目的: 需要搭建一个可以自动监听MySQL数据库的变化,将变化的数据捕获处理,此处只讲解如何自动捕获mysql 中数据的变化
使用的技术
debezium :https://debezium.io/documentation/reference/1.0/connectors/mysql.html
kafka: http://kafka.apache.org/
zookeeper : http://zookeeper.apache.org/
mysql 5.7 https://www.mysql.com/
一、思路
需要一台 Centos 7.x 的虚拟机 ,zk、debezium、kafka、confluent 运行在 虚拟机上 ,mysql 运行在 windows 系统上,虚拟机监听 window 环境下的 mysql 数据变化
二、MySQL 环境准备
首先需要找到 mysql 的配置文件:my.ini ,我的路径是:C:ProgramDataMySQLMySQL Server 5.7 ,因为监听基础是基于 mysql binlog ,需要开启binlog ,添加如下配置
log_bin =D:mysql-binlogmysql-bin binlog_format=Row server-id=223344 binlog_row_image = full expire_logs_days = 10 binlog_rows_query_log_events = on
重启 mysql 服务
net stop mysql57
net start mysql57
此处,MySQL binlog 即开启,可以简单的验证,cmd 窗口 mysql -u root -p 登录 mysql
show binary logs;

可以看到文件内容,即mysql 变化的二进制文件。到此处,MySQL准备就绪。
二、zookeeper 、 kafka 准备
下载 zookeeper-3.4.14.tar.gz 、kafka_2.12-2.2.0.tar
mkdir -p /usr/local/software/zookeeper mkdir -p /usr/local/software/kafka mkdir -p /usr/local/software/confluent
准备好路径,并将安装包移入该目录,并解压
mv zookeeper-3.4.14.tar.gz /usr/local/software/zookeeper
mv kafka_2.12-2.2.0.tar
进入 zookeeper /usr/local/software/zookeeper/zookeeper-3.4.14/conf目录,修改 zoo.cfg (原名 zoo_sample.cfg)内容
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
进入 dataDir 目录,创建文件 myid ,并添加内容: 1
此处,zk 的配置修改结束。开启配置 kafka 路径是:/usr/local/software/kafka/kafka_2.12-2.2.0/config, 修改 server.properties
broker.id=1 listeners=PLAINTEXT://192.168.91.25:9092 advertised.listeners=PLAINTEXT://192.168.91.25:9092 log.dirs=/opt/data/kafka-logs host.name=192.168.91.25 zookeeper.connect=localhost:2181
三、debezium配置
此处需要 debezium connector 对 mysql 的 jar 包,下载地址:https://debezium.io/releases/1.0/

将下载好的 plugs 上传到虚拟机,解压后名称是: debezium-connector-mysql
移动到: /usr/local/share/kafka/plugins 目录下,如果没有该目录则手动创建

依赖的 jar 包下载好后,配置 kafka 目录中conf connector
目录: /usr/local/software/kafka/kafka_2.12-2.2.0/conf/connect-standalone.properties
bootstrap.servers=本机IP:9092 plugin.path=/usr/local/share/kafka/plugins
此外,在kafka 根目录下 创建文件: msyql.properties ,内容
name=mysql connector.class=io.debezium.connector.mysql.MySqlConnector database.hostname=192.168.3.125 database.port=3306 database.user=root database.password=123456 database.server.id=112233 database.server.name=test database.whitelist=orders,users database.history.kafka.bootstrap.servers=192.168.91.25:9092 database.history.kafka.topic=history.test include.schema.changes=true include.query=true # options: adaptive_time_microseconds(default)adaptive(deprecated) connect() time.precision.mode=connect # options: precise(default) double string decimal.handling.mode=string # options: long(default) precise bigint.unsigned.handling.mode=long
四、启动服务
01.启动zk
cd /usr/local/software/zookeeper/zookeeper-3.4.14
zkServer.sh start

02.启动kafka
cd /usr/local/software/kafka/kafka_2.12-2.2.0
./bin/kafka-server-start.sh -daemon config/server.properties
03.启动kafka connector
cd /usr/local/software/kafka/kafka_2.12-2.2.0
./bin/connect-standalone.sh config/connect-standalone.properties mysql.properties
04.查看 topic ,在新的端口查看
./bin/kafka-topics.sh --list --zookeeper localhost:2181
五、指定监听的数据库/表
在 postman 中模拟 post 请求,以 json 格式传递参数:表示 监听 shiro数据库
{ "name": "shiro", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.hostname": "192.168.3.125", "database.port": "3306", "database.user": "root", "database.password": "123456", "database.server.id": "184054", "database.server.name": "my", "database.whitelist": "shiro", "database.history.kafka.bootstrap.servers": "192.168.91.25:9092", "database.history.kafka.topic": "history.shiro", "include.schema.changes": "true" }}
重新查看topic
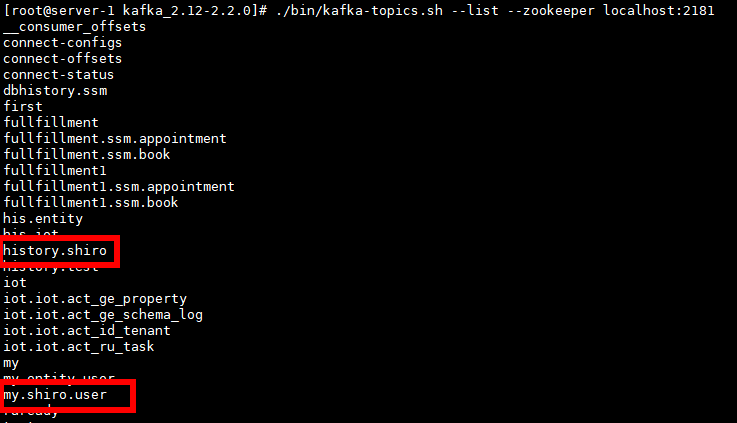
在新端口启动 kafka 消费者,消费my.shiro.user
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my.shiro.user --from-beginning
Java客户端消费者代码


package kafka; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Properties; /** * Created by baizhuang on 2019/10/25 10:39. */ public class MyConsumer { public static void main(String []args){ //1.创建 kafka 生产者配置信息。 Properties properties = new Properties(); //2.指定 kafka 集群 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.25:9092"); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //key,value 反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.put("group.id","test"); KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(properties); consumer.subscribe(Arrays.asList("my.shiro.user")); while (true) { ConsumerRecords<String, String> consumerRecords = consumer.poll(100); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord.key() + "-----" + consumerRecord.value()); } } } }
Java 客户端生产者代码
package kafka; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; /** * Created by baizhuang on 2019/10/24 16:58. */ public class MyProducer { public static void main(String []args){ //1.创建 kafka 生产者配置信息。 Properties properties = new Properties(); //2.指定 kafka 集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.25:9092"); //3. properties.put("acks","all"); //4.重试次数 properties.put("retries",0); //5.批次大小 properties.put("batch.size",16384); //6.等待时间 properties.put("linger.ms",1); //7.RecordAccumlate 缓冲区大小 properties.put("buffer.memory",33554432); //key ,value 序列化 properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //9.创建生产者 KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties); for(int i=0;i<10;i++){ //10.发送 String key = String.valueOf(i); String value = "第"+key+"条消息"; producer.send(new ProducerRecord<String, String>("mytopic",key,value)); System.out.println("msg:"+i); } producer.close(); } }
启动消费者,修改 shiro 数据库的user 表,Java客户端消费者与 linux 消费者均可动态的显示变化的数据
