Sqoop概述
Sqoop是一款开源的工具,主要用于在Hadoop生态系统(Hadoop、Hive等)与传统的数据库(MySQL、Oracle等)间进行数据的传递,可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
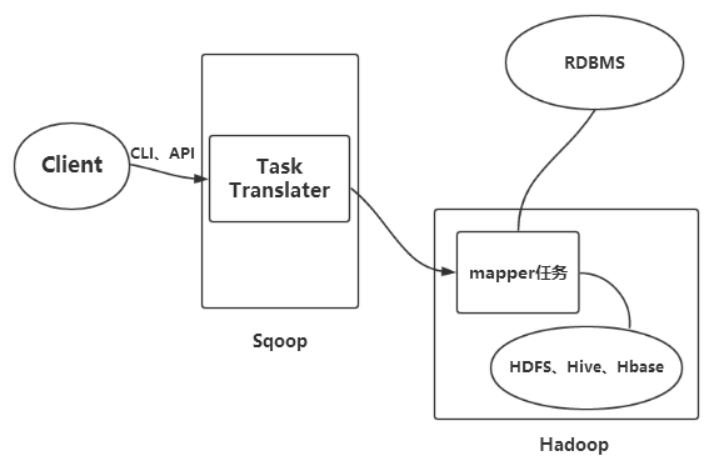
Sqoop导入原理:
在导入开始之前,Sqoop使用JDBC来检查将要导入的表。他检索出表中所有的列以及列的SQL数据类型。这些SQL类型(varchar、integer)被映射到Java数据类型(String、Integer等),在MapReduce应用中将使用这些对应的Java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。Sqoop启动的MapReduce作业用到一个InputFormat,他可以通过JDBC从一个数据库表中读取部分内容。
Hadoop提供的DataDriverDB InputFormat能为查询结果进行划分传给指定个数的map任务。为了获取更好的导入性能,查询会根据一个“划分列”来进行划分。Sqoop会选择一个合适的列作为划分列(通常是表的主键)。在生成反序列化代码和配置InputFormat之后,Sqoop将作业发送到MapReduce集群。Map任务将执行查询并将ResultSet中的数据反序列化到生成类的实例,这些数据要么直接保存在SequenceFile文件中,要么在写到HDFS之前被转换成分割的文本。Sqoop不需要每次都导入整张表,用户也可以在查询中加入到where子句,以此来限定需要导入的记录。
Sqoop导出原理:
Sqoop导出功能的架构与其导入功能非常相似,在执行导出操作之前,Sqoop会根据数据库连接字符串来选择一个导出方法。一般为JDBC。然后,Sqoop会根据目标表的定义生成一个Java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入合适类型的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。