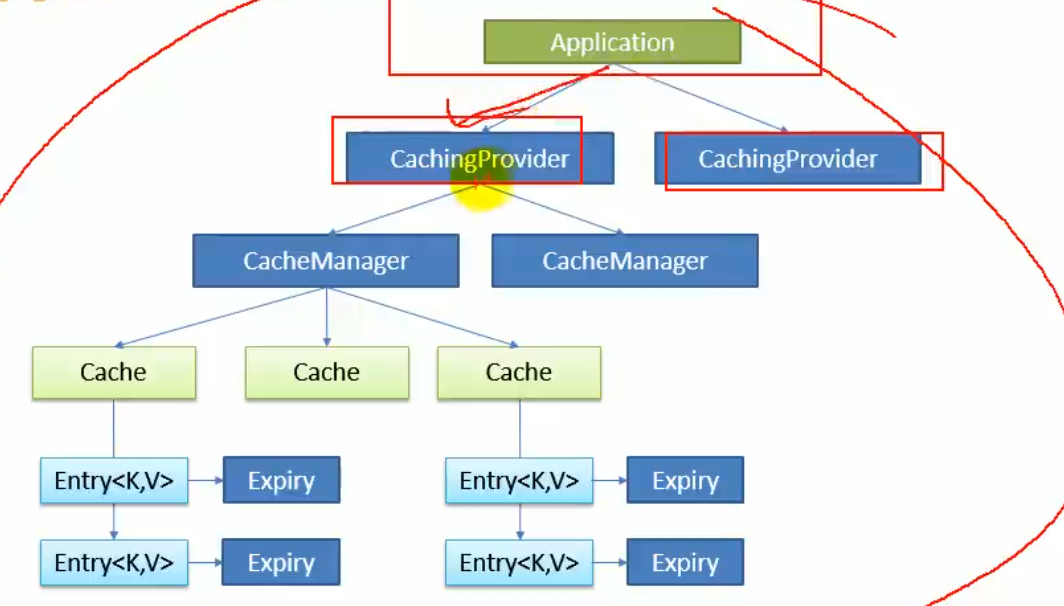
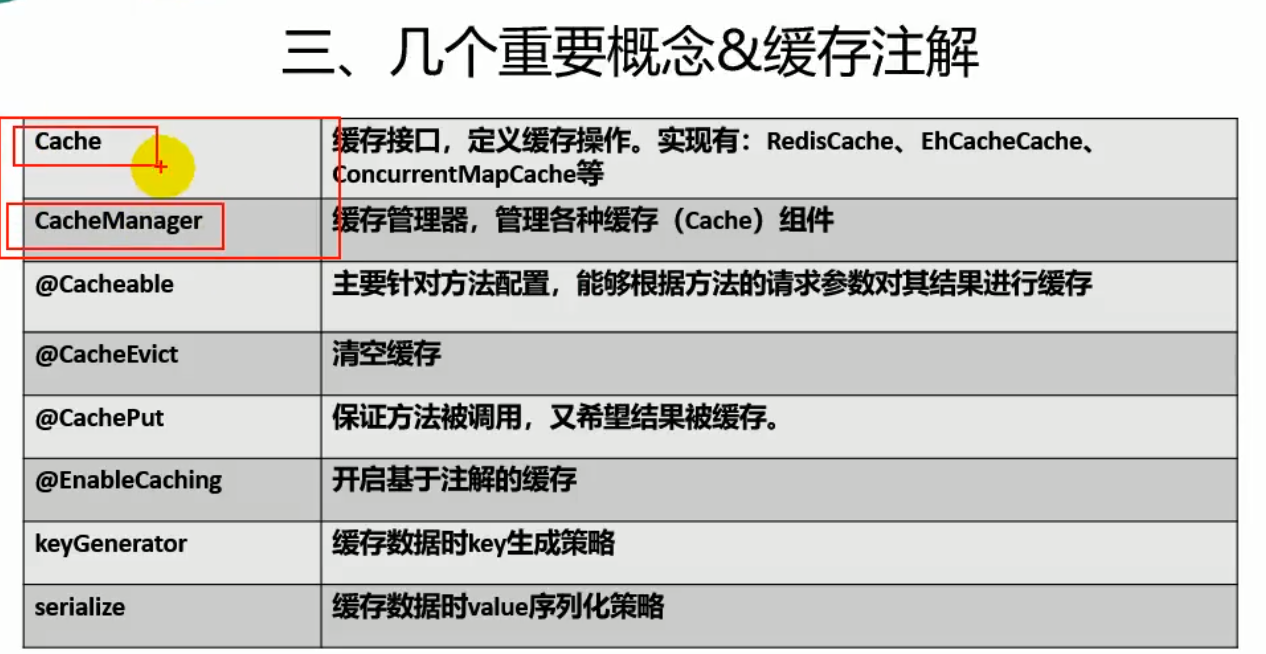
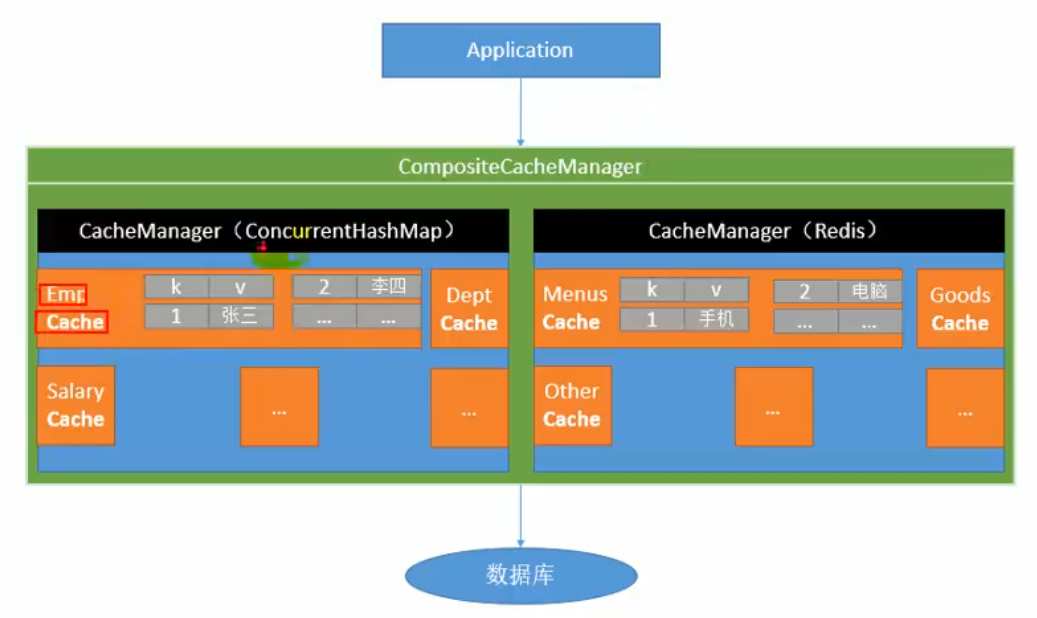
1、缓存

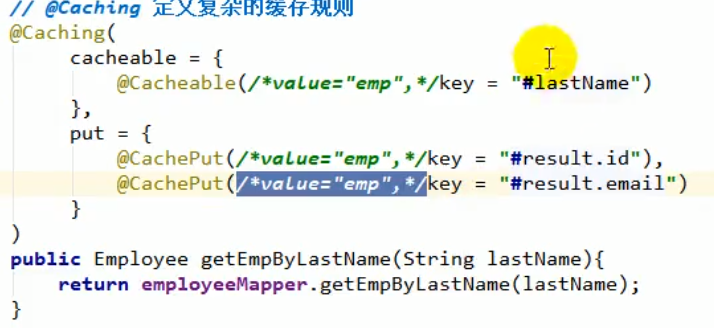
@Cachable:
value(): 表明缓存的名字,相当于与别的域区分。可以指定多个区域,同时缓存进这些区域。
key:存储的键,


0 = "org.springframework.boot.autoconfigure.cache.GenericCacheConfiguration"
1 = "org.springframework.boot.autoconfigure.cache.JCacheCacheConfiguration"
2 = "org.springframework.boot.autoconfigure.cache.EhCacheCacheConfiguration"
3 = "org.springframework.boot.autoconfigure.cache.HazelcastCacheConfiguration"
4 = "org.springframework.boot.autoconfigure.cache.InfinispanCacheConfiguration"
5 = "org.springframework.boot.autoconfigure.cache.CouchbaseCacheConfiguration"
6 = "org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration"
7 = "org.springframework.boot.autoconfigure.cache.CaffeineCacheConfiguration"
8 = "org.springframework.boot.autoconfigure.cache.SimpleCacheConfiguration"
9 = "org.springframework.boot.autoconfigure.cache.NoOpCacheConfiguration"

运行流程:


@CachePut:先执行方法,再更新缓存。
springboot 方法内部调用注解缓存方法无效的问题
使用工具类处理调用 直接调用就不会走代理了 ???? 方法调用不会直接走aop代理,不能直接用@Cachable


使用json序列化时,除了redistemplate, RedisCachemanager也要自定义。
@Bean//自定义cacheManager public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory){ RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig() //.entryTtl(this.timeToLive) .serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(keySerializer())) .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(valueSerializer())) .disableCachingNullValues(); RedisCacheManager redisCacheManager = RedisCacheManager.builder(connectionFactory) .cacheDefaults(config) .transactionAware() .build(); log.debug("自定义RedisCacheManager加载完成"); return redisCacheManager; }
整合shiro时必须要使用(在自定义realm中)
@Autowired @Lazy private UserService userService;
https://blog.csdn.net/gnail_oug/article/details/80706205。使用shiro时,shiro加载很早,导致spring容器还没对service进行代理就实例化了。使用lazy注解来延迟加载即可。@Transxtional等也会失效。
redis缓存击穿:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
1、设置热点数据永远不过期。
2、接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
4、加入互斥锁,只有一个线程进行访问数据库。
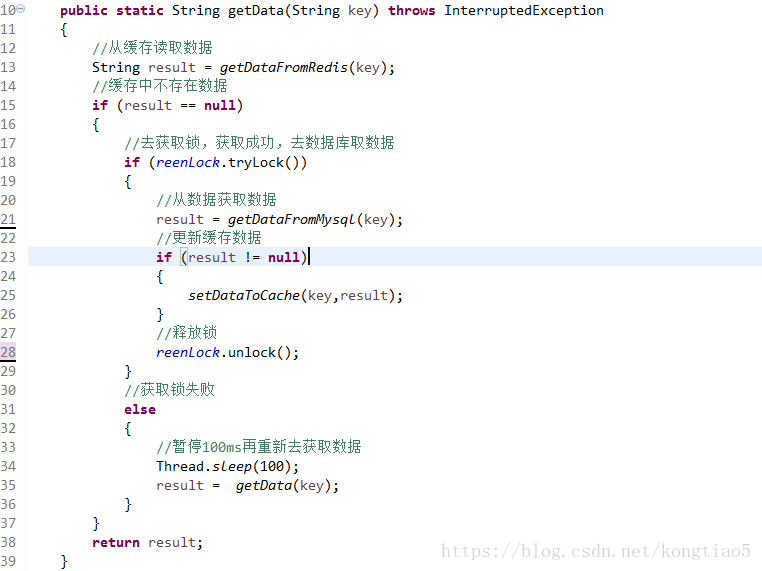
redis缓存穿透:
是指在缓存及数据库中均找不到数据,严重可能导致数据库无法响应。
解决方案:对输入查询类型进行判断,防止明显不正确的类型进入数据库。
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用,添加时需要将返回的key与数据库中的比较)。这样可以防止攻击用户反复用同一个id暴力攻击
https://blog.csdn.net/qq_39513430/article/details/107930471
布隆过滤器简单使用
缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
Redis实现分布式锁:
一、什么是分布式锁?
要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。
线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
进程锁:为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
分布式锁:当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
二、分布式锁的使用场景。
线程间并发问题和进程间并发问题都是可以通过分布式锁解决的,但是强烈不建议这样做!因为采用分布式锁解决这些小问题是非常消耗资源的!分布式锁应该用来解决分布式情况下的多进程并发问题才是最合适的。
有这样一个情境,线程A和线程B都共享某个变量X。
如果是单机情况下(单JVM),线程之间共享内存,只要使用线程锁就可以解决并发问题。
如果是分布式情况下(多JVM),线程A和线程B很可能不是在同一JVM中,这样线程锁就无法起到作用了,这时候就要用到分布式锁来解决。
三、分布式锁的实现(Redis)
分布式锁实现的关键是在分布式的应用服务器外,搭建一个存储服务器,存储锁信息,这时候我们很容易就想到了Redis。首先我们要搭建一个Redis服务器,用Redis服务器来存储锁信息。
在实现的时候要注意的几个关键点:
1、锁信息必须是会过期超时的,不能让一个线程长期占有一个锁而导致死锁;
2、同一时刻只能有一个线程获取到锁。
几个要用到的redis命令:
setnx(key, value):“set if not exits”,若该key-value不存在,则成功加入缓存并且返回1,否则返回0。
get(key):获得key对应的value值,若不存在则返回nil。
getset(key, value):先获取key对应的value值,若不存在则返回nil,然后将旧的value更新为新的value。
expire(key, seconds):设置key-value的有效期为seconds秒。
热点Key处理:
https://blog.csdn.net/fujiandiyi008/article/details/90285719?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control
redis事务:
为什么 Redis 不支持回滚(roll back)
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
redis数据类型
String 最大512mb get set
hash: 存储对象很方便, lpush.rpush lpop rpop
set :无序,唯一,使用hash算法实现,查找O(1)。 sadd smembers sinter(求交集)
zset:有序集合,按照分数排序,分数可以重复,元素内容不可以。 zadd zrange ...wothscores(连同分数查询)
redis键要求:

redis所有值类型:

hyperLogLogs:可以计算一个集合的基数数量,但不会保存集合元素。
事务、管道、集群、主从复制,持久化到硬盘。一致性hash,读写分离
一致性hash原理:
https://www.jianshu.com/p/528ce5cd7e8f
Redis集群方式
https://www.cnblogs.com/runnerjack/p/10269277.html
RDB与aof
https://www.cnblogs.com/immer/p/9544176.html
https://www.cnblogs.com/guanghe/p/9122684.html
缺点
https://www.cnblogs.com/guanghe/p/9122684.html
springboot消息:

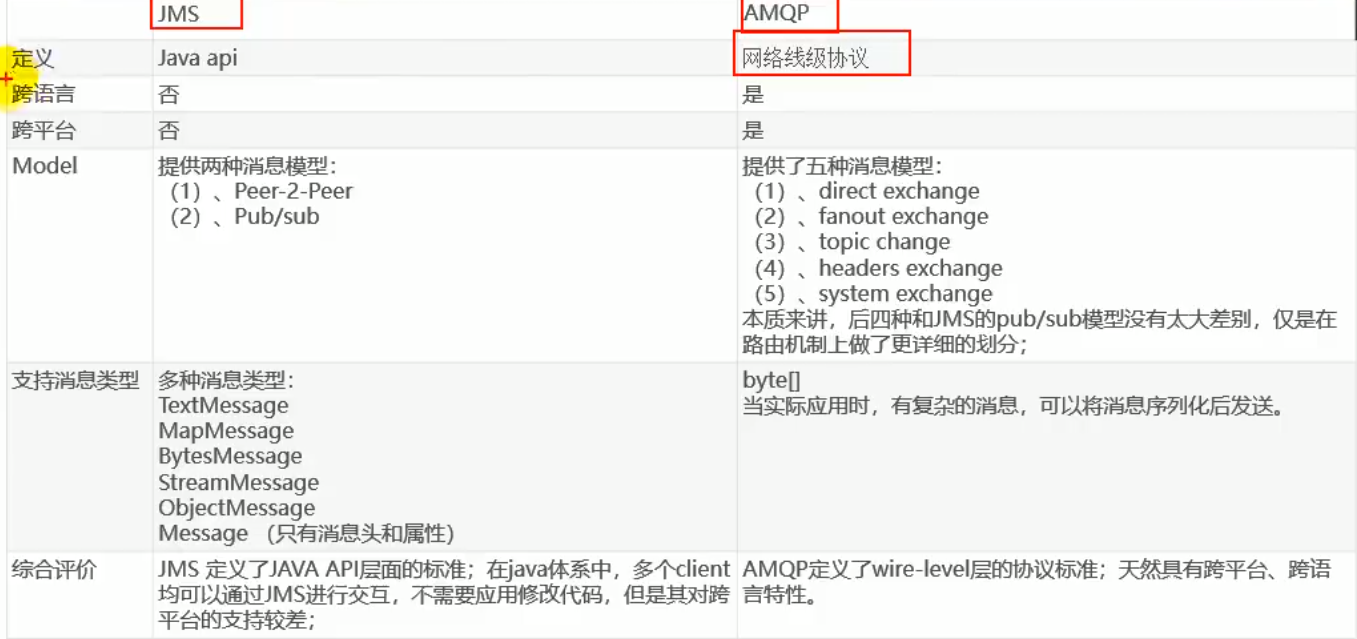

Rabbitmq:


RabbitMq运行机制
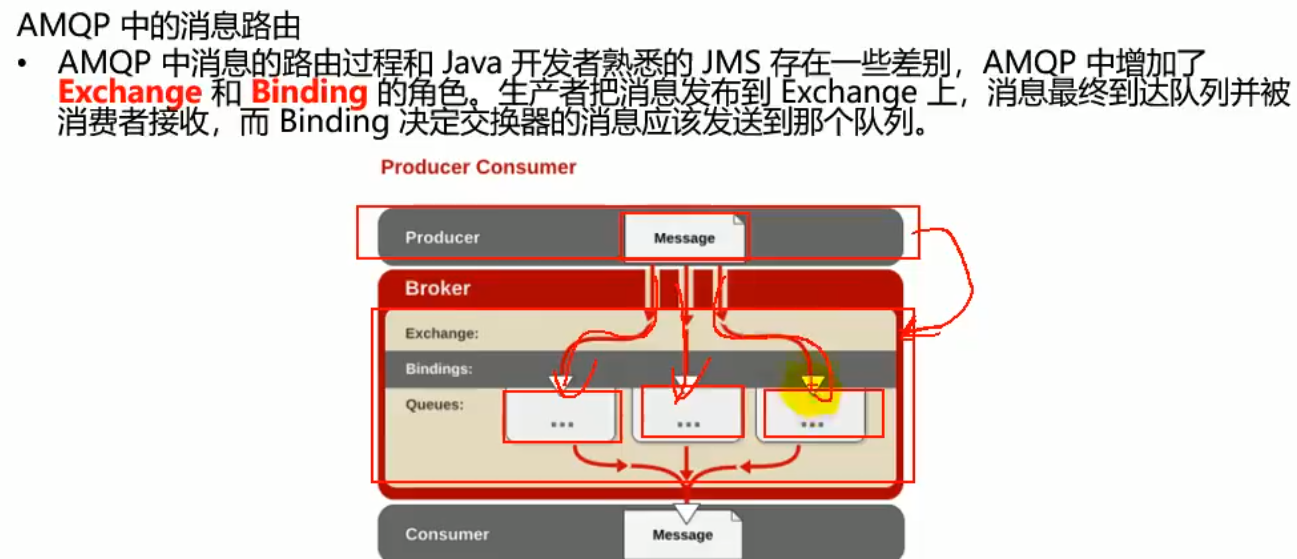


rabbitmq自动配置:
rabbitmq;连接工厂。