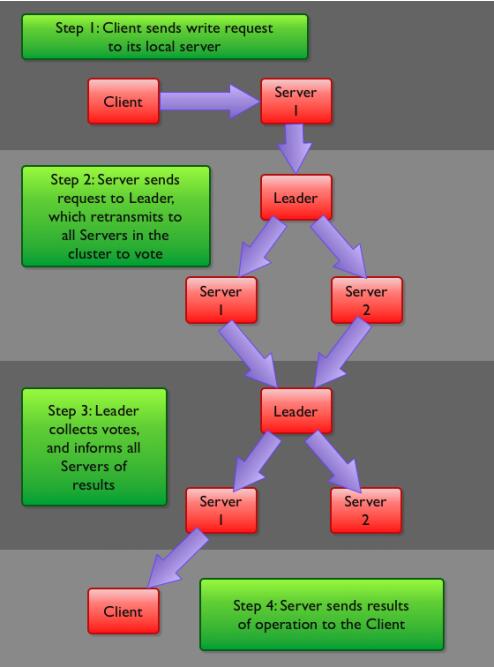
客户端首先和一个Server或者Observe(可以认为是一个Server的代理)通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其他Server,Server在接收到写请求后写入数据并响应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,响应Client。
三 安装和配置
下载zookeeper的安装包解压以后,进入conf子目录,创建zoo.cfg(这个若是参数不清楚可以参考conf目录下自带的zoo_sample.cfg文件)
tickTime=2000 dataDir=/home/balfish/zookeeper clientPort=2181
参数说明:
- tickTime: zookeeper中使用的基本时间单位, 毫秒值.
- dataDir: 数据目录. 可以是任意目录.
- dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置.
- clientPort: 监听client连接的端口号.
至此,zookeeper的单机模式已经配置好了,启动server需要运行如下:
xxx/bin/zkServer.sh start
不加start会报错提示你可以加的命令
Usage: ./zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
比如status查看状态等等
成功了的话大致打印如下的信息:
balfish@balfish-Latitude-E5440:~/下载/zookeeper-3.4.5/bin$ ./zkServer.sh start JMX enabled by default Using config: /home/balfish/下载/zookeeper-3.4.5/bin/../conf/zoo.cfg Starting zookeeper ... already running as process 6083.
也可以通过netstat -anp | grep 2181来看一看tcp状态是 ESTABLISHED 还是 TIME——WAIT 神马的
之后便可以启动client连接server进行测试了
bin/zkCli.sh
打印下面这一大堆就成功了
Connecting to localhost:2181 2015-10-09 17:11:56,858 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT 2015-10-09 17:11:56,862 [myid:] - INFO [main:Environment@100] - Client environment:host.name=balfish-Latitude-E5440 2015-10-09 17:11:56,862 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_40 2015-10-09 17:11:56,863 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2015-10-09 17:11:56,863 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/home/balfish/Download/jdk1.7.0_40/jre 2015-10-09 17:11:56,864 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/balfish/下载/zookeeper-3.4.5/bin/../build/classes:/home/balfish/下载/zookeeper-3.4.5/bin/../build/lib/*.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../lib/slf4j-api-1.6.1.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../lib/netty-3.2.2.Final.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../lib/log4j-1.2.15.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../lib/jline-0.9.94.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../zookeeper-3.4.5.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../src/java/lib/*.jar:/home/balfish/下载/zookeeper-3.4.5/bin/../conf: 2015-10-09 17:11:56,864 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2015-10-09 17:11:56,865 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2015-10-09 17:11:56,865 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2015-10-09 17:11:56,866 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2015-10-09 17:11:56,867 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2015-10-09 17:11:56,867 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.13.0-65-generic 2015-10-09 17:11:56,867 [myid:] - INFO [main:Environment@100] - Client environment:user.name=balfish 2015-10-09 17:11:56,868 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/balfish 2015-10-09 17:11:56,868 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/balfish/下载/zookeeper-3.4.5/bin 2015-10-09 17:11:56,870 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@7b238fa5 Welcome to ZooKeeper! 2015-10-09 17:11:56,892 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@966] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2015-10-09 17:11:56,897 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@849] - Socket connection established to localhost/127.0.0.1:2181, initiating session JLine support is enabled 2015-10-09 17:11:56,914 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1207] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x1504bdec2a90000, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null
四 伪集群模式
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例.
将zookeeper的目录再拷贝2份
|--zookeeper0
|--zookeeper1
|--zookeeper2
更改zookeeper0/conf/zoo.cfg文件为:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/home/balfish/zookeeper clientPort=4180 server.0=127.0.0.1:8880:7770 server.1=127.0.0.1:8881:7771 server.2=127.0.0.1:8882:7772
新增了几个参数, 其含义如下:
- initLimit: 初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s.
- syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4s.
- server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 由于配置的是伪集群模式, 所以各个server的B, C参数必须不同.
参照zookeeper0/conf/zoo.cfg, 配置zookeeper1/conf/zoo.cfg, 和zookeeper2/conf/zoo.cfg文件. 只需更改dataDir, clientPort参数即可.
在之前设置的dataDir中新建myid文件, 写入一个数字, 该数字表示这是第几号server. 该数字必须和zoo.cfg文件中的server.X中的X一一对应.
/home/balfish/zookeeper0/myid文件中写入0,/home/balfish/zookeeper1/myid文件中写入1, /home/balfish/zookeeper2/myid文件中写入2.
分别进入/Users/apple/zookeeper0/bin, /Users/apple/zookeeper1/bin, /Users/apple/zookeeper2/bin三个目录, 启动server.
任意选择一个server目录, 启动客户端:
bin/zkCli.sh -server localhost:4180
五 集群模式
集群模式的配置和伪集群基本一致.
由于集群模式下, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样.
下面是一个示例:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/home/zookeeper clientPort=4180 server.43=10.1.39.43:2888:3888 server.47=10.1.39.47:2888:3888 server.48=10.1.39.48:2888:3888
示例中部署了3台zookeeper server, 分别部署在10.1.39.43, 10.1.39.47, 10.1.39.48上. 需要注意的是, 各server的dataDir目录下的myid文件中的数字必须不同.10.1.39.43 server的myid为43, 10.1.39.47 server的myid为47, 10.1.39.48 server的myid为48.
六 原理详究
Zookeeper利于分布式系统开发,它能让分布式系统更加健壮和高效。它的主要优点有:
- zookeeper是一个精简的文件系统。这点它和hadoop有点像,但是zookeeper这个文件系统是管理小文件的,而hadoop是管理超大文件的。
- zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布式队列、分布式锁以及一组同级节点的“领导者选举”算法。
- zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题。
- zookeeper采用了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制,让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系。
- zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度。
- zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图所示:
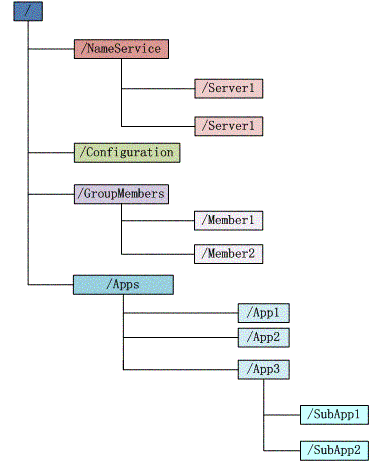
Zookeeper 这种数据结构有如下这些特点:
- 每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,通过心跳来保持连接
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
四种类型的znode:
- PERSISTENT-持久化目录节点。客户端与zookeeper断开连接后,该节点依旧存在
- PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点。客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- EPHEMERAL-临时目录节点。客户端与zookeeper断开连接后,该节点被删除
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点。客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
七 ZooKeeper Client API
ZooKeeper Client Library提供了丰富直观的API供用户程序使用,下面是一些常用的API:
- create(path, data, flags): 创建一个ZNode, path是其路径,data是要存储在该ZNode上的数据,flags常用的有: PERSISTENT, PERSISTENT_SEQUENTAIL, EPHEMERAL, EPHEMERAL_SEQUENTAIL
- delete(path, version): 删除一个ZNode,可以通过version删除指定的版本, 如果version是-1的话,表示删除所有的版本
- exists(path, watch): 判断指定ZNode是否存在,并设置是否Watch这个ZNode。这里如果要设置Watcher的话,Watcher是在创建ZooKeeper实例时指定的,如果要设置特定的Watcher的话,可以调用另一个重载版本的exists(path, watcher)。以下几个带watch参数的API也都类似
- getData(path, watch): 读取指定ZNode上的数据,并设置是否watch这个ZNode
- setData(path, watch): 更新指定ZNode的数据,并设置是否Watch这个ZNode
- getChildren(path, watch): 获取指定ZNode的所有子ZNode的名字,并设置是否Watch这个ZNode
- sync(path): 把所有在sync之前的更新操作都进行同步,达到每个请求都在半数以上的ZooKeeper Server上生效。path参数目前没有用
- setAcl(path, acl): 设置指定ZNode的Acl信息
- getAcl(path): 获取指定ZNode的Acl信息
八 ZooKeeper特点
1 最终一致性:为客户端展示同一视图,这是zookeeper最重要的功能。
2 可靠性:如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3 实时性:Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 等待无关(wait-free):慢的或者失效的client不干预快速的client的请求。
5 原子性:更新只能成功或者失败,没有中间状态。
6 顺序性:所有Server,同一消息发布顺序一致。
用到Zookeeper的系统
(1) HDFS中的HA方案
(2) YARN的HA方案
(3) HBase:必须依赖Zookeeper,保存了Regionserver的心跳信息,和其他的一些关键信息。
(4) Flume:负载均衡,单点故障
九 Zookeeper的应用场景
1、命名服务
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
2、配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。

3、集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知,新机器加入也是类似。
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。

4、分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。厕所有言:来也冲冲,去也冲冲,用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
5、队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
6、负载均衡
这里说的负载均衡是指软负载均衡。在分布式环境中,为了保证高可用性,通常同一个应用或同一个服务的提供方都会部署多份,达到对等服务。而消费者就须要在这些对等的服务器中选择一个来执行相关的业务逻辑,其中比较典型的是消息中间件中的生产者,消费者负载均衡。
7、分布式通知/协调
ZooKeeper中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能够收到通知,并作出相应处理。
关于paxos的算法可以看下 https://www.zhihu.com/question/19787937/answer/107750652